Think Too Fast Nor Too Slow: The Computational Trade-off Between Planning And Reinforcement Learning
发表时间:2020(ICAPS: PRL 2020)
文章要点:这篇文章主要探究planning和learning的算力的trade-off,得出的结论是既不能planning太多,也不能planning太少。
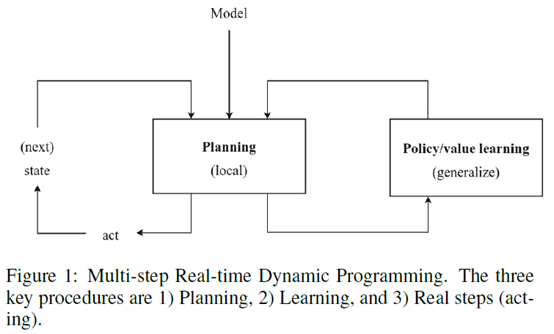
具体的,作者先指出了一类叫multi-step approximate real-time dynamic programming (MSA-RTDP)的算法,这类算法结合了planning和learning,可以认为是planning和reinforcement learning的中间体,像AlphaGo这类算法就属于MSA-RTDP。而planning和learning相结合的算法也可以看作认知心理学里面的dual process theory,也被叫做thinking fast and slow,就是说人类相当于有两个系统,其中learning得到的网络就相当于fast系统,planning就相当于slow系统(fast prediction (System 1) and explicit planning (System 2) in human decision making. This theory, better known as dual process theory, was more recently popularized as‘thinking fast and slow’. System 1 includes fast, reactive, automatic behaviour, much like a neural network prediction, while System 2 includes slow, calculating, effortful decision-making, which bears similarity to local planning.)。
作者通过固定总的计算时间,然后改变MCTS的planning的迭代次数,来看什么时候效果最好。结果如下图
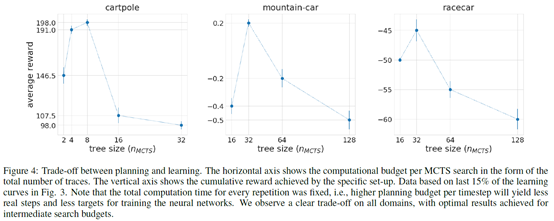
得到的结论是hat optimal performance is achieved for an intermediate search budget。里面的insight就是,如果planning太多,learning太少,就会导致网络拟合不够准确。如果planning太少,learning太多,那么planning提供给learning的信息也不够准,learning也学不好。所以这两是相辅相成的,需要恰到好处。作者给了一个图来解释这个问题
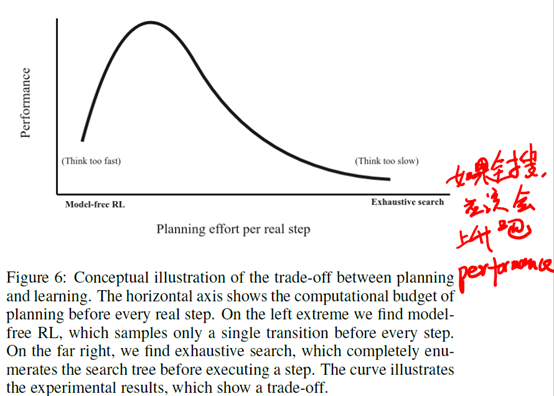
就是说最好的时候是在中间的时候。不过我感觉最右边exhaustive search的performance应该再上去才对,相当于暴力搜索全都搜了,效果肯定不会差吧。
总结:一个可以预料的结论,不过作者做了实验用效果来说话,也是很有利的一个支撑。不过并没有给出一个指导准则,怎么来做这个trade-off。
疑问:无。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号