Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning
发表时间:2014(NIPS 2014)
文章要点:这篇文章主要是测试了Monte-Carlo Tree Search在Atari上的效果,不过并不是结合强化做的,而是先用tree search收集样本,再用神经网络拟合数据训成一个Q网络或者policy网络。得出的结论是比DQN效果好。
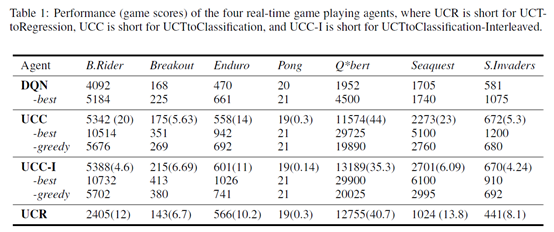
具体的,作者先是直接用MCTS来玩Atari游戏,没有任何训练,通过设置最大深度300和轨迹数量10000,就可以超过DQN了,作者把这个叫做Baseline UCT agent。然后基于Baseline UCT agent收集的数据,训练了UCTtoRegression,UCTtoClassification,UCTtoClassification-Interleaved三个方法。UCTtoRegression就是去训练Q网络,UCTtoClassification就是去训练policy网络,UCTtoClassification-Interleaved就是说MCTS收集一会数据,然后训了网络之后用网络收集一会数据,交替进行。这里的逻辑作者说是让训练的分布和评估的分布更接近,我感觉不是很make sense,简单说来就是之前那种方式有点过拟合,这种方式让训练集和测试集更接近,过拟合就无所谓了(UCTtoClassification-Interleaved agent was designed so that its input distribution during training is more likely to match its input distribution during evaluation and we hypothesized that this would improve performance relative to UCTtoClassification.)。最后结论就是UCTtoClassification比UCTtoRegression效果好,UCTtoClassification-Interleaved 比UCTtoClassification效果好。
总结:之前还很早的一篇文章了,虽然没有在训练RL的过程中结合planning,不过也是MCTS在Atari游戏上的尝试,说明了planning对于这类游戏还是有作用的,甚至不亚于RL。另外,得出的结论说比DQN效果好,也间接说明了DQN对样本的利用效率其实并不高,并没有榨干数据的信息,这也说明了planning还是值得继续研究来提高RL的sample efficiency,以及推理能力。
疑问:无。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号