
ON THE ROLE OF PLANNING IN MODEL-BASED DEEP REINFORCEMENT LEARNING

发表时间:2021(ICLR 2021)
文章要点:这篇文章想要分析model-based reinforcement learning (MBRL)里面各个部分的作用。文章以muzero为基础,回答了三个问题
(1) How does planning benefit MBRL agents?
(2) Within planning, what choices drive performance?
(3) To what extent does planning improve generalization?
得出的结论是
(1)planning在learning阶段使用是最有用的,作用主要体现在生成数据和计算learning target,评估阶段在大多数环境上只有轻微提升。
(2)除了某些复杂的需要推理的任务,大多数任务只需要浅层的planning就足够了,太深是没有必要的。甚至直接Monte-Carlo rollouts而不需要tree search就够了(Note that DUCT = 1 corresponds to only exploring with pUCT at the root node and performing pure Monte-Carlo sampling thereafter. We find DUCT to have no effect in any environment except 9x9 Go)。
(3)只靠planning不足以产生强大的泛化性。
作者把MBRL分成两大类,一类是decision-time planning,通过model来选择动作。另一类是background planning,用model来更新policy,policy选动作。然后作者认为muzero和各种MBRL都有很深刻的联系,比如直接用MCTS就是decision-time planning,训练的时候用MCTS,选择动作的时候直接用policy就是background planning,所以用muzero来做实验再好不过。
作者基于muzero做了这么几个变种:One-Step,Learn,Data,Learn+Data,Learn+Data+Eval。这里先要解释几个和planning相关的定义,如下图
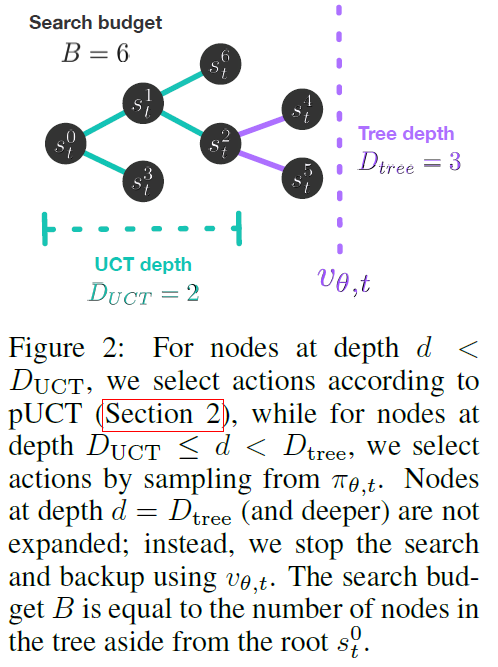
\(D_{tree}\)是整个搜索过程的深度,\(D_{UCT}\)就是说用MCTS搜索的深度,\(B\)是search budget,表示总的搜索次数。如果搜索深度小于\(D_{UCT}\),就用MCTS的方式搜索;如果超过了\(D_{UCT}\)但是没有超过\(D_{tree}\),就通过policy来搜索;如果到达了\(D_{tree}\),就停止搜索。
另外在介绍几种变种的含义之前,还要区分几个词的意思,learning,act,training,test。Learning就是说学value和policy的过程,如果是\(D_{tree}\)=1,就只有一步的target value,就相当于1-step Q learning的形式。Act指做动作用什么,用MCTS选动作或者用policy输出动作。Training就是指整个训练过程,这个过程既包括训练网络,也包括planning,所以自然会包括learning和act。Test就是测试或者说评估,这个过程会包括act。然后几种变种的含义如下:
One-Step就是learning的时候设置\(D_{tree}=1\),只估计1-step return,训练和评估的动作都通过policy网络输出。Model的训练就只预测一步,其他的变种都预测的5步。所以这个变种比较像model free的版本,因为只会planning一步,而且整个更新和Q learning很像。
Learn就是在learning的时候设置\(D_{tree}=\infty\),就会有n-step return来做target value。但是训练和评估的动作还是通过policy网络输出。这相当于度量搜索深度对learning的影响,而不是act,而且这里并没有MCTS。
Data就是在learning的时候设置\(D_{tree}=1\),训练的时候动作通过MCTS选择,MCTS的深度为\(D_{tree}=\infty\),test的时候动作用policy网络输出。这相当于度量MCTS在收集数据中的作用。
Learn+Data就是在learning的时候设置\(D_{tree}=\infty\),训练的时候动作通过MCTS选择,MCTS的深度为\(D_{tree}=\infty\),test的时候动作用policy网络输出。
Learn+Data+Eval就是muzero。


测试结果如下图

此外,作者还给出了一些很有意思的结论:
很多环境可能并不适合用来测试model based方法和planning,因为这些环境可能就不需要复杂的推理。
如果你的value和policy在learning的时候没有学好,那planning也不会有用。
增加planning的budget通常有好处,但太大甚至会有坏处,这点我估计应该是model不准的原因(compounding model errors)。
总结:很有意思的一篇文章,实验做的很多,结论也很有意思。
疑问:关于第一条结论:planning在learning阶段使用是最有用的,作用主要体现在生成数据和计算learning target,评估阶段在大多数环境上只有轻微提升。感觉在policy初期的时候,评估阶段的planning应该会很有用吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号