
Yandex Big Data Essentials Week1 Scaling Distributed File System
GFS Key Components
- components failures are a norm
- even space utilisation
- write-once-read-many
GFS and Hadoop Distributed File System
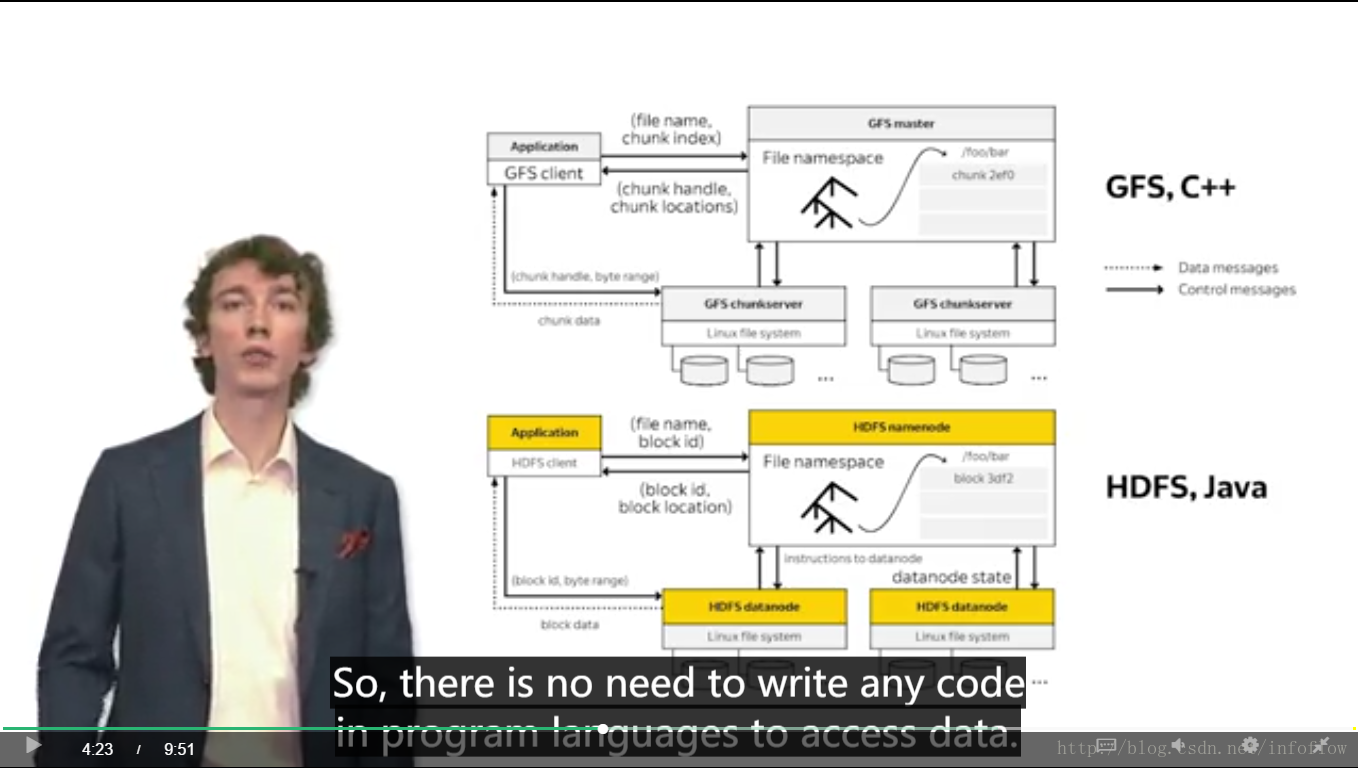
GFS主要分为:Application 、Master、ChannelServer
hdfs主要分为:Appllcation 、 NameNode 、DataNode三部分
how to read file from hdfs
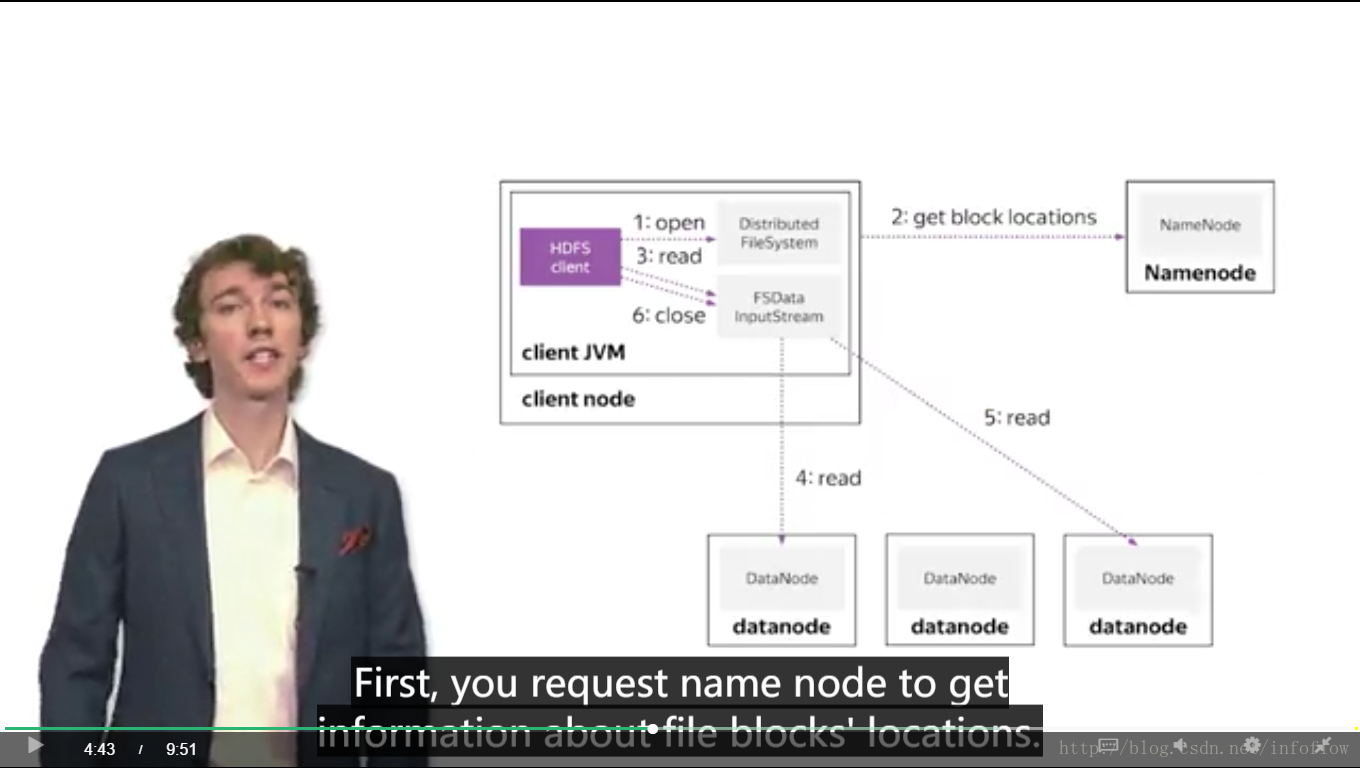
HDFS client 运行在client node 上的client jvm上。
读取文件的流程
- 打开分布式文件系统上的文件
- 从NameNode处取的文件块的位置
- HDFS client将块位置信息传给FSDataInputStream
- FSDataInputStream再从相应的DataNode里面读取其中一个块数据
- FSDataInputStream再从相应的DataNode里面读取另一个块数据
- 关闭FSDataInputStream
写入文件的流程

hdfs client 运行在client jvm上,client jvm运行在client jvm上。
写入文件的流程:
1. HDFS client 在Distributed FileSystem上创建文件
2. DistributedFileSystem 在NameNode上create一个文件
3. HDFS client 通过FSDataInputStream向datanode发送write packet
4. 至少三个datanode组成Pipeline of datanodes写入多个副本
5. datanode向FSDataInpuStream发送ack packet
6. 关闭
In DFS,you can “append” into file,but cannot “modify” a file in the middle. Why?
DFS的核心特性write once read many time 描述了一种数据存储策略。信息一旦写入就不能修改,因为修改操作需要对对底层的存储结构进行修改。如果需要修改分布式文件系统(例如hdfs)中的文件,可以写一份新的同样文件名的数据。旧的文件在hdfs在整理数据的时候会丢弃。
HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号