When to use parametric models in reinforcement learning?
发表时间:2019(NeurIPS 2019)
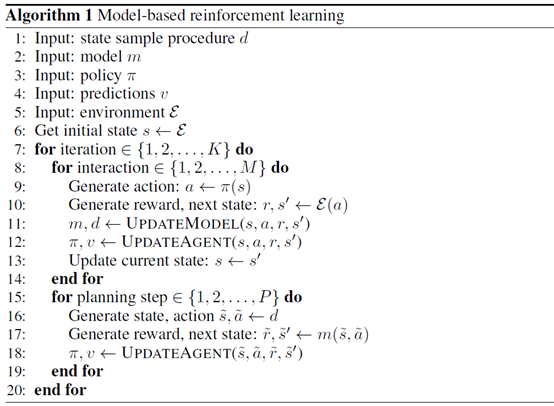
文章要点:这篇文章研究了parametric models和experience replay的异同,探讨什么时候用什么方式能取得各自的优势。结论是用model去学value和policy的时候,plan backward要比plan forward更好。Plan forward在选动作的时候用会有更好的效果(it can be better to plan backward than to plan forward when using models to perform credit assignment (e.g., to directly learn a value or policy)。it can be beneficial to plan forward for immediate behaviour, rather than for credit assignment)。
这里plan forward就是从当前state往前推,plan backward就是从当前state往回推,
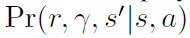
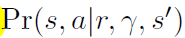
作者的意思是说plan forward可能会导致不准的估计进而影响效果,而plan backward可能也会不准,对更新没好处但是也没坏处。而Plan forward在选动作的时候用会有更好的效果,是因为就算model不准,也不会影响value和policy的更新,因为这个时候只用来选动作,model并不会产生不准确的state。
作者做的实验就是想说,直接用replay buffer也可以产生比model based更好的效果。作者在Rainbow DQN上做了实验,然后和SimPLe算法作对比,之前SimPLe的论文里说这个model based方法比Rainbow好,作者这就想说,我做出来的实验是不如Rainbow好(We explain why their results may perhaps be considered surprising, and show that in a like-for-like comparison Rainbow DQN outperformed the scores of the model-based agent, with less experience and computation.)。作者就简单调了下Rainbow的参数,

然后效果就比SimPLe好了
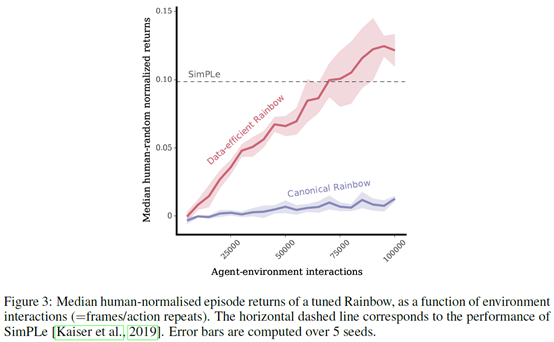
所以作者就想说只用plan forward来收集数据更新value和policy是比不过model free的(We hypothesise that, under suitable conditions, replay-based algorithms should be competitive to or better than model-based algorithms if the model is used only to generate fictional transitions from observed states for an update rule that is otherwise model-free)。
总结:感觉内容不够充分,而且plan backward这个方式也挺玄学的。不过给出的一点启示是,Q-learning这种有buffer的算法,可能model的优势就不明显了。那么反过来想,对于PG这种on policy算法,学一个model就有优势产生更多on policy的样本,而buffer是做不到这一点的,这可能就是优势所在吧。
疑问:这个plan backward比plan forward更好的解释有点牵强啊感觉,我都已经有了\(s_{t-1}\)了,还用\(s_t\)反向预测\(s_{t-1}\)干啥?而且这些预测都是1-step的,怎么可能搞得过replay buffer啊?
文中这个图里就planning了0,1,2步,这真的够说明问题吗?

文中说Rainbow DQN调调参数设置就能效果好这么多,有这么神奇吗?这里的原理是啥,因为更新次数变多了吗?文中也不写写为啥这么调。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号