TOPOLOGICAL EXPERIENCE REPLAY
发表时间:2022(ICLR 2022)
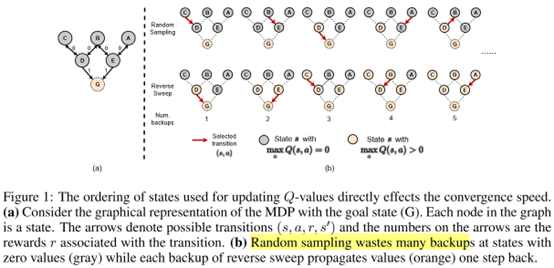
文章要点:这篇文章指出根据TD error来采样是低效的,因为估计TD error的target Q就不准(since a state's correct Q-value preconditions on the accurate successor states' Q-value.)。为了解决这个问题,文章提出Topological Experience Replay (TER),将experience存成一个图结构,然后用breadth-first search从terminal state开始更新(reverse sweep)。为了打破数据之间的相关性,抽取的batch混合了reverse sweep和随机采样。最终在goal-reaching tasks上取得了不错的效果。
具体的,作者用hash table来构建图,先用random projection将状态编码,存成图里的顶点,然后动作为边。然后图是动态更新的,每个step都会把新来的transition构建到图里。
有了图之后就,剩下的就是怎么采样更新。首先有一个terminal states的集合,先从这个集合里采一个子集出来\(v^\prime\),然后再找对应的前一个状态以及动作\(v,a\),凑成一步的transition。然后等这些transition被训练过后,下一次就从\(v\)开始,去找再上一步的状态和动作,凑成一个新的batch,就这样从后往前全部更新一遍。等一轮走完之后,再重复这个过程。另外,因为有的状态可能不能到达terminal state,所以再随机采样一些样本,混合到一起训练(BATCH MIXING),作者用的是TER结合PER,作者是\(\eta\)的PER混合\(1-\eta\)的TER,其中\(\eta\)取0.1,02的时候表现最好。

伪代码如下

总结:也是想说更新顺序非常重要,不过存成图结构感觉有点人工干预过多了,主要的实验环境都是迷宫类型的,可能graph建起来比较简单,因为总的状态数不多,添到图里的时候都会重复,如果是Atari那种,估计完全一样的状态会少很多。
疑问:文章说BATCH MIXING的作用是ensuring those transitions disconnected from terminal states to be updated,会有这样的状态存在吗?更重要的作用会不会是打乱数据的相关性,不然更新会不会出问题?
这里建图的主要目的就是为了合并状态,回溯更新Q。有没有类似的方法,直接在buffer里实现这个更新,不用建图?
文章用了一个random projection的方式来做hash,这么做的好处是啥,为什么不用现成的MD5之类的方式?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号