
1、match:match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。该方法类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置。
2、replace:replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
3、search:search() 方法 用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串,并返回子串的起始位置。
4、RegExp 对象有 3 个方法:test()、exec() 以及 compile()。
4.1、test():test() 方法用于检测一个字符串是否匹配某个模式,返回 true或者 false。
匹配一段字符串 /123456/.test("abc123456") //true /123456/.test("12345") //false ^:起始位置 /^http/.test("http://www.baidu.com") $:结尾位置 /com$/.test("http://www.baidu.com") //true \b:单词边界 /\bis\b/.test("this") //false /\bis\b/.test("that is my mom !") //true [0-9]一个数字 /[0-9]/.test('123')) //true [^0-9]:非数字的一个字符 /[^0-9]/.test('abc') //true .:任一字符(换行符除外) /./.test('abc') //true * :{0,} 0到无穷次 /\d*/.test('abc') //true + :{1,,} 1次或1次以上 /\d+/.test('abc') //false /\d+/.test('1abc') //true ?: {0,1} 0次或1次 /https?:/.test('http://www.163.com') //true
4.2、exec() :exec() 方法检索字符串中的指定值。返回值是被找到的值。如果没有发现匹配,则返回 null。
var str="Hello world!"; //查找"Hello" var patt=/Hello/g; var result=patt.exec(str); console.log("返回值: " + result) //返回值: Hello //查找 "RUNOOB" patt=/RUNOOB/g; result=patt.exec(str); console.log("返回值: " + result) //返回值: null
4.3、compile():compile() 方法用于改变 RegExp。compile() 既可以改变检索模式,也可以添加或删除第二个参数。
RegExpObject.compile(regexp,modifier) regexp:正则表达式。modifier:匹配的类型
var str="Every man in the world! Every woman on earth!"; patt=/man/g; str2=str.replace(patt,"person"); console.log(str2); //Every person in the world! Every woperson on earth! patt=/(wo)?man/g; patt.compile(patt); str2=str.replace(patt,"person"); console.log(str2); //index.html:129 Every person in the world! Every person on earth!
1、match:返回指定的值
var str="Hello2222kkkk3333;k2222,world!,,world,World"; console.log(str.match(/\d+/g)); // ["2222", "3333", "2222"] console.log(str.match(/world/ig)) // ["world", "world", "World"] console.log(str.match("world")) // ["world", index: 24, input: "Hello2222kkkk3333;k2222,world!,,world,World", groups: undefined]
2、replace:替换
| 字符 | 替换文本 |
|---|---|
| $1、$2、...、$99 | 与 regexp 中的第 1 到第 99 个子表达式相匹配的文本。 |
| $& | 与 regexp 相匹配的子串。 |
| $` | 位于匹配子串左侧的文本。 |
| $' | 位于匹配子串右侧的文本。 |
| $$ | 直接量符号。 |
var str="We are proud to announce that Microsoft has Visit microsoft!"; console.log(str.replace(/Microsoft/gi, "W3School")); //We are proud to announce that W3School has Visit W3School! console.log(str.replace(/(\w+)\s* \s*(\w+)/, "$2 $1")) //are We proud to announce that Microsoft has Visit microsoft!
3、search
var str="Mr. Blue has a blue house"; console.log(str.search("blue")) //15 console.log(str.search(/blue/i)) //4
元字符:是一些在正则表达式中有特殊用途、不代表它本身字符意义的一组字符
需要进行转义的元字符: . * + ( ) $ / \ ? [ ] ^ { } - ! < >
表1:特殊字符
| 元字符 | 含义 |
| \0 | 匹配null字符,对应的十六进制值为\x00 |
| \b | 匹配退格字符,对应的十六进制值为\x08 |
| \n | 匹配换行字符,对应的十六进制值为\x0A |
| \r | 匹配回车字符,对应的十六进制值为\x0D |
| \f | 匹配换页字符,对应的十六进制值为\x0C |
| \t | 匹配制表(TAB)字符,同时对应于水平制表符\x09和垂直制表符\x0B |
| \xhh | 匹配用2个十六进制数字表示的字符 |
| \uhhhh | 匹配用4个十六进制在数字表示的字符,这些字符是Unicode字符 |
| \cchar | 匹配命名的控制字符 |
表2:字符类
| 元字符或元符号 | 含义 |
| [...] |
匹配列表中给出的任何字符。该列表可以是一个字符,也可以是多个字符,还可以是使用“-”表示的字符范围。 例如:[a]表示匹配单个字母a;[ab]表示匹配字母a或字母b;[a-z]表示匹配任何一个小写字母;[0-9]表示匹配任何单个的数字;[a-z0-9]表示匹配任何单个的小写字母或数字。 []中,不会出现两位数。eg:匹配从18到65年龄段所有的人。reg = /(18|19)|([2-5]\d)|(6[0-5])/; |
| [^...] |
匹配列表中没有给出的任何单个字符。该元字符与[...]的意义刚好相反。 例如: [^a]表示匹配任何不是字母a的字符 [^ab]表示任何不是字母a或字母b的字符 [^a-z]表示任何不是小写字母的任何字符,等等 |
| . | 匹配除了回车和换行符之外的任何字符 |
| \w | 元符号,相当于[a-zA-Z0-9_],匹配任何字母、数字、下划线字符,这样的字符也称为单词字符 |
| \W | 元符号,相当于[^a-zA-Z0-9_],匹配除了字母、数字、下划线字符之外的任何字符 |
| \d | 元符号,相当于[0-9],匹配任何单个的数字字符 |
| \D | 元符号,相当于[^0-9],匹配除了数字之外的任何单个字符 |
| \s | 元符号,匹配空白字符,空白字符是指空格、Tab字符和回车换行符 |
| \S |
元字符,匹配任何非空白字符 |
表3:定位元字符
| 元字符 | 含义 |
| ^ | 匹配字符串的开始位置,或多行匹配模式中(\m)每一行的开始位置 |
| $ | 匹配字符串的结束位置,或多行匹配模式下(\m)每一行的结束位置 |
| \b |
匹配单词边界。这个元字符用于单词匹配。单词边界有4种形式: 1、当字符串第一个字符是单词字符时,位于第一个字符前面; 2、当字符串最后一个字符是单词字符时,位于最后一个字符后面; 3、在单词字符和非单词字符之间,紧跟在单词字符后面; 4、在非单词字符和单词字符之间,紧跟在非单词字符后面 |
| \B | 匹配非单词边界,这个元字符匹配\b不匹配的每一个位置 |
| x(?=y) |
正向前查匹配。也就是说,只有在x后面跟上y时,才匹配x成功。 例如: 使用正则表达式 |
| x(?!y) |
反向前查匹配。只有在x后面不跟着y时,才匹配x成功。 例如: 在使用正则表达式 |
表4:模式修饰符
| 元字符 | 含义 |
| g | 进行全局匹配 |
| m | 多行匹配 |
| i | 不区分大小写匹配 |
表5:限定符
| 元字符 | 含义 |
| x? |
匹配0个或1个x。 例如: |
| x+ |
匹配1个或多个x。 例如: |
| x* |
匹配0个或多个x。 例如: |
| x{n} |
匹配n个x。 例如: |
| x{n,} |
匹配n个或多个x。 例如: |
| x{n,m} |
匹配n到m个x。 例如: |
|
贪婪匹配原则 在JavaScript中,正则表达式进行匹配时默认使用的是贪婪匹配原则,即尽可能多的匹配字符串。 例如,使用正则表达式/1{3,4}/来匹配字符串1111111,得到的结果为:1111和111。即先匹配4个字符,然后才匹配3个字符。 |
|
表5:分组和替换元字符
| 元字符 | 含义 |
| x|y |
匹配x或y, 例如:/cat|dog/匹配cat或dog |
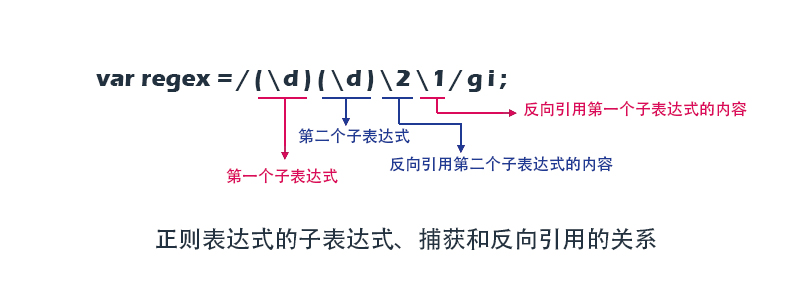
| (sub) |
反向引用,将子表达式sub作为一个整体处理,括号的作用相当于代数中括号的作用。并将捕获的子匹配保存在\1,\2,......和$1,$2,......中。 例如: |
| (?:sub) | 分组子模式,但是不捕获子模式。它的作用与(sub)类似,称为无记忆匹配 |
| \1,\2,\3,... | 在正则表达式中,分别包含与正则表达式中第一个反向引用、第二个反向引用、第三个反向引用...相匹配的子串 |
| $1,$2,$3,... | 在替换中,分别包含与正则表达式中第一个反向引用、第二个反向引用。第三个反向引用...相匹配的子串 |
参考:https://blog.csdn.net/feiying008/article/details/52886304

 浙公网安备 33010602011771号
浙公网安备 33010602011771号