Model-Based Deep Reinforcement Learning for High-Dimensional Problems, a Survey
发表时间:2020
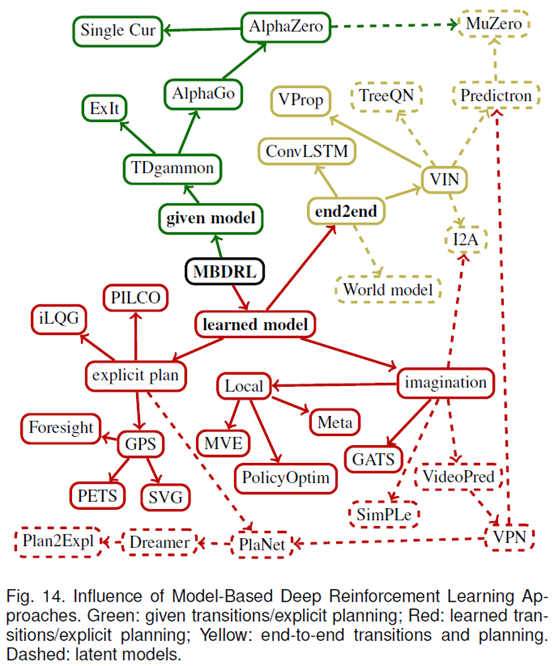
文章要点:这篇文章主要是deep的model based RL的综述,说起来主要的目标就是一句话achieve high predictive power while maintaining low sample complexity. 主要分了三大类using explicit planning on given transitions,using explicit planning on learned
transitions, end-to-end learning of both planning and transitions。前两类很好理解,最后一类就是planning和model一起学,相当于planning的方式也是通过学习得到的,而不是人为给一个planning的方法。然后就分别介绍了这些类别下的算法。主要的问题还是集中于如何学model,如何用model,如何和model free方法结合。最后文章还说了几个benchmark环境(1) puzzles and mazes, (2) Atari arcade games such as Pac-Man, (3) board games such as Go and chess, (4) real-time strategy games such as StarCraft, and (5) simulated robotics tasks such as Half-Cheetah. 全文结束。
总结:一篇比较短的综述,大致框架和之前了解的model based方法一致,具体细节的话还是要看文章里提到的paper才行。
疑问:Atari算RTS吗?
这里的value iteration我就感觉有点奇怪,仔细想好像也是这么回事,但是Q和V会混淆吗?特别是按定义的话,V还是V吗?还是说如果policy是deterministic的话就没有问题?rich的书上和这个写法其实是一样的,不过rich 没有用Q,直接用的V,然后policy就是argmax结合一步转移的V。这样看的话,对于deterministic policy,这么写好像是没问题的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号