Deep Exploration via Bootstrapped DQN
发表时间:2016(NIPS 2016)
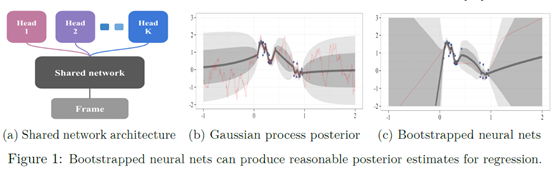
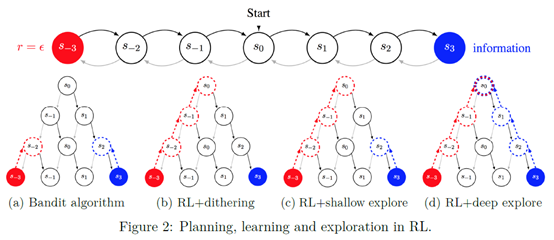
文章要点:这篇文章提出了Bootstrapped DQN算法来做深度探索。作者认为,当前的探索策略比如ϵ-greedy,并没有进行深度探索(temporally-extended (or deep) exploration)。Deep exploration指的是一个探索策略进行多步的探索,而不是像ϵ-greedy那种每步都是一个随机探索,没有连续性(Deep exploration means exploration which is directed over multiple time steps; it can also be called planning to learn or far-sighted exploration)。作者提出,同时训练多个Q网络,可以做到deep exploration。
具体做法就是训练网络的时候,不止一套Q value,而是有K套Q value,然后每个episode都用其中一个Q head来选择动作,相当于用同一个策略来探索这一整局,这样就做到了deep exploration。然后训练的时候,就有放回抽样各个Q head的样本分别训练。
总结:较老的一篇文章了,相当于是ensemble的方式,可能当时比较新颖吧。
疑问:dithering指的啥?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号