
Reflexion: Language Agents with Verbal Reinforcement Learning
发表时间:2023(NeurIPS 2023)
文章要点:文章提出Reflexion框架,通过交互的方式获得反馈,并变成细致的语言feedback的形式作为下一轮的prompt,以此强化language agents的能力,同时避免了更新大模型的参数。这样的好处有1)轻量,不需要finetune LLM,2)feedback相比一个reward信号更加细致,3)充分利用过去的经验对未来的动作给予指导。缺点在于,很依赖大模型自我评估的能力(have the disadvantages of relying on the power of the LLM’s self-evaluation capabilities (or heuristics) and not having a formal guarantee for success)。
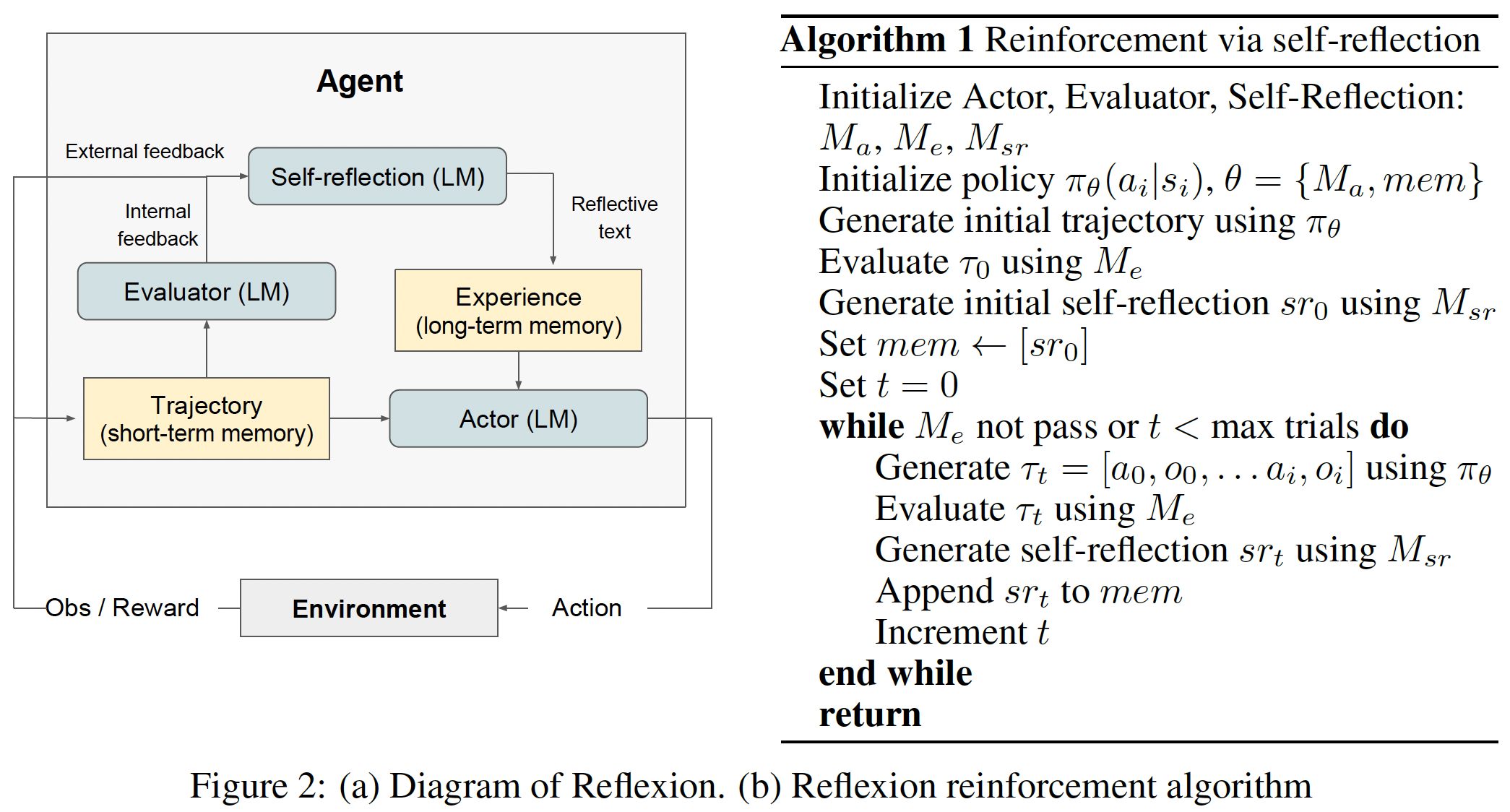
具体的,框架包括三个模型:Actor, Evaluator model, Self-Reflection model。
Actor是一个LLM,用来生成动作。Actor具体可以采用Chain of Thought和ReAct等方式实现。此外,还维护了一个memory用来存储过去的经验作为Actor的prompt。这个memory被称为short-term memory。
Evaluator分析Actor的输出并给轨迹打分(It takes as input a generated trajectory and computes a reward score that reflects its performance within the given task context.)。Evaluator可以是环境准确的反馈(reward functions based on exact match (EM) grading),可以是定义好的函数(pre-defined heuristic functions),也可以是LLM。
Self-reflection是一个LLM,主要作用是将Evaluator的打分转换成更细致的语言反馈(by generating verbal self-reflections to provide valuable feedback for future trials)。同时这个反馈也存到memory中,这个被称为long-term memory.
整个reflexion的过程是一个迭代优化的过程。Actor和环境交互得到轨迹,Evaluator给轨迹打分,Self-reflection分析轨迹和得分并生成语言形式的反馈存到memory里作为下一次迭代的prompt。如此循环下去直到回答正确或者达到最大尝试次数。
下图给了一个具体的例子
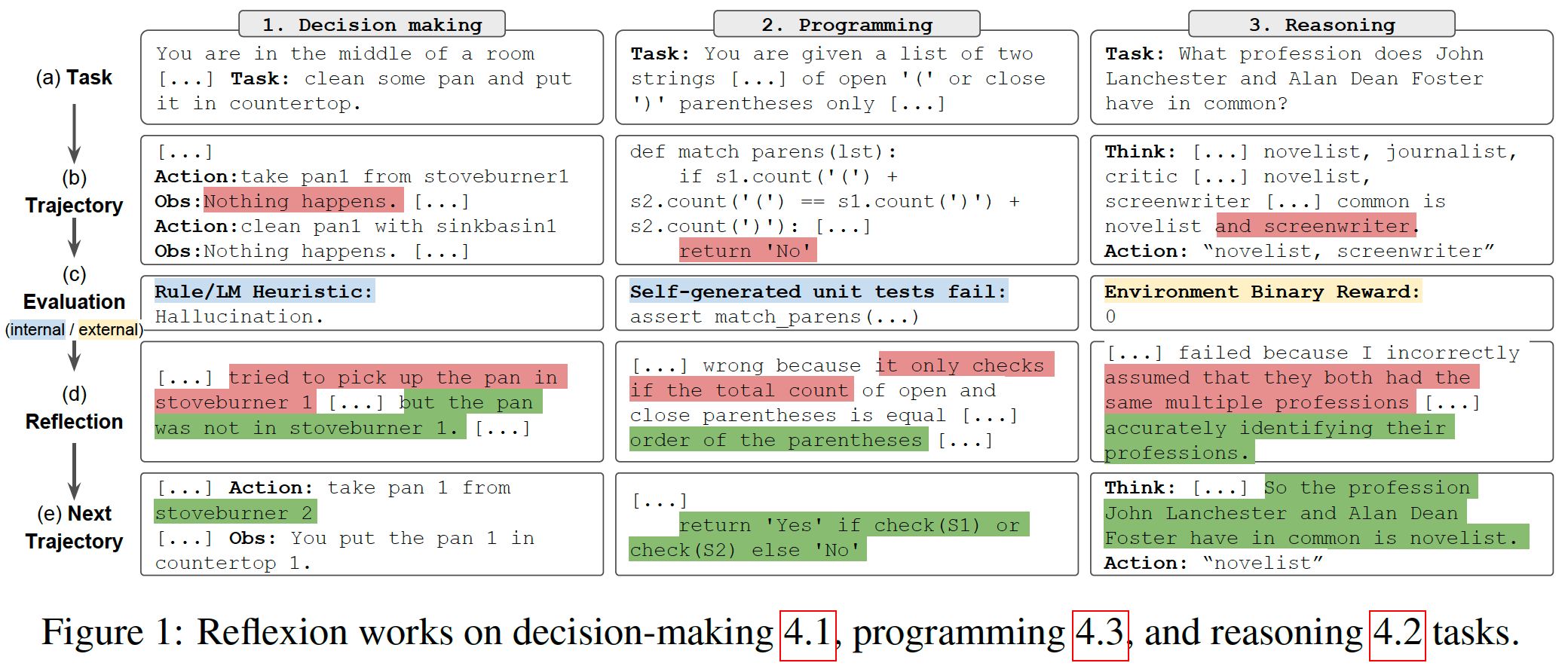
总结:文章写的很清楚了,优点是轻量而且有效,缺点就是比较依赖LLM的能力。感觉这个点是不是可以通过增加一个真正的RL的过程来弥补,可以考虑考虑。
疑问:无。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号