Experience Replay with Likelihood-free Importance Weights
发表时间:2020
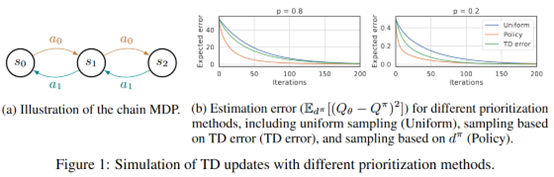
文章要点:这篇文章提出LFIW算法用likelihood作为experience的采样权重(likelihood-free density ratio estimator),reweight experiences based on their likelihood under the stationary distribution of the current policy,这种方式鼓励让经常访问的状态有更小的误差估计(encourage small approximation errors on the value function over frequently encountered states)。
大概思路是维护两个buffer

Slow replay buffer存所有样本\(d^D\),fast replay buffer存on-policy的样本\(d^\pi\).然后采样基于ratio \(d^\pi (s,a)/d^D (s,a)\),作者如下估计ratio

最后更新为

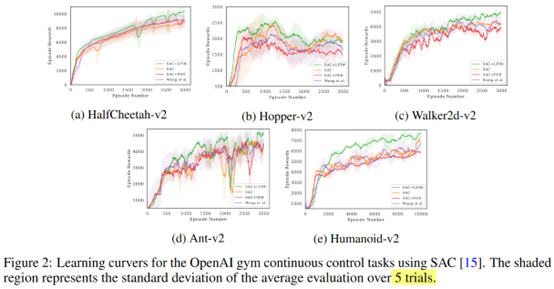
效果上看,在一些环境上是有效果的
总结:思路就是尽量采on-policy的样本,给他们赋予更高的权重。
疑问:其实不是很明白为啥这个ratio会好。
图里看有的效果不如SAC,为啥在table里又是这个方法在所有环境上都好了,统计方法不一样?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号