MASTERING ATARI WITH DISCRETE WORLD MODELS
发表时间:2021(ICLR 2021)
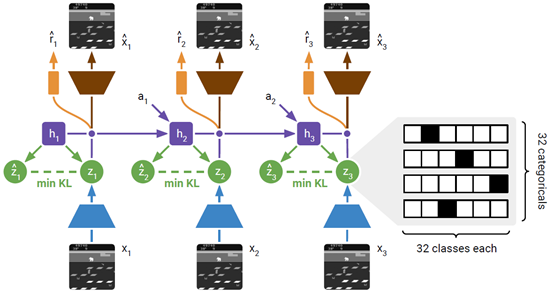
文章要点:这篇文章是《DREAM TO CONTROL: LEARNING BEHAVIORS BY LATENT IMAGINATION》的后续,前面那篇文章做出来的效果在连续控制上挺好的,但是Atari上不行。这篇就接着做Atari,做到比model free方法好。所以这个东西作者叫他DreamerV2。相较于Dreamer,主要改动就是训练离散表征,以及一个KL loss(using discrete latents and balancing terms within the KL loss.)。
具体的就是把之前的高斯潜变量变成分类潜变量,以及有一项KL balancing的loss

有了model之后就在latent space上训练actor critic

Critic用了一个\(\lambda\)-target来平衡n-step return的权重。
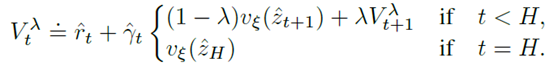
作者还总结了一下各个部分的对效果的影响

看得出来Discrete Latents和KL Balancing影响都很大,Policy Reinforce更新方式也很重要,Image Gradients就是说在学world model的时候不用gradients from image reconstruction,只用gradients from reward prediction,这个对model的学习影响很大,进而对最后的效果影响也很大。
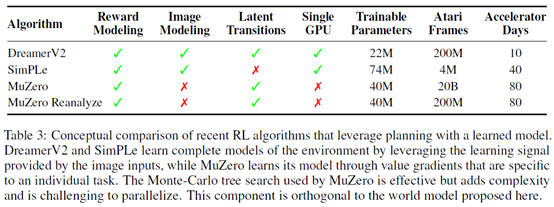
总结:算是model based的方法里面取得了不错的效果,但是文章里也提到了muzero的效果比这好。然后作者想说这个训练时间更短,但是这训练了10天,还是太久了。
疑问:这个KL balancing没看懂啥原理,另外,之前的paper里也有这一项啊,区别很大吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号