
RECURRENT EXPERIENCE REPLAY IN DISTRIBUTED REINFORCEMENT LEARNING(R2D2)
发表时间:2019 ICLR
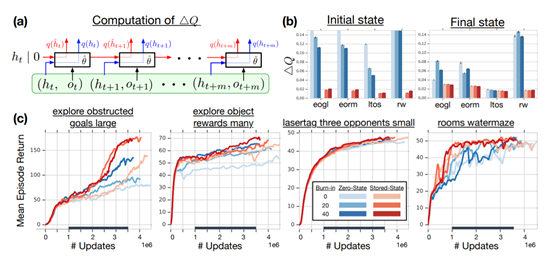
文章要点:文章在Q-learning的基础上加上rnn结构,提出了解决rnn中hidden state如何用来更新的问题。以前的rnn的初始hidden state直接输入0,这会造成和真正的hidden state有偏差的问题(initial recurrent state mismatch)。更好的办法是把hidden state存下来(stored state),更新的时候代替0作为输入。但这种方式会造成representational drift和recurrent state staleness的问题,直白点说就是之前存的hidden state在我更新网络后和新网络的hidden state仍然有偏差,所以用之前存的hidden state虽然比0要好,但是也不是完全准确的。特别是在off policy方法中,样本会被多次利用,这个问题会更加严重。作者在此基础上又提出burn-in的方式来缓解该问题。具体说就是将hidden state输入后,先作用到一串轨迹上来产生L步之后的hidden state,然后这之后的样本轨迹才用来更新网络,前面的部分就不用来更新了,起到一个缓冲掉不准确的hidden state的作用。(using a portion of the replay sequence only for unrolling the network and producing a start state, and update the network only on the remaining part of the sequence)相当于前期的hidden state不够准确,那我就不用来更新了,等缓冲了一段轨迹后,hidden state没有那么大误差了,才用来更新网络(prevents‘destructive updates’)。此外还用了一些其他技术,比如一个新的reward scaling,有一点改进的replay prioritization以及分布式RL。
总结:文章利用了rnn的记忆功能,同时也解决了怎么正确使用hidden state的问题,符合逻辑。
疑问:那个做scaling的函数为啥长成这样?
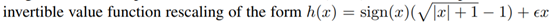
这里主要就是开个根号吧,那怎么还要搞个+1-1以及\(\epsilon x\)?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号