随笔分类 - Reinforcement Learning
reinforcement learning algorithm
摘要:**发表时间:**2018 **文章要点:**这篇文章提出A0C算法,把AlphaZero做到连续动作空间上,主要使用的方式是progressive widening和continuous prior(就是continuous policy network)。具体的,progressive wide
阅读全文
摘要: **发表时间:**2021(ICML 2021) **文章要点:**这篇文章想说,通常强化学习算法explorat
阅读全文
摘要:**发表时间:**2021(ICML 2021) **文章要点:**这篇文章想说神经网络的解释性太差,用简单的符号式子来表示策略具有更好的解释性,而且性能也不错。这里符号式子就是一个简单的函数。作者就提出了一个叫deep symbolic policy的算法来搜索symbolic policies。
阅读全文
摘要:**发表时间:**2021(ICML 2021) **文章要点:**这篇文章就是在小的环境上重新测试了一遍DQN以及一系列变种的效果,得出的结论就是说即使是在简单任务上进行测试,也能得到有价值的结果,呼吁降低研究RL的算力门槛。具体的,作者先说就算是Atari游戏上做研究,对算力的要求也是巨大的,A
阅读全文
摘要:**发表时间:**2020(ICML 2020) **文章要点:**这篇文章提出了一个Plan2Explore的model based方法,通过self-supervised方法来做Task-agnostic的探索,在这个过程中有效学习了world model,然后可以迁移到下游的具体任务上,实现z
阅读全文
摘要: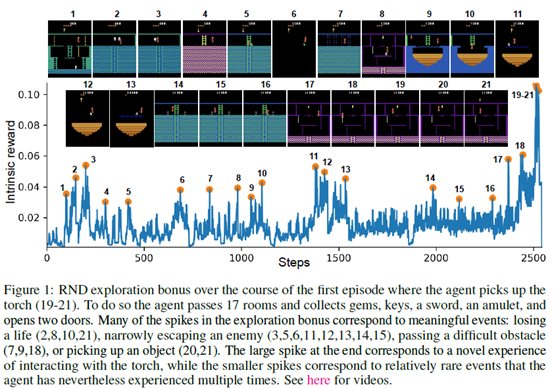 **发表时间:**2018(ICLR 2019) **文章要点:**文章提出了一个random network
阅读全文
摘要:**发表时间:**2020(ICLR 2020) **文章要点:**这篇文章的思路是运用distributed RL的形式,基于intrinsic reward,并行多个agent,将exploration策略和exploitation策略分开单独训练,这样可以设置一族探索程度不同的explorat
阅读全文
摘要:**发表时间:**2021(NeurIPS 2021) **文章要点:**这篇文章提出Latent Explorer Achiever (LEXA)算法,通过学习world model的imagined rollouts来训练一个explorer策略和一个achiever策略,通过unsupervi
阅读全文
摘要:**发表时间:**2020(ICML) **文章要点:**这篇文章提出Agent57算法,是第一个在所有57个Atari游戏上超过人类表现的算法。主要的思路就是基于Never Give Up (NGU)和R2D2((RECURRENT EXPERIENCE REPLAY IN DISTRIBUTED
阅读全文
摘要:**发表时间:**2020(IJCAI 2020) **文章要点:**这篇文章提出Policy Transfer Framework (PTF)算法来做policy transfer。主要思路就是自动去学什么时候用哪一个source policy用来作为target policy的学习目标,以及什么
阅读全文
Think Too Fast Nor Too Slow: The Computational Trade-off Between Planning And Reinforcement Learning
摘要:**发表时间:**2020(ICAPS: PRL 2020) **文章要点:**这篇文章主要探究planning和learning的算力的trade-off,得出的结论是既不能planning太多,也不能planning太少。 具体的,作者先指出了一类叫multi-step approximate
阅读全文
摘要:**发表时间:**2018(ICAPS 2018 workshop Heuristics and Search for Domain-independent Planning (HSDIP)) **文章要点:**这篇文章主要就是做实验看了看几种tree search方法在Atari上的效果如何,里面
阅读全文
摘要:**发表时间:**2014(NIPS 2014) **文章要点:**这篇文章主要是测试了Monte-Carlo Tree Search在Atari上的效果,不过并不是结合强化做的,而是先用tree search收集样本,再用神经网络拟合数据训成一个Q网络或者policy网络。得出的结论是比DQN效果
阅读全文
摘要:**发表时间:**2020(AAAI 2021) **文章要点:**这篇文章提出Propositional Logic Nets (PROLONETS),通过建立决策树的方式来初始化神经网络的结构和权重,从而将人类知识嵌入到神经网络中作为初始化warm start,然后进行强化学习。 具体的,就是先
阅读全文
摘要:**发表时间:**2018(ICLR 2018) **文章要点:**这篇文章设计了特别的网络结构,将树结构嵌入到神经网络中,实现了look-ahead tree的online planning,将model free和online planning结合起来,并提出了TreeQN和ATreeC算法。并
阅读全文
摘要:**发表时间:**2020 **文章要点:**这篇文章是篇综述,主要从RL和planning的异同入手,总结了对解决MDP这类问题的公共因素,放到一起称作framework for reinforcement learning and planning (FRAP)的框架。首先文章提出,RL和pla
阅读全文
摘要:**发表时间:**2018 **文章要点:**这篇文章提出了Forward-Backward Reinforcement Learning (FBRL)算法,在假设reward function和goal已知的情况下,将model free的forward step和model based的back
阅读全文
摘要:**发表时间:**2021 **文章要点:**这篇文章提出了Discriminator Augmented MBRL (DAM)算法,文章想说model based RL里面,学到的model是不准确的,这个问题也是很难避免的,于是作者换了一个思路,不去修正model,而是通过importance
阅读全文
摘要:**发表时间:**2021 **文章要点:**文章基于TF-Agent库(model free RL)设计了一个model based RL的库,主要包括三个模块,Environment Model,Agent Classes和Experiment Harness。Environment Model
阅读全文
摘要:**发表时间:**2018(ICLR 2018) **文章要点:**这篇文章提出了temporal difference models(TDMs)算法,把goal-conditioned value functions和dynamics model联系起来,建立了model-free和model-b
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号