Java+pdfjs实现pdf分页加载(pdf懒加载)
写在最前
因项目原因,需涉及到pdf在线浏览技术,但是少数情况下由于pdf文件过大,会导致系统加载缓慢,影响用户体验。因此,实现pdf分页浏览可有效的提高在线浏览速度。
技术栈为:SpringBoot、Vue、pdfjs、pdfbox等。
主要核心思路:前端请求时请求头附带请求范围range及读取大小,后端根据请求头返回相应的pdf文件流
现存问题:单页面数据大小无法估量,导致分片大小无法更好的设置(DEFAULT_RANGE_CHUNK_SIZE 值),分页查看出现问题(如:excel转pdf后单页面数据量大导致单页大小为xxM,此时分页单词请求大小必须大于这个值才可实现分页查看)
后端实现
注:将以下方法作为工具类,然后传入实际的pdf文件对象即可,控制层不需要做多余处理
涉及依赖
- common-io:便捷操作IO流,非必选
<!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.11.0</version> </dependency>
分页方法
/** * @Date:2022/2/10 14:00 * @Author:lngrid 分页加载pdf */ public static void loadPDFByPage(File file, HttpServletResponse response, HttpServletRequest request) { BufferedInputStream bis = null; OutputStream os = null; BufferedOutputStream bos = null; InputStream is = null; try { is = new FileInputStream(file); bis = new BufferedInputStream(is); os = response.getOutputStream(); bos = new BufferedOutputStream(os); // 下载的字节范围 int startByte, endByte, totalByte; if (request != null && request.getHeader("range") != null) { // 断点续传 String[] range = request.getHeader("range").replaceAll("[^0-9\\-]", "").split("-"); // 文件总大小 totalByte = is.available(); // 下载起始位置 startByte = Integer.parseInt(range[0]); // 下载结束位置 if (range.length > 1) { endByte = Integer.parseInt(range[1]); } else { endByte = totalByte - 1; } // 返回http状态 response.setStatus(206); } else { // 正常下载 // 文件总大小 totalByte = is.available(); // 下载起始位置 startByte = 0; // 下载结束位置 endByte = totalByte - 1; // 返回http状态 response.setHeader("Accept-Ranges", "bytes"); response.setStatus(200); } // 需要下载字节数 int length = endByte - startByte + 1; // 响应头 response.setHeader("Accept-Ranges", "bytes"); response.setHeader("Content-Range", "bytes " + startByte + "-" + endByte + "/" + totalByte); // response.setContentType("application/pdf"); response.setContentType("application/octet-stream"); response.setContentLength(length); // 响应内容 bis.skip(startByte); int len = 0; byte[] buff = new byte[1024 * 64]; while ((len = bis.read(buff, 0, buff.length)) != -1) { if (length <= len) { bos.write(buff, 0, length); break; } else { length -= len; bos.write(buff, 0, len); } } } catch (IOException e) { e.printStackTrace(); } finally { //也可使用try catch关闭IO流 IOUtils.closeQuietly(bos); IOUtils.closeQuietly(os); IOUtils.closeQuietly(bis); IOUtils.closeQuietly(is); } }
前端实现
1、引入pdfjs
http://mozilla.github.io/pdf.js/getting_started/#download
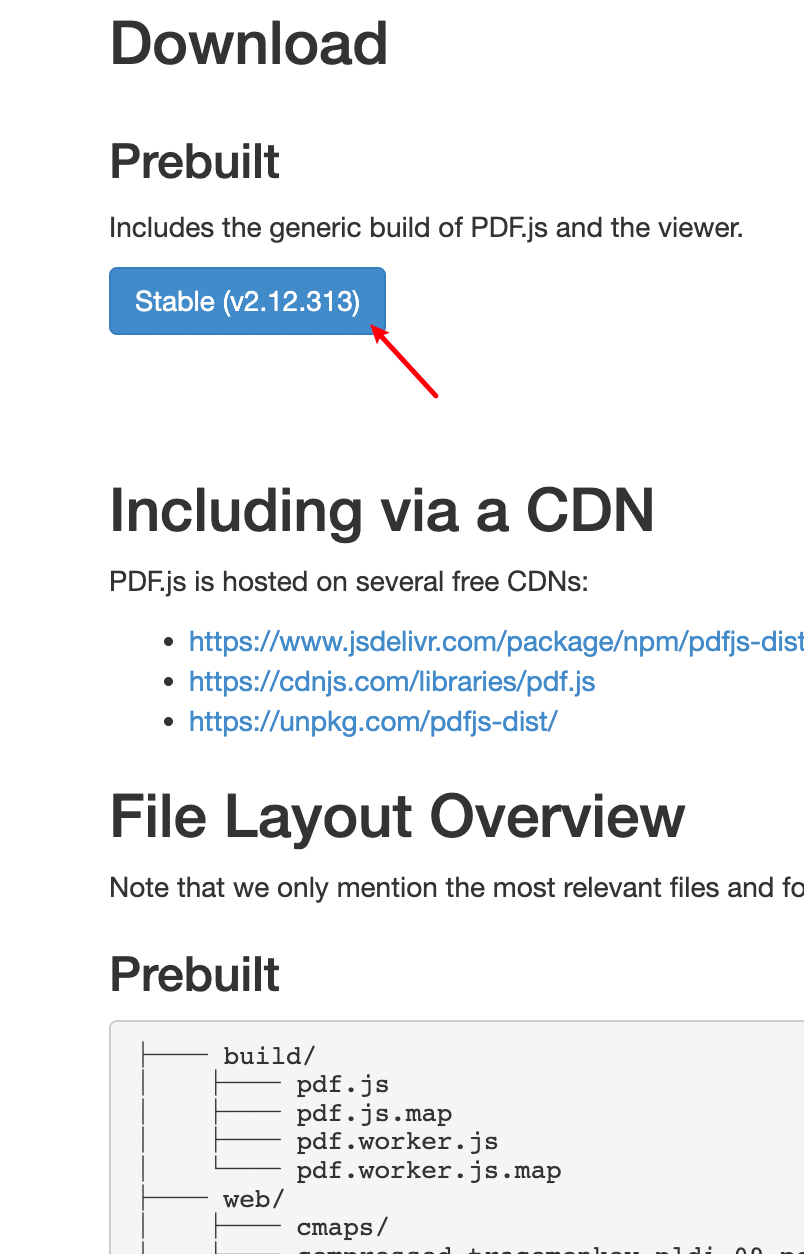
2、解压文件并存放至vue项目的public路径下,并将文件夹更名为pdfjs,方便后续调用
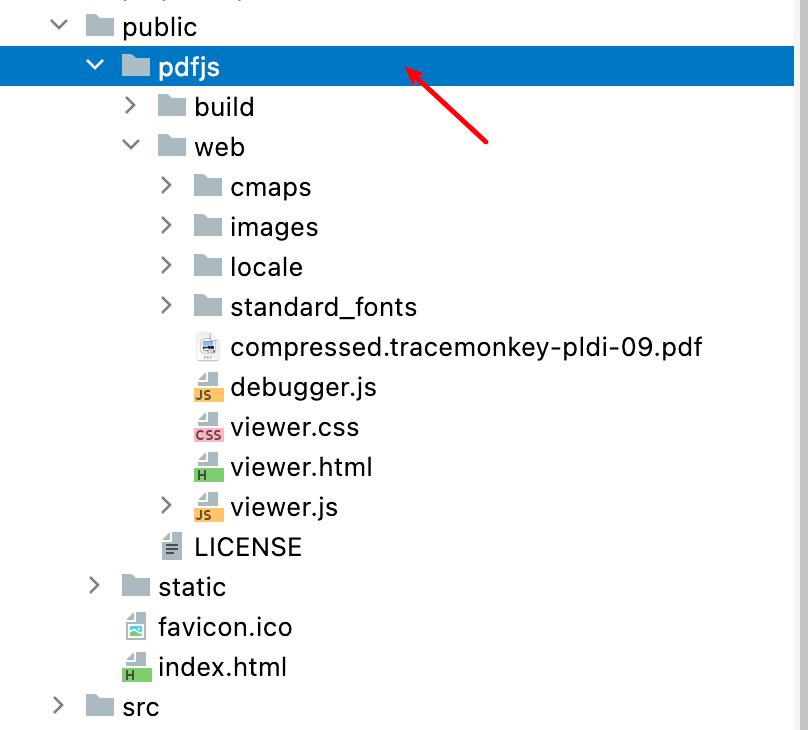
3、修改pdfjs配置项(重点)
pdfjs支持pdf分页操作,无需单独再行添加js方法,
首先,找到viewer.js,搜索disable关键词,在13968行开始的配置
修改为如下:(注释说明为个人结合网络资料及个人理解添加,非官方说明),重点为 disableAutoFetch、disableStream 均改为true,网上资料只修改第一个就行了,但始终不成功,也不知道为啥
"disableAutoFetch": true, //是否禁用自动获取,true为禁用自动获取,开启分页 "disableFontFace": false, "disableRange": false, //是否禁用range获取文件,false表示支持分页请求头 "disableStream": true, //分页关键,是否禁用流的形式加载
然后,找到build/pdf.js文件,寻找 DEFAULT_RANGE_CHUNK_SIZE 配置项,并修改为 65536*16

4、前后端请求调试
前端使用iframe标签加载pdf文件,访问路径为
/public/pdfjs/web/viewer.html?file=后端请求链接
常见问题
- disableStream:按照参考资料来讲,不需要修改此配置,所以也未曾尝试修改此配置,结果一直没有成功,后来修改后意外发现成功了,然后就是搜索此配置的实际作用,但仍未了解这个配置的实际作用。以下为网络上的一些参考描述:
- DEFAULT_RANGE_CHUNK_SIZE的问题:在实际操作时忽略了这个参数的配置,认为也影响不大,但是发现如果为默认值每次请求的大小很小,导致虽然有多个分页请求,但是pdf文件却无法成功加载,故尝试修改为*16后,发现单次请求响应大小为1M,pdf也能成功加载了。
参考链接
-
Lazy load :How to display multiple pdf documents as one with pdf.js?
-
Getting disableAutoFetch resp. disableStream working... #7937

 浙公网安备 33010602011771号
浙公网安备 33010602011771号