
Collect & Infer - a fresh look at data-efficient Reinforcement Learning
发表时间:2021
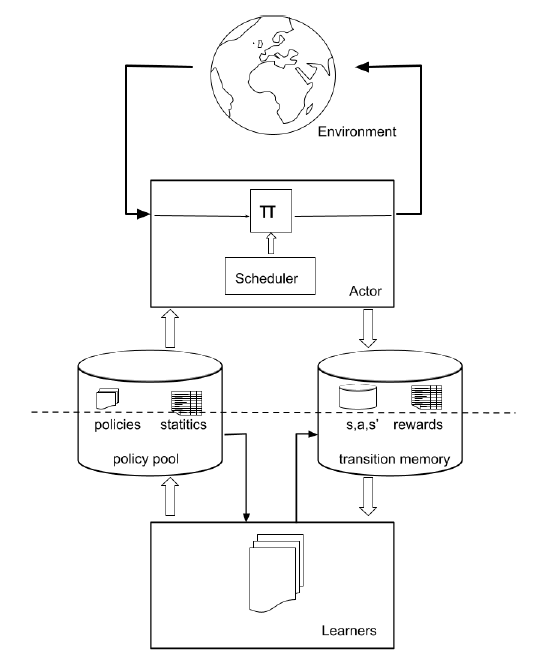
文章要点:一篇比较短的概念性的文章,主要想说Data-efficient RL走过了三个阶段,一个是pure on-line RL,就是数据来了用一次就扔;第二个是RL with a replay buffer,数据来了会存到一个容量有限的buffer里,数据可以被多次利用;第三个就是transition memory based RL,所有的数据都被存下来,并且可以无限制使用。这些阶段其实都离不开两个部分,一个部分是收集数据(collect),另一个部分是学习policy(infer),所以作者就提出了一个Collect and Infer (C&I) paradigm的范式。

主要就是想启发大家多从这两方面去思考RL怎么提升吧。
总结:我之前也有类似的想法,特别是最近offline RL流行起来之后,感觉大家都在用这种拆分成offline RL和exploration的方式来做RL。
疑问:无。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号