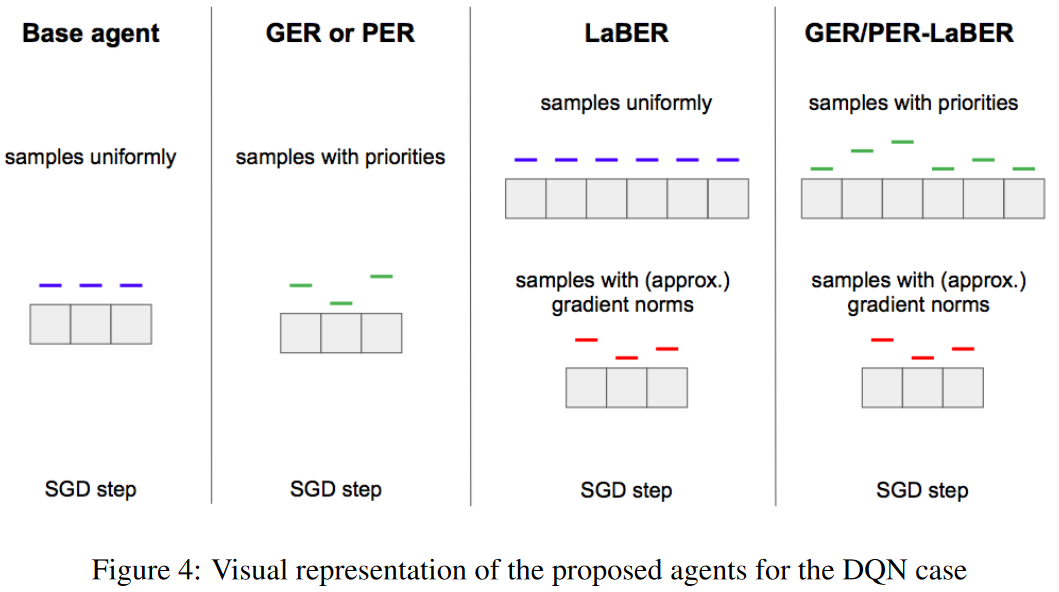
Large Batch Experience Replay
发表时间:2021(ICML 2022)
文章要点:这篇文章把experience replay看做一个通过importance sampling来估计梯度的问题,从理论上推导经验回放的最优采样分布,然后提出LaBER (Large Batch Experience Replay)算法来近似这个采样分布。
非均匀采样mini batch可以看成一个基于replay buffer的importance sampling的问题,梯度估计的方差越小,收敛就会越快。PER就可以看做这样一个算法(PER is a special case of such approximations in the context of ADP, and propose better sampling schemes)。
作者首先推导,更新Q的梯度为

所以这里的关键就是G,作者推出来最大化收敛速度其实就是要最小化一个和G相关的期望项,最后就成了一个和Q的梯度有关的一个权重

PER有效的原因其实就可以认为TD error其实就是一个和Q的梯度有关的权重

PER里面有几个近似,一个是用TD error来近似最优采样分布里的Q的梯度,另一个是PER的估计是outdated,只有样本被采到的时候才会更新,这样来看PER的方差是没有被控制住的。于是作者提出两个改进Gradient Experience Replay(GER),直接用Q的梯度的范数作为权重,不过这个梯度也是outdated的
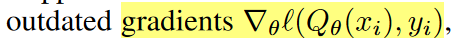
另一个改进是Large Batch Experience Replay(LaBER),先采样一个大的batch,计算importance sampling,再down sample成一个方差最小的mini batch来近似最优采样分布。这个时候的梯度估计就是最新的


有了batch之后,更新的加权作者也试了几种,
直接归一化
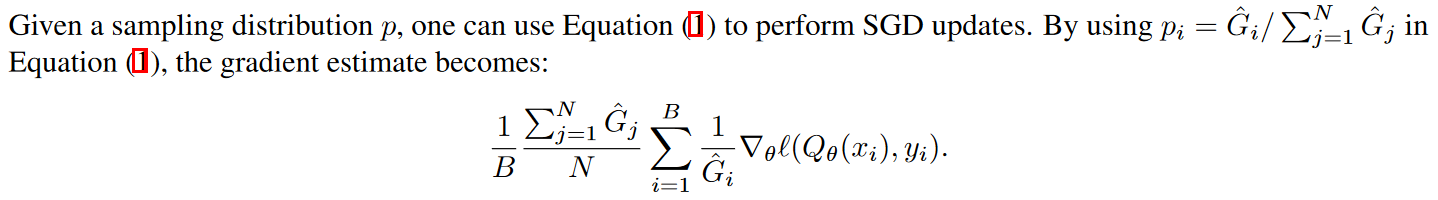
用大batch的mean归一化
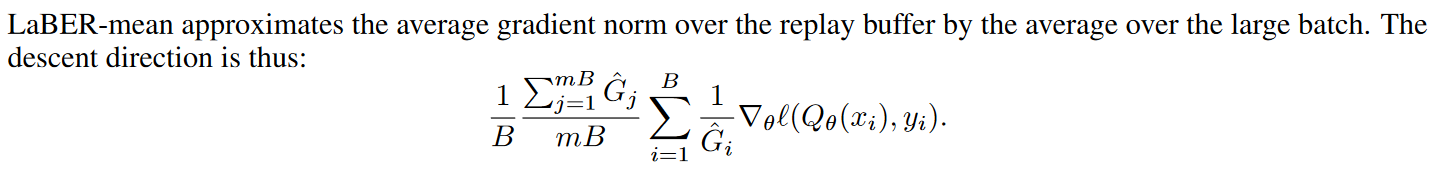
不归一化,直接全部放到learning rate里
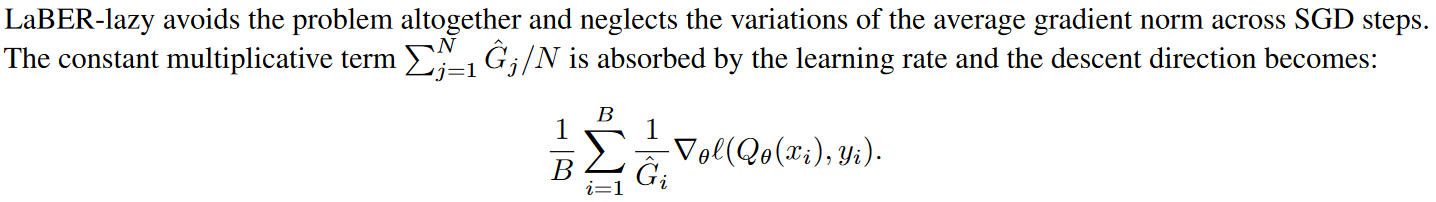
用最大权重来归一化

从效果上看,mean要好些。最后效果如下,
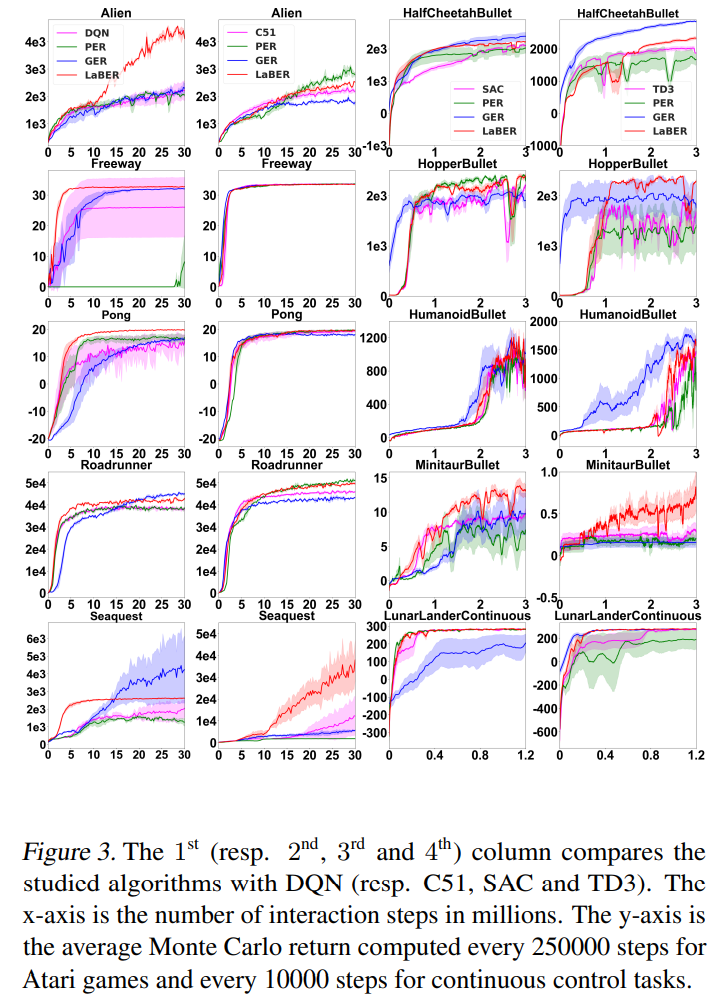
总结:看起来在某些环境上是有效果的。作者开源了代码,可以试试。
疑问:无。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号