
Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning
发表时间:2018
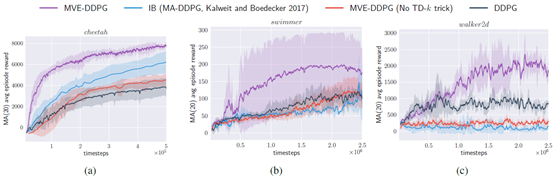
文章要点:这篇文章提出了model-based value expansion (MVE)算法,通过在model上扩展有限深度,来控制model uncertainty,利用这有限步上的reward来估计value,提升value估计的准确性,在结合model free算法来训练。相当于用model来做short-term horizon的估计,用Q-learning来做long-term的估计(We present model-based value expansion (MVE), a hybrid algorithm that uses a dynamics model to simulate the short-term horizon and Q-learning to estimate the long-term value beyond the simulation horizon.)。
具体的,文章假设model一直到H深度都是准确的,所以value的估计可以用当前policy在model上扩展这H步

在model里面走H步有一个好处是,得到的value就是on policy的,所以不需要做修正。
还有一个问题是\(s_0\)从哪来,如果直接从buffer里面采样,那么这个\(s_0\)的分布和当前policy的分布可能是不一样的,所以也会出问题(distribution mismatch)。作者这里假设policy对应的state的分布是一个不动点,这个假设是make sense的,那么先在model里面用当前policy从\(s_0\)走几个step,那么这个分布就会靠近这个不动点,然后再去计算value就不会有distribution mismatch的问题了。

作者把这个方法叫做TD-k trick。有了这个之后,就用来训model free RL就行了。作者用的是DDPG,整个算法如下

总结:这篇文章提出的MVE算是很多model based算法的起点了,在这个方向上挺出名的了。另外这个H不太好确定,所以后面就出现了一些工作来自适应选择H。
疑问:有个问题是不知道为什么会work,因为基于one-step的贝尔曼方程更新的Q-learning类算法都是off policy的,并不需要on policy的估计。这里on policy的估计对贝尔曼方程收敛性的影响是啥还不清楚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号