State Distribution-aware Sampling for Deep Q-learning
发表时间:2018(Neural Processing Letters 2019)
文章要点:这篇文章认为之前的experience replay的方法比如PER没有将transition的分布情况考虑在内,于是提出一个新的experience replay的方法,将occurrence frequencies of transitions和uncertainty of state-action values考虑在内。
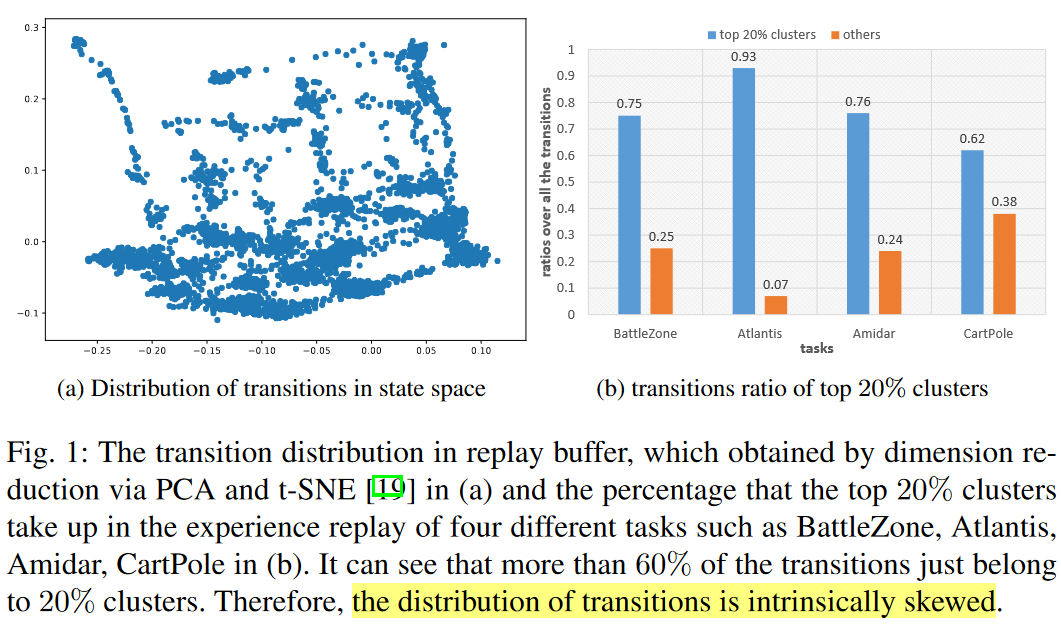
作者的出发点是,agent通常从一些初始状态开始,所以离这些状态越近的状态肯定被探索的越多,这就导致buffer里的状态是skew的,所以直接均匀采样更像是occurrence frequencies-based sampling,对于出现少的状态很少会更新对应的Q(s,a),这就会导致对经常出现的状态更新过多,出现较少的状态更新太少。所以作者用静态哈希表将状态聚类,然后根据类别和每类的样本数定义采样概率

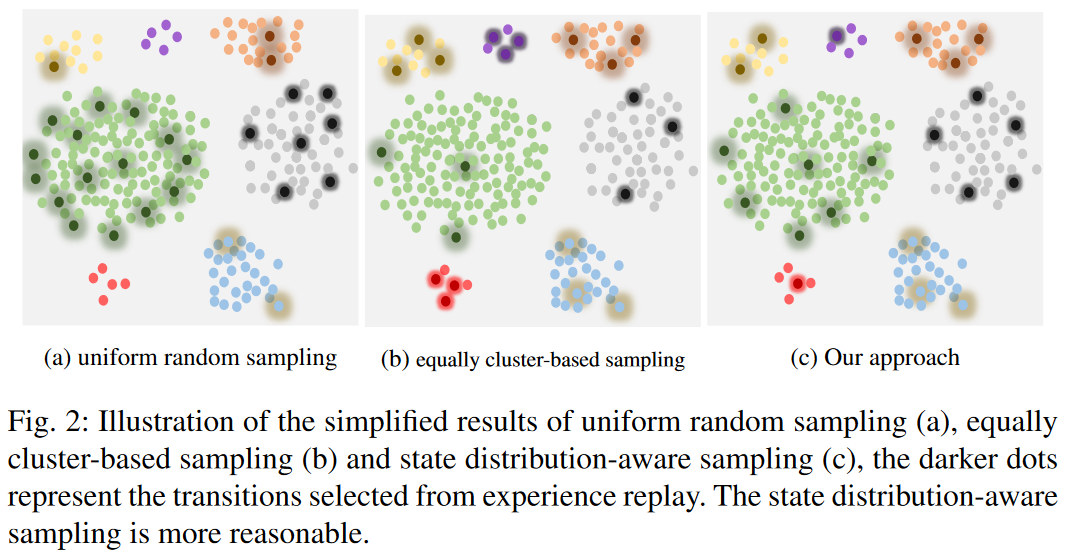
这里第一项就是完全的随机采样,第二项里k指k个类别,\(num_i\)表示样本i所属类别一共有多少个样本。所以第二项里,如果某个类别里的样本很多,那抽到里面某个样本的可能性就小。下图描述了采样的区别,可以看到这种综合加纯随机,同时也考虑了样本分布的概率采样会更加均匀
不过最后效果看起来,没有很大的提升
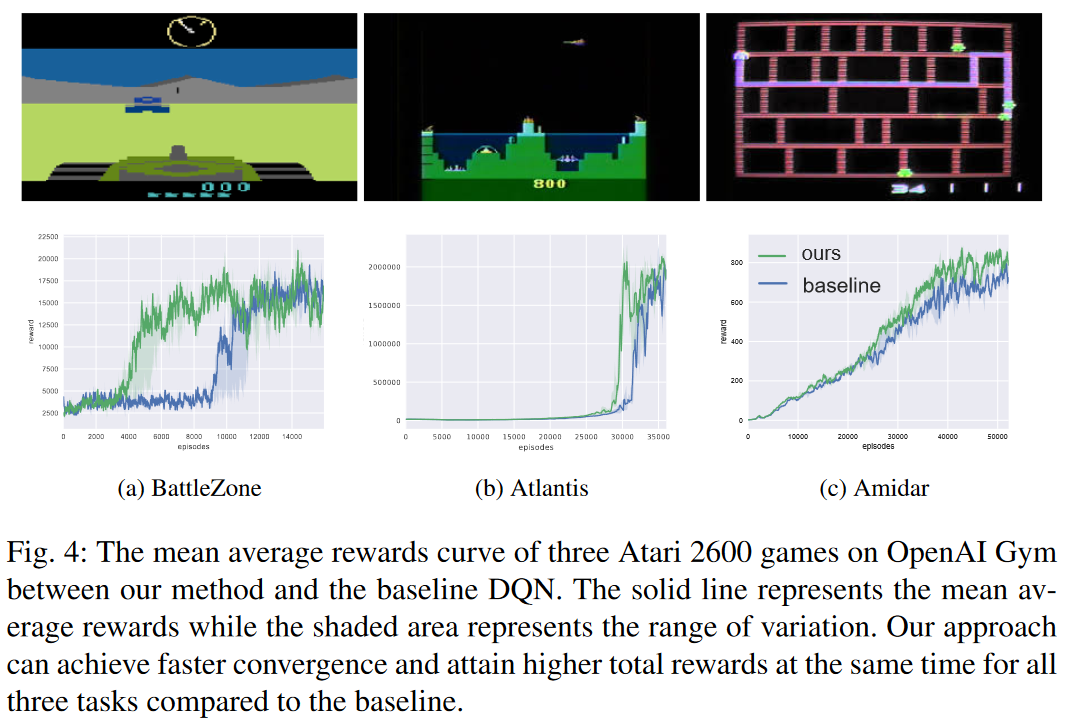
总结:道理上是make sense的,但是结果看起来也不是很明显。
疑问:是不是其实sampling留给大家做的空间已经不大了啊,看了这么多文章,感觉提升都很小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号