LEARNING WITH AMIGO: ADVERSARIALLY MOTIVATED INTRINSIC GOALS
发表时间:2021(ICLR 2021)
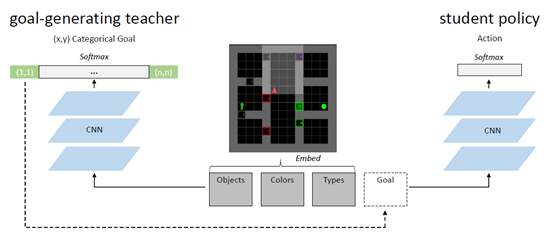
文章要点:这篇文章提出了一个解决sparse extrinsic rewards的办法AMIGO。思路就是用一个goal-generating teacher来生成难度适中的任务目标(constructively adversarial objective),提供一个目标相关的外部reward,让goal-conditioned student policy来学。具体来说,student policy就是通常的强化,paper里用的IMPALA,只是reward变成了
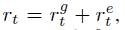
这里\(r_t^e\)就是环境给的外部reward,\(r_t^g\)就是teacher给的目标reward

这意思就是说到达目标了就给1,否则就是0.
而goal-generating teacher也是用强化训的,他的policy就是输出一个不要太简单但是也不太难的任务(propose goals that are not too easy for the student to achieve, but not impossible either).具体实现也很简单,就是设一个阈值\(t^*\),如果student policy完成了任务并且所需的step大于\(t^*\),就给一个正的reward给teacher,如果student policy完不成或者完成了但是step小于\(t^*\),就给负的reward
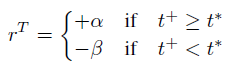
然后整个训练过程这个阈值慢慢增大,就相当于goal慢慢变难(Specifically, the threshold is increased by 1 whenever the student successfully reaches an intrinsic goal in more than \(t^*\) steps for ten times in a row.)。然后就结束了。
看到这里基本上就知道了,首先这个teacher输出的goal是坐标位置以及位置上的东西,因为是在迷宫任务上做的。这个设置其实就说明的这个方法没法通用,只能自己具体问题具体设计。另外看teacher reward的设计,以及阈值\(t^*\),也知道这里面有多少trick,有多少调参了。
总结:总的来说没意思,虽然是ICLR的paper,而且还是MIT做的,感觉还是有点水了。Trick有点多,不够通用,需要疯狂调参。
疑问:文章里面强调了两次在6个任务上一共做了114个实验,这实验数量也能拿来吹了吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号