
NEURAL PROBABILISTIC MOTOR PRIMITIVES FOR HUMANOID CONTROL
发表时间:2019(ICLR 2019)
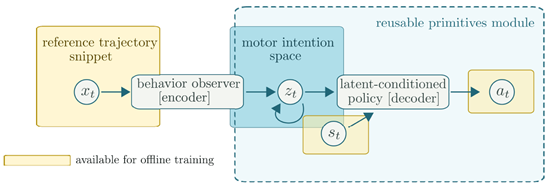
文章要点:这篇文章主要是想学习人类的控制策略,并且能够重复使用。主要思路就是通过监督学习去学一个叫做neural probabilistic motor primitives的模型。这个模型包括一个encoder和一个decoder

这里\(s_t\)是当前状态,\(x_t\)是很多个未来的状态拼起来的

所以要训练一条轨迹,就相当于最大化联合概率
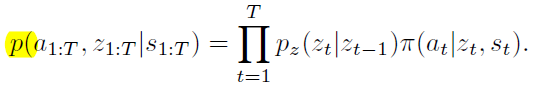
这里作者假设了\(z_t\)是一个时间序列AR(1) process

也就是\(p_z\)。然后encoder和decoder都是MLP神经网络。Encoder的输入就是\(z_{t-1}\)和\(x_t\)拼起来,输出就是一个多元高斯和方差。Decoder的输入就是\(z_t\)和\(s_t\)拼起来,输出是多元高斯以及固定的标准差0.1。然后整个训练做了个变形,变成优化evidence lower bound (ELBO)

然后这部分学好了后,只要给一个当前状态\(s_t\)和目标序列\(x_t\),就可以得到embedding\(z_t\),然后就可以从decoder里返回动作了。
这部分的目的主要是为了学decoder,也就是\(\pi\),因为想要reuse the learned motor primitive space to solve tasks,就先用这种方式把skills都压缩到一个潜空间里,然后想要复现什么skill,就给一个当前状态和目标skill就可以了。
然后作者又说了一个用模仿学习学student policy,也就是offline policy cloning或者linear feedback policy cloning。offline policy cloning就是expert policy rollout很多次,rollout里面可以给action加点噪声,然后学均值,这样效果更robust。linear feedback policy cloning就是说暴力rollout对样本量需求太大了,所以通过求雅可比矩阵然后加噪声的方式,直接可以一条轨迹生成多条带噪声的轨迹,其实就是求个梯度然后给state加个扰动

总结:有点像CoMic: Complementary Task Learning & Mimicry for Reusable Skills这篇文章的前置文章。主要是怎么把skill压缩到一个latent space上,供后面继续利用。
疑问:inverse model with a latent-variable bottleneck,inverse model是啥,bottleneck是啥?
motion capture clips怎么翻译?
nominal trajectory怎么翻译?
open-loop action sequence,啥叫open loop?
后半部分讲Behavioral cloning的时候也不知道是学的encoder还是decoder,直接就没提\(z_t\)了,感觉和前面Compression有点脱节啊。但是既然是学student policy,难道学的是\(p\)?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号