知识蒸馏基本知识及其实现库介绍
1 前言
知识蒸馏,其目的是为了让小模型学到大模型的知识,通俗说,让student模型的输出接近(拟合)teacher模型的输出。所以知识蒸馏的重点在于拟合二字,即我们要定义一个方法去衡量student模型和teacher模型接近程度,说白了就是损失函数。
为什么我们需要知识蒸馏?因为大模型推理慢难以应用到工业界。小模型直接进行训练,效果较差。
下面介绍四个比较热门的蒸馏文章,这四个本人均有实践,希望能帮到大家。
2 知识蒸馏的开山之作
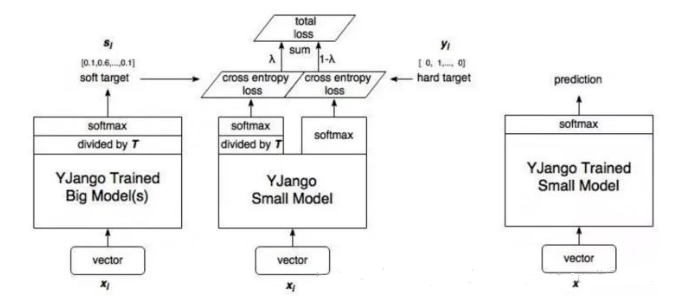
Hinton 在论文: Distilling the Knowledge in a Neural Network 提出了知识蒸馏的方法。网上关于这方面的资料实在是太多了,我就简单总结下吧。
损失函数:$$Loss = aL_{soft} + (1-a)L_{hard}$$
其中\(L_{soft}\)是StudentModel和TeacherModel的输出的交叉熵,\(L_{hard}\)是StudentModel输出和真实标签的交叉熵。
再细说一下\(L_{soft}\)。我们知道TeacherModel的输出是经过Softmax处理的,指数e拉大了各个类别之间的差距,最终输出结果特别像一个one-hot向量,这样不利于StudentModel的学习,因此我们希望输出更加软一些。因此我们需要改一下softmax函数:
显然T越大输出越软。这样改完之后,对比原始softmax,梯度相当于乘了\(1/T^2\),因此\(L_{soft}\)需要再乘以\(T^2\)来与\(L_{hard}\)在一个数量级上。
算法的整体框架图如下:(图片来自https://blog.csdn.net/nature553863/article/details/80568658)
3 TinyBert
3.1 基本思路介绍
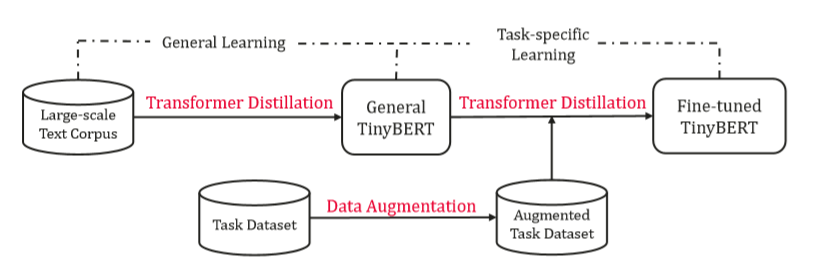
说到对Bert的蒸馏, 首先想到的方法就是用微调好的Bert作为TeacherModel去训练一个StudentModel,这正是TinyBert的做法。那么下面的问题就是选取什么模型作为StudentModel,这个已经有一些尝试了,比如有人使用BiLSTM,但是更多的人还是继续使用了Bert,只不过这个Bert会比原始的Bert小。在TinyBert中,StudentModel使用的是减少了embedding size、hidden size和num hidden layers的小bert。
那么怎么初始化StudentModel呢?最简单的办法就是随机化模型参数,但是更好的方法是用预训练模型,因此我们需要一个预训练的StudentModel。TinyBert的做法是用预训练好的Bert蒸馏出一个预训练好的StudentModel。
Ok,TinyBert基本讲完了,简单总结下,TinyBert一共分为两步:
- 用pretrained bert蒸馏一个pretrained TinyBert
- 用fine-tuned bert蒸馏一个fine-tuned TinyBert( 它的初始化参数就是第一步里pretrained TinyBert)
![]()
3.2 损失函数
下面说一说TinyBert的损失函数。
公式如下:
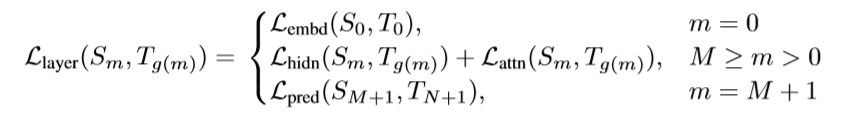
解释下这个公式:
- \(m\):整数,0到StudentModel层数之间
- \(S_m\):StudentModel第m层的输出
- \(g(m)\):映射函数,实际意义是让StudentModel的第m层学习TeacherModel第g(m)层的输出
- \(T_{g(m)}\):TeacherModel的第g(m)层的输出
- \(M\):StudentModel隐层数量,那么StudentModel第M+1层就是预测层的输出了(logits)
- \(L_{embd}(S_0,T_0)\):word embedding层的损失函数,用的是MSE
- \(L_{hidden}和L_{attn}\):hidden层和attention层的损失函数,都是MSE
- \(L_{pred}\):预测层损失函数,用的交叉熵,其他文献也有用KL-Distance的,其实反向传播的时候都一样。
再补充一句:在进行蒸馏的时候,会先进行隐层蒸馏(即m<=M),然后再执行m=M+1时的蒸馏。
总结一下,有助于大家理解:TinyBERT在蒸馏的时候,不仅要让StudentModel学到最后一层的输出,还要学到中间几层的输出。换言之,StudentModel的某一隐层可以学到TeacherModel若干隐层的输出。感觉蒸馏的粒度比较细,我觉得可以叫做LayerBasedDistillation。
3.3 实战经验
- 在硬件和数据有限的条件下,我们很难做预训练模型的蒸馏,但是可以借鉴TinyBERT的思路,直接做TaskSpecific的蒸馏,至于如何初始化模型,我有两个建议:要不直接拿原始Teacher模型初始化,要不找一个别人预训练好的小模型进行初始化。我直接用的RBT3模型初始化,效果很好。
- 蒸馏完StudentModel,一定要测StudentModel的泛化能力。
- 灵活一些,蒸馏学习目前没有一个统一的方法,有很多地方可以自己改一改试一试。
4 DistilBert
4.1 基本思路
说完了TinyBert,想再和大家聊一聊DistilBert,DistilBert要比TinyBert简单不少,我就少用些文字,DistilBert使用预训练好的Bert作为TeacherModel训练了一个StudentModel,这里的StudentModel就是层数少的Bert,注意这里得到的DistilBERT本质上还是一个预训练模型,因此用到具体下游任务上时,还是需要用专门的数据去微调,这里就是纯粹的微调,不需要考虑再用蒸馏学习辅助。HuggingFace已经提供了若干蒸馏好的预训练模型,大家直接拿过来当Bert用就行了。
4.2 损失函数
DistillBERT的损失函数:\(L_{ce} + L_{mlm} + L_{cos}\)。
- \(L_{ce}\),StudentModel和TeacherModel logits的交叉熵
- \(L_{mlm}\),StudentModel中遮挡语言模型的损失函数
- \(L_{cos}\),StudentModel和TeacherModel hidden states的余弦损失函数,注意在TinyBERT里用的是MSE,而且还考虑了attention的MSE。
5 BERT-of-Theseus
这个准确的来说不是知识蒸馏,但是它确实减小了模型体积,而且思路和TinyBERT、DistillBERT都有类似,因此就放到这里讲了。这个思路非常优雅,它通过随机使用小模型的一层替换大模型中若干层,来完成训练。我来举一个例子:假设大模型是input->tfc1->tfc2->tfc3->tfc4->tfc5->tfc6->output,然后再定义一个小模型input->sfc1->sfc2->sfc3->output。再训练过程中还是要训练大模型,只是在每一步中,会随机的将(tfc1,tfc2),(tfc3,tfc4),(tfc5,tfc6)替换为sfc1,sfc2,sfc3,而且随着训练的进行,替换的概率不断变大,因此最后就是在训练一个小模型。
放一张图便于大家理解
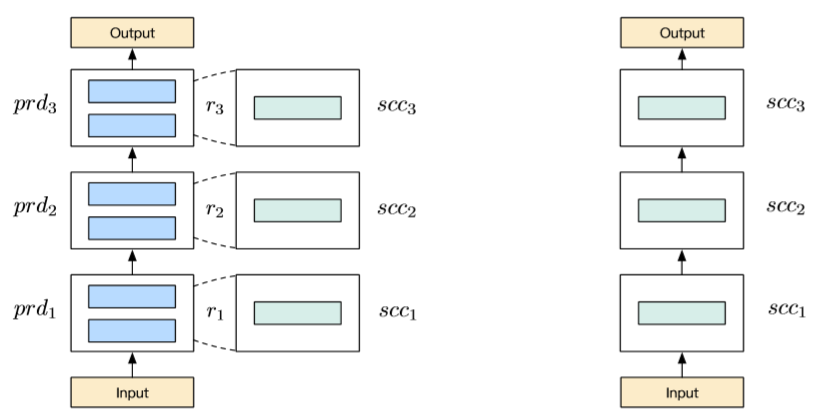
方式优雅,作者提供了源码,强烈推荐大家用一用。
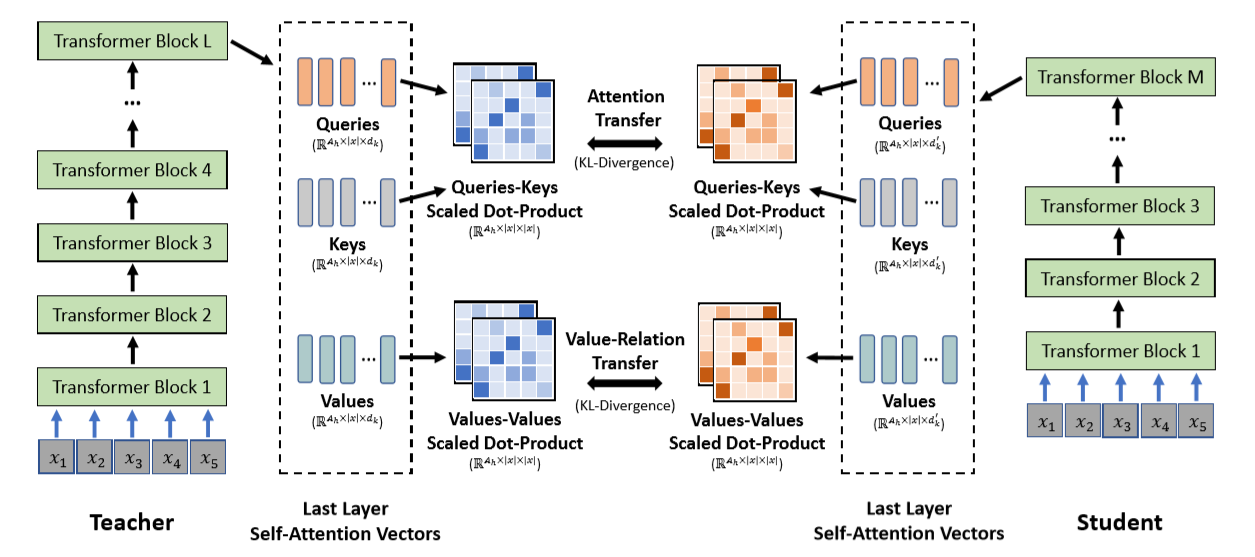
6 MiniLM
刚刚发布的一篇新论文, 也是关于BERT蒸馏的,我简单总结下三个创新点:
- 先用TeacherModel蒸馏一个中等模型,再用中等模型蒸馏一个较小的StudentModel。只有在StudentModel很小的时候才会这么做。
- 只对最后一个隐层做蒸馏,作者认为这样可以让StudentModel有更大的自由空间,而且这样对StudentModel架构的要求就变得宽松了
- 对于最后一个隐层主要是对attention权重做学习,具体可以去看论文
放一下图以便大家理解:
7 知识蒸馏通用框架
7.1 KnowledgeDistillation库
本人实现了一个基于Pytorch的知识蒸馏框架,有兴趣的朋友可以试一试。该框架尽可能抽象了多层模型的蒸馏方法,可以实现TInyBERT、DistillBERT等算法。后续在维护过程中发现知识蒸馏还不够成熟,经常出现新的蒸馏算法,没办法制定一个统一的框架把各类算法集成进去。因此本人稍微调整该库,将该库分为两个部分:
- 基于多层模型的知识蒸馏框架:便于新手阅读源码、学习入门(不再维护)
- examples:存放各类新的知识蒸馏算法范例代码(继续维护)
欢迎给位上传新的知识蒸馏算法示例代码,示例代码尽量简洁易懂,便于执行,最好是算法作者没有提供源码的。项目地址:
Pypi:https://pypi.org/project/KnowledgeDistillation/
Github:https://github.com/DunZhang/KnowledgeDistillation
给大家提供一个使用基于多层模型的知识蒸馏框架的范例代码,使用12层bert蒸馏3层bert,使用TinyBERT的损失函数,代码完整可以直接运行,不需要外部数据:
# import packages
import torch
import logging
import numpy as np
from transformers import BertModel, BertConfig
from torch.utils.data import DataLoader, RandomSampler, TensorDataset
from knowledge_distillation import KnowledgeDistiller, MultiLayerBasedDistillationLoss
from knowledge_distillation import MultiLayerBasedDistillationEvaluator
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# Some global variables
train_batch_size = 40
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
learning_rate = 1e-5
num_epoch = 10
# define student and teacher model
# Teacher Model
bert_config = BertConfig(num_hidden_layers=12, hidden_size=60, intermediate_size=60, output_hidden_states=True,
output_attentions=True)
teacher_model = BertModel(bert_config)
# Student Model
bert_config = BertConfig(num_hidden_layers=3, hidden_size=60, intermediate_size=60, output_hidden_states=True,
output_attentions=True)
student_model = BertModel(bert_config)
### Train data loader
input_ids = torch.LongTensor(np.random.randint(100, 1000, (100000, 50)))
attention_mask = torch.LongTensor(np.ones((100000, 50)))
token_type_ids = torch.LongTensor(np.zeros((100000, 50)))
train_data = TensorDataset(input_ids, attention_mask, token_type_ids)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=train_batch_size)
### Train data adaptor
### It is a function that turn batch_data (from train_dataloader) to the inputs of teacher_model and student_model
### You can define your own train_data_adaptor. Remember the input must be device and batch_data.
### The output is either dict or tuple, but must be consistent with you model's input
def train_data_adaptor(device, batch_data):
batch_data = tuple(t.to(device) for t in batch_data)
batch_data_dict = {"input_ids": batch_data[0],
"attention_mask": batch_data[1],
"token_type_ids": batch_data[2], }
# In this case, the teacher and student use the same input
return batch_data_dict, batch_data_dict
### The loss model is the key for this generation.
### We have already provided a general loss model for distilling multi bert layer
### In most cases, you can directly use this model.
#### First, we should define a distill_config which indicates how to compute ths loss between teacher and student.
#### distill_config is a list-object, each item indicates how to calculate loss.
#### It also defines which output of which layer to calculate loss.
#### It shoulde be consistent with your output_adaptor
distill_config = [
# means that compute a loss by their embedding_layer's embedding
{"teacher_layer_name": "embedding_layer", "teacher_layer_output_name": "embedding",
"student_layer_name": "embedding_layer", "student_layer_output_name": "embedding",
"loss": {"loss_function": "mse_with_mask", "args": {}}, "weight": 1.0
},
# means that compute a loss between teacher's bert_layer12's hidden_states and student's bert_layer3's hidden_states
{"teacher_layer_name": "bert_layer12", "teacher_layer_output_name": "hidden_states",
"student_layer_name": "bert_layer3", "student_layer_output_name": "hidden_states",
"loss": {"loss_function": "mse_with_mask", "args": {}}, "weight": 1.0
},
{"teacher_layer_name": "bert_layer12", "teacher_layer_output_name": "attention",
"student_layer_name": "bert_layer3", "student_layer_output_name": "attention",
"loss": {"loss_function": "attention_mse_with_mask", "args": {}}, "weight": 1.0
},
{"teacher_layer_name": "pred_layer", "teacher_layer_output_name": "pooler_output",
"student_layer_name": "pred_layer", "student_layer_output_name": "pooler_output",
"loss": {"loss_function": "mse", "args": {}}, "weight": 1.0
},
]
### teacher_output_adaptor and student_output_adaptor
### In most cases, model's output is tuple-object, However, in our package, we need the output is dict-object,
### like: { "layer_name":{"output_name":value} .... }
### Hence, the output adaptor is to turn your model's output to dict-object output
### In my case, teacher and student can use one adaptor
def output_adaptor(model_output):
last_hidden_state, pooler_output, hidden_states, attentions = model_output
output = {"embedding_layer": {"embedding": hidden_states[0]}}
for idx in range(len(attentions)):
output["bert_layer" + str(idx + 1)] = {"hidden_states": hidden_states[idx + 1],
"attention": attentions[idx]}
output["pred_layer"] = {"pooler_output": pooler_output}
return output
# loss_model
loss_model = MultiLayerBasedDistillationLoss(distill_config=distill_config,
teacher_output_adaptor=output_adaptor,
student_output_adaptor=output_adaptor)
# optimizer
param_optimizer = list(student_model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = torch.optim.Adam(params=optimizer_grouped_parameters, lr=learning_rate)
# evaluator
# this is a basic evalator, it can output loss value and save models
# You can define you own evaluator class that implements the interface IEvaluator
evaluator = MultiLayerBasedDistillationEvaluator(save_dir="save_model", save_step=1000, print_loss_step=20)
# Get a KnowledgeDistiller
distiller = KnowledgeDistiller(teacher_model=teacher_model, student_model=student_model,
train_dataloader=train_dataloader, dev_dataloader=None,
train_data_adaptor=train_data_adaptor, dev_data_adaptor=None,
device=device, loss_model=loss_model, optimizer=optimizer,
evaluator=evaluator, num_epoch=num_epoch)
# start distillate
distiller.distillate()
7.2 TextBrewer库
再介绍一个知识蒸馏库TextBrewer,该库由哈工大实现,和本人的库相比实现算法更多,运行更为稳定,推荐大家使用。
Github地址:https://github.com/airaria/TextBrewer
在这里同样的也提供一个完整可运行的代码,且不需要任何外部数据:
import torch
import numpy as np
import pickle
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig, DistillationConfig
from transformers import BertConfig, BertModel
from torch.utils.data import DataLoader, RandomSampler, TensorDataset
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
## 定义模型
bert_config = BertConfig(num_hidden_layers=12, output_hidden_states=True, output_attentions=True)
teacher_model = BertModel(bert_config).to(device)
bert_config = BertConfig(num_hidden_layers=3, output_hidden_states=True, output_attentions=True)
student_model = BertModel(bert_config).to(device)
# optimizer
param_optimizer = list(student_model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = torch.optim.Adam(params=optimizer_grouped_parameters, lr=2e-5)
### data
input_ids = torch.LongTensor(np.random.randint(100, 1000, (100000, 64)))
attention_mask = torch.LongTensor(np.ones((100000, 64)))
token_type_ids = torch.LongTensor(np.zeros((100000, 64)))
train_data = TensorDataset(input_ids, attention_mask, token_type_ids)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=16)
# Define an adaptor for translating the model inputs and outputs
# 整合成蒸馏器需要的数据格式
# key需要是固定的???
def bert_adaptor(batch, model_outputs):
last_hidden_state, pooler_output, hidden_states, attentions = model_outputs
hidden_states = list(hidden_states)
hidden_states.append(pooler_output)
output = {"inputs_mask": batch[1],
"attention": attentions,
"hidden": hidden_states}
return output
# Training configuration
train_config = TrainingConfig(gradient_accumulation_steps=1,
ckpt_frequency=10,
ckpt_epoch_frequency=1,
log_dir='logs',
output_dir='saved_models',
device='cuda')
# Distillation configuration
# Matching different layers of the student and the teacher
# 重要,如何蒸馏的定义
# 不支持自定义损失函数
# 不支持CLS LOSS,但是可以强行写在hidden loss里面
distill_config = DistillationConfig(
intermediate_matches=[
{'layer_T': 0, 'layer_S': 0, 'feature': 'hidden', 'loss': 'hidden_mse', 'weight': 1}, # embedding loss
{'layer_T': 4, 'layer_S': 1, 'feature': 'hidden', 'loss': 'hidden_mse', 'weight': 1}, # hidden loss
{'layer_T': 8, 'layer_S': 2, 'feature': 'hidden', 'loss': 'hidden_mse', 'weight': 1},
{'layer_T': 12, 'layer_S': 3, 'feature': 'hidden', 'loss': 'hidden_mse', 'weight': 1},
{'layer_T': 3, 'layer_S': 0, 'feature': 'attention', 'loss': 'attention_mse', 'weight': 1}, # attention loss
{'layer_T': 7, 'layer_S': 1, 'feature': 'attention', 'loss': 'attention_mse', 'weight': 1},
{'layer_T': 11, 'layer_S': 2, 'feature': 'attention', 'loss': 'attention_mse', 'weight': 1},
{'layer_T': 12, 'layer_S': 3, 'feature': 'hidden', 'loss': 'hidden_mse', 'weight': 1}, # 其实是CLS loss
]
)
# Build distiller
distiller = GeneralDistiller(
train_config=train_config, distill_config=distill_config,
model_T=teacher_model, model_S=student_model,
adaptor_T=bert_adaptor, adaptor_S=bert_adaptor)
# Start!
# callbacker 可以在dev上进行评估
# 注意存的是state_dict
with distiller:
distiller.train(optimizer=optimizer, scheduler=None, dataloader=train_dataloader, num_epochs=10, callback=None)
8 其它加速BERT的方法
还有很多其他加速BERT的方法,我就不细说了,有兴趣的可以研究下:
- 提升硬件,目前看性价比较高的是RTX30系列显卡
- 提升深度学习框架版本必然能提升训练和推理速度。比如高版本的TensorFlow会支持mkldnn,AVX指令集。
- ONNXRuntime(这个主要用在推理中)
- BERT的量化
- StructedDropout了解一下,但是这个最好用在预训练上,那不然效果不好,ICLR2020的最新论文:reducing transformer depth on demand with structured dropout
文章可以转载, 但请注明出处:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号