Elasticsearch 如何做到快速检索的秘密
一、前言
最近接触的几个项目都使用到了 Elasticsearch (以下简称 ES ) 来存储数据和对数据进行搜索分析,就对 ES 进行了一些学习。本文整理自我自己的一次技术分享。
本文不会关注 ES 里面的分布式技术、相关 API 的使用,而是专注分享下 ”ES 如何快速检索“ 这个主题上面。这个也是我在学习之前对 ES 最感兴趣的部分。
本文大致包括以下内容:
关于搜索
- 传统关系型数据库和 ES 的差别
- 搜索引擎原理
- 细究倒排索引
- 倒排索引具体是个什么样子的(posting list -> term dic -> term index)
- 关于 postings list 的一些巧技 (FOR、Roaring Bitmaps)
- 如何快速做联合查询?
关于搜索
先设想一个关于搜索的场景,假设我们要搜索一首诗句内容中带“前”字的古诗:

用 传统关系型数据库和 ES 实现会有什么差别?
如果用像 MySQL 这样的 RDBMS 来存储古诗的话,我们应该会去使用这样的 SQL 去查询
select name from poems where content like "%前%";
这种我们称为顺序扫描法,需要遍历所有的记录进行匹配。
不但效率低,而且不符合我们搜索时的期望,比如我们在搜索“ABCD"这样的关键词时,通常还希望看到"A","AB","CD",“ABC”的搜索结果。
于是乎就有了专业的搜索引擎,比如我们今天的主角 -- ES。
搜索引擎原理
搜索引擎的搜索原理简单概括的话可以分为这么几步:
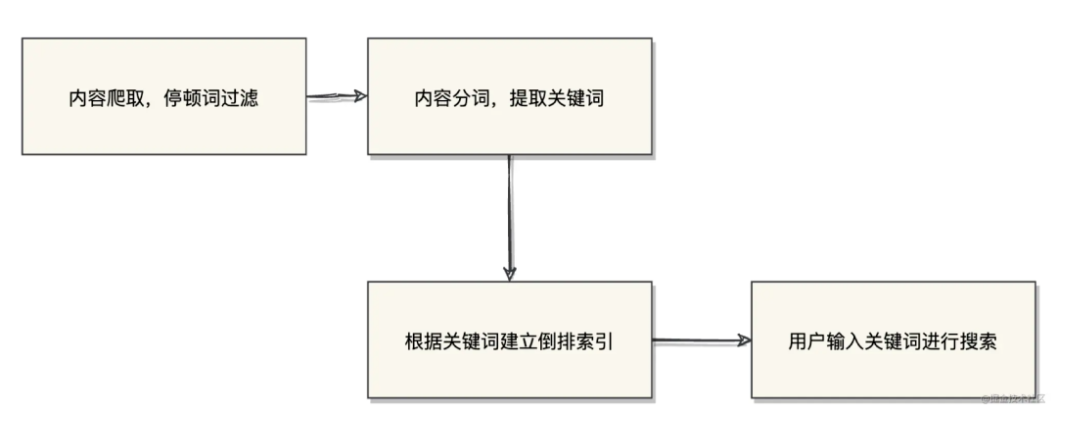
内容爬取,停顿词过滤,比如一些无用的像"的",“了”之类的语气词/连接词
- 内容分词,提取关键词
- 根据关键词建立倒排索引
- 用户输入关键词进行搜索
这里我们就引出了一个概念,也是我们今天的要剖析的重点 - 倒排索引。也是 ES 的核心知识点。
如果你了解 ES 应该知道,ES 可以说是对 Lucene 的一个封装,里面关于倒排索引的实现就是通过 lucene 这个 jar 包提供的 API 实现的,所以下面讲的关于倒排索引的内容实际上都是 lucene 里面的内容。
三、倒排索引
首先我们还不能忘了我们之前提的搜索需求,先看下建立倒排索引之后,我们上述的查询需求会变成什么样子:
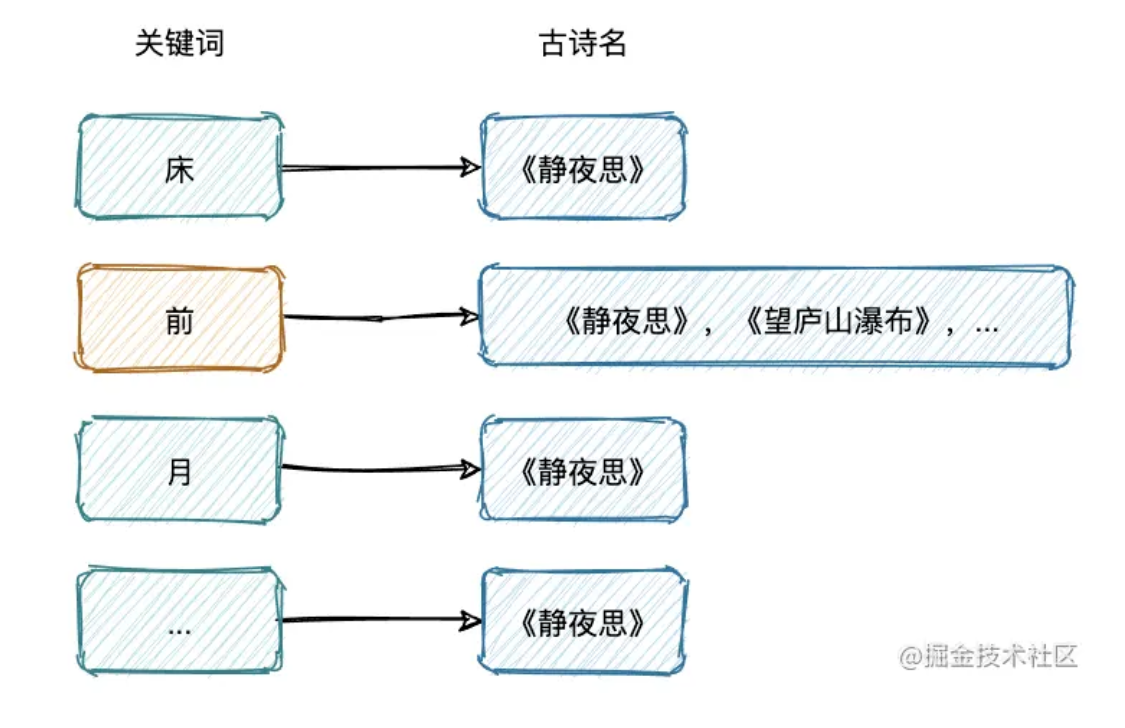
这样我们一输入“前”,借助倒排索引就可以直接定位到符合查询条件的古诗。
当然这只是一个很大白话的形式来描述倒排索引的简要工作原理。在 ES 中,这个倒排索引是具体是个什么样的,怎么存储的等等,这些才是倒排索引的精华内容。
1. 几个概念
在进入下文之前,先描述几个前置概念。
term
关键词这个东西是我自己的讲法,在 ES 中,关键词被称为 term。
postings list
还是用上面的例子,{静夜思, 望庐山瀑布}是 "前" 这个 term 所对应列表。在 ES 中,这些被描述为所有包含特定 term 文档的 id 的集合。由于整型数字 integer 可以被高效压缩的特质,integer 是最适合放在 postings list 作为文档的唯一标识的,ES 会对这些存入的文档进行处理,转化成一个唯一的整型 id。
再说下这个 id 的范围,在存储数据的时候,在每一个 shard 里面,ES 会将数据存入不同的 segment,这是一个比 shard 更小的分片单位,这些 segment 会定期合并。在每一个 segment 里面都会保存最多 2^31 个文档,每个文档被分配一个唯一的 id,从0到(2^31)-1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号