多视图聚类总结
MVC的两个重要原则,即互补原则和共识原则。
互补原则:该原则规定,为了更全面、更准确地描述数据对象,应该使用多个视图。在多视图数据的上下文,每个视图都足以完成特定的知识发现任务。然而,不同的视图通常包含相互补充的信息。例如,在图像处理领域,每幅图像都由不同类型的特征来描述,如lbp、sift和hog,其中lbp是一种强大的纹理特征,sift对图像的光照、噪声和旋转具有鲁棒性,而hog对边缘信息敏感。因此,有必要利用这些相互补充的信息来描述这些数据对象,并对内部集群提供更深入的见解。
共识原则:这一原则旨在最大限度地保持多个不同观点的一致性。
Co-training style algorithms
在多视角共识的基础上,产生了协同训练式算法。这类方法旨在最大限度地在所有观点上达成共识,并达成最广泛的共识。使用交替训练算法,通过使用先验信息或相互学习知识,最大限度地提高不同视图的一致性。
注意,协同训练的成功主要取决于三个假设:
(1)充分性:每个视图本身就足以完成学习任务;
(2)兼容性:目标函数导出对两个视图中同时出现的高概率特征的相同预测;
(3)条件独立性:所有视图都提供学习标签:有条件独立。
然而,在实践中,通常很难满足条件独立性假设。
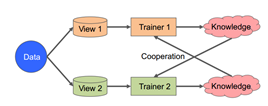
协同训练的一般过程
Multi-kernel learning
为了提高线性核、多项式核和高斯核等可能的核函数的搜索空间容量,最初开发了多核学习,以实现良好的泛化。由于多核学习的内核自然对应不同的视图,因此多核学习在处理多视图数据方面得到了广泛的应用。多核学习方法的一般过程如图4所示,其中不同的预定义内核用于处理不同的视图。然后将这些核线性地或非线性地组合在一起,得到一个统一的核。在MVC环境下,基于多核学习的MVC为了提高聚类性能,打算对一组预先定义的内核进行优化组合。在这种方法中,一个重要的问题是找到一种选择合适的内核函数的方法,并将这些内核进行优化组合。
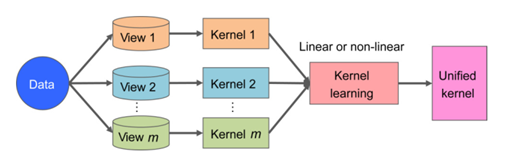
多核学习的一般过程
Graph-based MvC
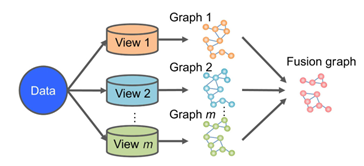
基于图聚类的一般过程
Network-based MvC
大多数基于图的MVC方法通常都假定同一组数据对象可用于不同的视图。因此,不同视图中数据对象之间的关系是一对一的关系。然而,在许多现实生活应用中,如社会网络、文献引用网络和生物交互网络,数据是从不同的领域收集的,一个领域中的一个对象可能对应于另一个领域中的多个对象,从而导致许多映射关系。用网络而不是图来表示这些关系可能更合适。这是区分基于网络的MVC和基于图形的MVC的主要原因。
Spectral-based MvC
谱聚类是一种典型的数据聚类模型。其基本思想是在任意一对对象之间形成一个成对的亲和矩阵,将该亲和矩阵归一化,并计算该归一化亲和矩阵(即图拉普拉斯)的特征向量。结果表明,归一化图拉普拉斯的第二特征向量是二元向量解的松弛。
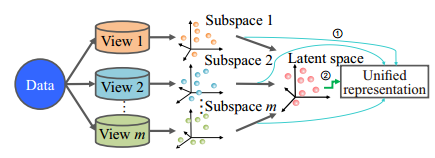
多视图子空间聚类的一般过程
Multi-task multi-view clustering
MVC利用不同视图之间的一致性和互补性来实现更好的集群质量,如上所述。另一个概念,即多任务聚类(属于多任务学习领域),共同执行多个相关任务,并利用这些任务之间的关系来增强单视图数据的聚类性能。通过继承MVC和多任务集群的特性,多任务多视图聚类将每个视图数据处理为一个或多个任务,如下图所示。近年来,这一点受到了一些关注。 其主要挑战包括找到一种方法来对每个视图上的任务内(在任务内)集群进行建模,以及一种利用多任务和多视图关系的方法,同时将任务间(在任务之间)的知识相互转移。

多任务聚类模型的图形表示
Publically Available Datasets
3Sources Dataset:一个多视图文本语料库,由三个在线新闻服务的新闻文章构成。该存储库还包含多视图Twitter数据集、用于社交网络发现的Twitter数据集以及BBC和BBCSport数据集,这两个数据集是源自BBC新闻的合成文本数据集。
WebKb Datasets:这些数据集包含从四所大学的计算机科学系收集的网页数据,即四个多视图数据集。
Newsgroup Datasets:数据集有3个不同的预处理子集。此外,该存储库还具有Reuters多语言数据集、CORA数据集、Citeseer数据集、Movies617数据集和Mini WEKB数据集。
Wikipedia Article Dataset:收集的数据集是从维基百科的特色文章集中选择的部分。它们有完整的或小的版本。
Handwritten Digit Dataset:它包括来自UCI存储库的手写数字(0-9)的特征。
100leaves Dataset:包含16种不同的植物叶片,每种都有100个样本。对于每个样本,给出了形状描述符、细比例边界和纹理直方图。
Corel Images Dataset:此数据集由从COREL图像集合中提取的图像功能组成。它提供四组特征,即颜色直方图、颜色直方图布局、颜色矩和共现纹理。
NUS-WIDE Dataset:从这些图像中提取的具有六种低级特征的Web图像数据集。
YouTube Video Dataset:此数据集包含大约1.2105个实例,其中每个实例由13种类型的功能描述,并且还具有类信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号