From Motor Control to Team Play in Simulated Humanoid Football


发表时间:2021
文章要点:这篇文章有点长,主要是说训练了一个2v2的足球,使得运动方式拟人化,同时产生了合作和配合。方法上来说,分成三个阶段,第一个阶段用监督学习(imitation learning)的方式学习基本的拟人化运动方式,比如站立,走路,奔跑之类的;第二个阶段用强化的方式(reinforcement learning)学习一些基本的足球动作,比如带球,射门之类的,这些动作也是人为定义的;最后一个阶段用PBT的方式(multi-agent reinforcement learning)训练2v2对战。其中第一个阶段学到的运动方式会固定化,并且通过encoder的方式编码到一个潜动作空间,后面两个阶段的动作空间就是这个潜空间了,这样的话就可以保证在后面的训练过程中不会遗忘基本的运动方式。然后第二个阶段的基本足球动作学会后,也不会再更新了,而是通过KL散度的方式在第三个阶段做约束,以防在后面的训练过程中遗忘了。整个文章主要是想表达这个控制过程中既结合了低层次的肌肉关节的运动,也集合了高层次的合作配合等策略的学习,既有毫秒级反应,也有宏观层面的决策,是一个多层面,多尺度的决策控制问题。对于性能方面,没有过多比较。

总结:这文章确实有点又臭又长了,感觉有点像神经科学,脑科学,运动科学的文章,扯了很多有的没的。技术细节讲的很粗糙,还要看他引的那几篇才行。另一个感受是,整个算法里面,reward shaping依然很重要,以及各个人为定义的足球动作,性能统计量、评判指标等,都体现出了人为层面的设计难度和调参的困难,再加上和具体的足球任务高度关联的设计也暗示了以后想要通用化的难度。
疑问:这个先模仿学习,再distill的两阶段过程具体咋做的?

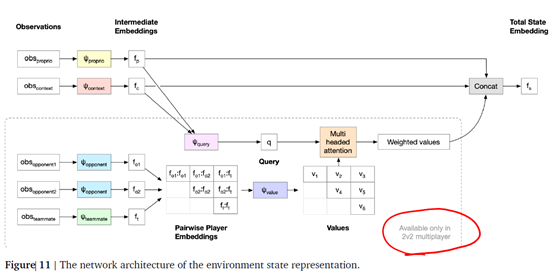
状态具体是怎么表征的?
reward这么复杂是怎么考虑的?value据说是个向量,这个具体咋做的?里面还有好多足球相关的设计指标,没有细看。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号