人工智能实战第七次作业(1)_张绍恺
0.导航
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 人工智能实战 |
| 这个作业的要求在哪里 | 人工智能实战第七次作业(个人) |
| 我在这个课程的目标是 | 开拓视野,积累AI实战经验 |
| 这个作业在哪个具体方面帮助我 | 了解OpenPAI和NNI等AI模型在线训练平台 |
1.作业要求
-
学习OpenPAI的使用:
学习文档,并提交OpenPAI job,将体验心得形成博客,选题方向可以是:- 介绍OpenPAI,以及使用心得体会,给出文档或者功能等方面的意见和建议
- 将OpenPAI与其他机器学习平台进行对比或评测
-
学习NNI的使用
学习文档,并使用NNI进行调参或架构调整,将体验心得形成博客,选题方向可以是:- 介绍NNI,自己的心得体会,为NNI提建议或问题,包括文档功能等
- 将NNI与自己了解的其他自动机器学习工具比较或评测
2.具体作业内容
-
OpenPAI简介
OpenPAI是由微软亚洲研究院和微软(亚洲)互联网工程院联合研发的,支持多种深度学习、机器学习及大数据任务,可提供大规模GPU集群调度、集群监控、任务监控、分布式存储等功能,且用户界面友好,易于操作。 -
OpenPAI使用流程和心得体会
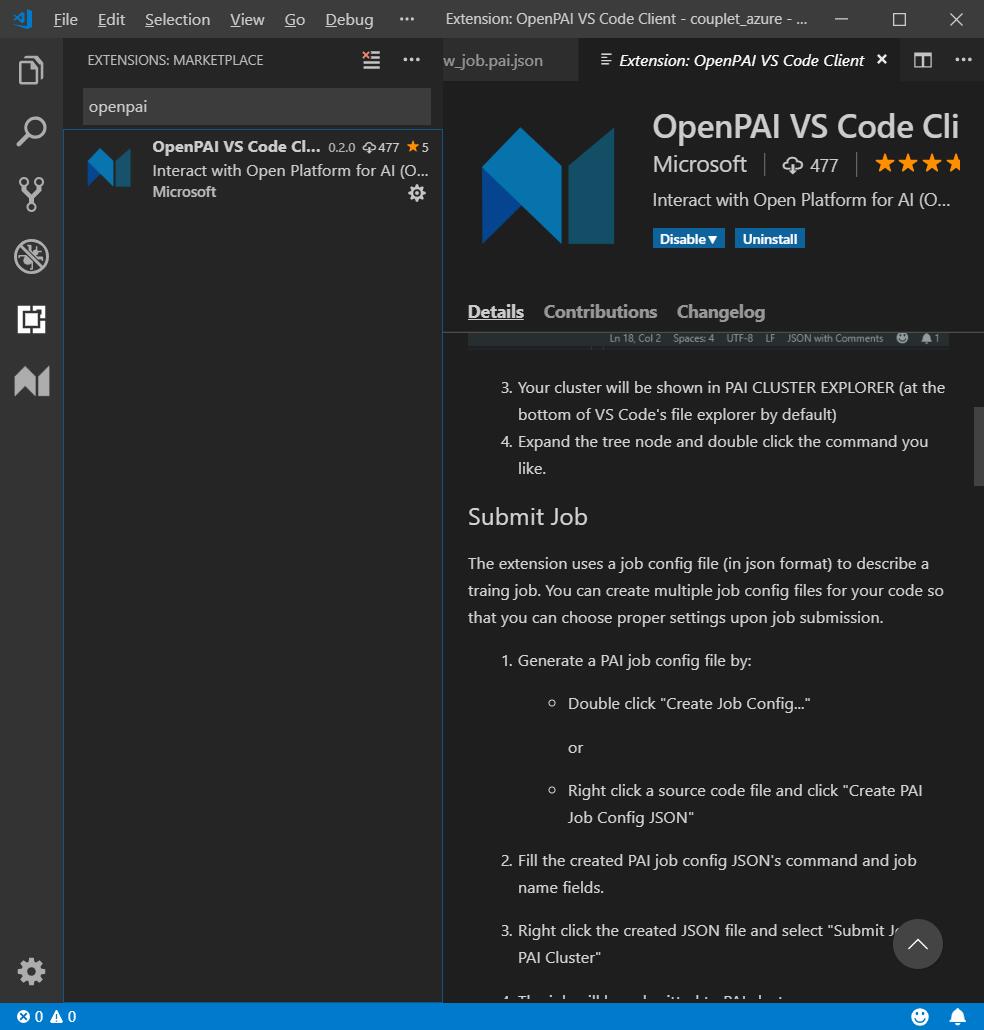
根据操作手册的指引按流程操作了一遍,其大致步骤如下- 在VSCode中搜索OpenPAI插件并安装
- 添加集群
安装完OpenPAI VS Code Client插件后,在界面左下角出现PAI CLUSTER EXPLORER,点击右上角的“+”按钮,创建OpenPAI集群。在VS Code界面上部的弹出窗,填写集群IP并回车。之后,会弹出的集群配置文件,填写"username"和”password”并保存配置。 - 上传数据
用户在训练模型时,如果需要使用一些不能自动下载的数据,需要提前上传到Azure-PAI Cluster的hdfs上。训练时,再从hdfs下载数据到实际训练使用的container中
- 本次作业中,我们已将训练时使用的数据上传至data/目录下,将程序依赖文件上传至code/目录下,训练结果将传回output/目录下。
- 编写程序
__init__.py: 用于调用filetrans.py
filetrans.py:实现hdfs和docker container之间的数据传输操作。主要实现数据download和upload
run_samples.py:实现整个训练过程,包括下载数据,训练模型,上传结果模型
train.sh: 训练模型的脚本命令 - 配置文件
在PAI Cluster 40.73.28.255中,双击Create Job Config…创建配置文件。修改配置文件内容以符合训练需求。本作业中使用的配置文件内容如下:
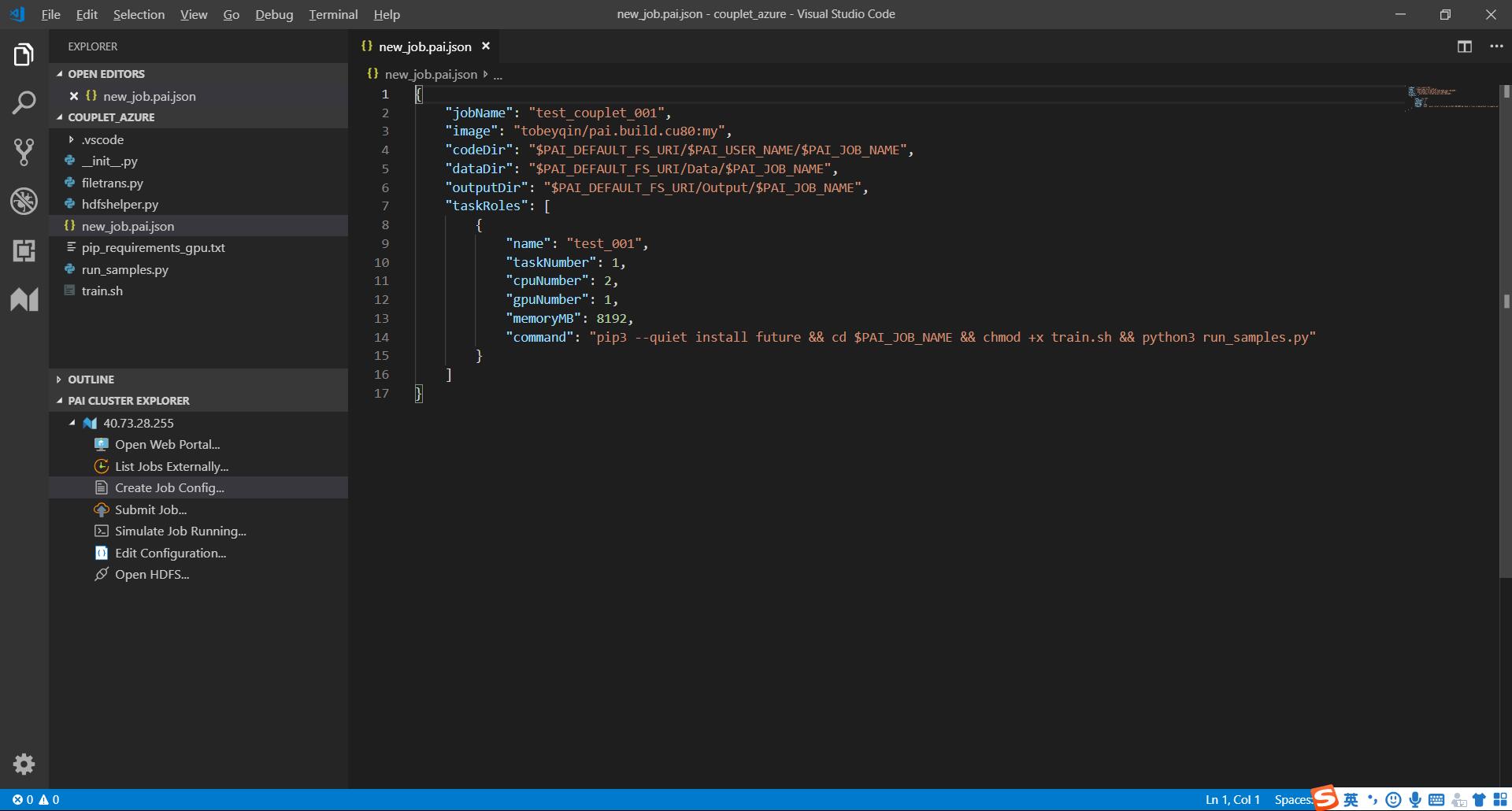
配置完成后,在配置文件中,单机鼠标右键,选择Submit Job to PAI Cluster,提交任务。 - 查看状态
双击Open Web Portal,打开如下网页对提交的任务状态进行查看
在Jobs一栏中可以看到正在运行和已经运行完毕的各个任务,找到自己的Job点击进入

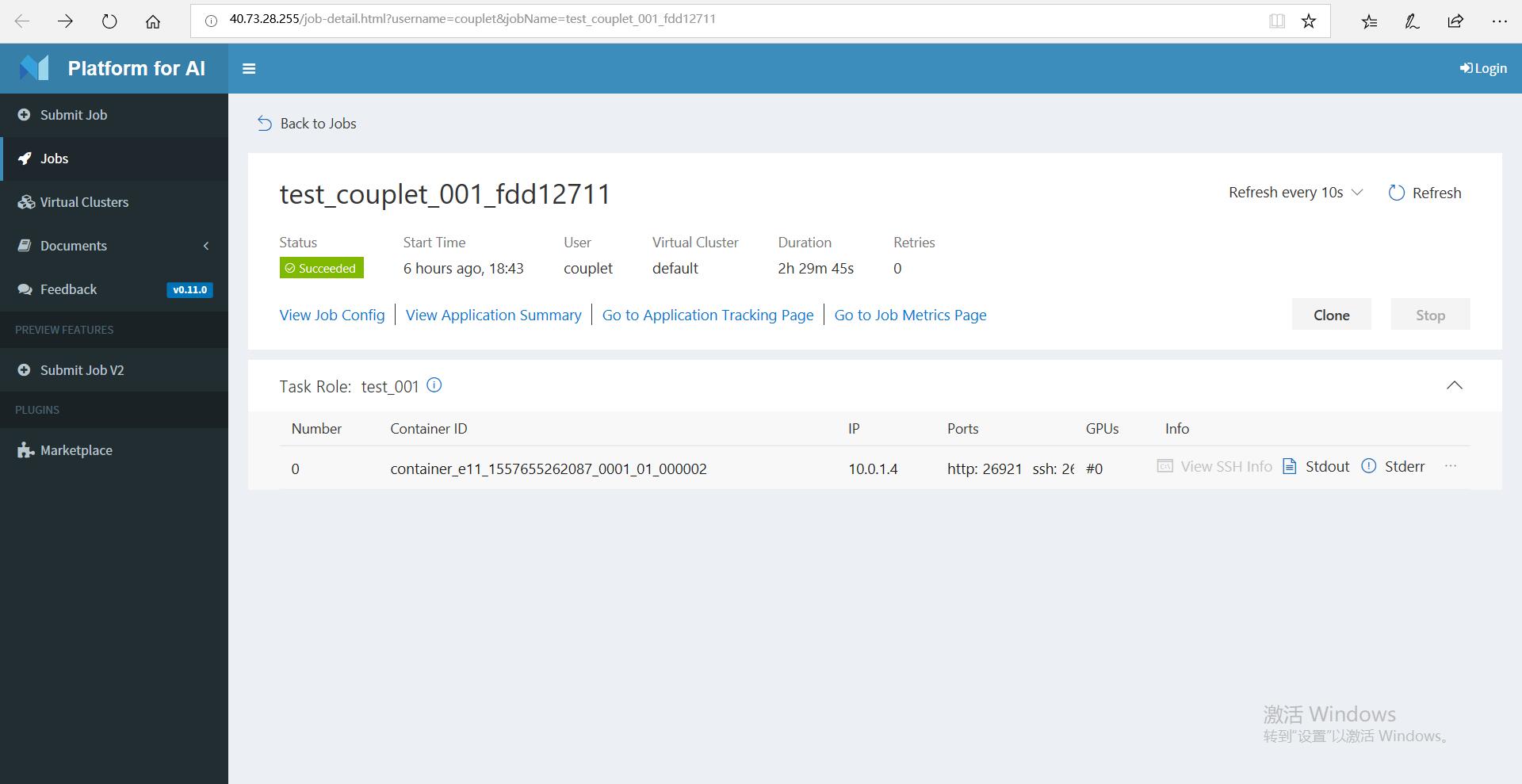
在stdout中可以查看运行log信息
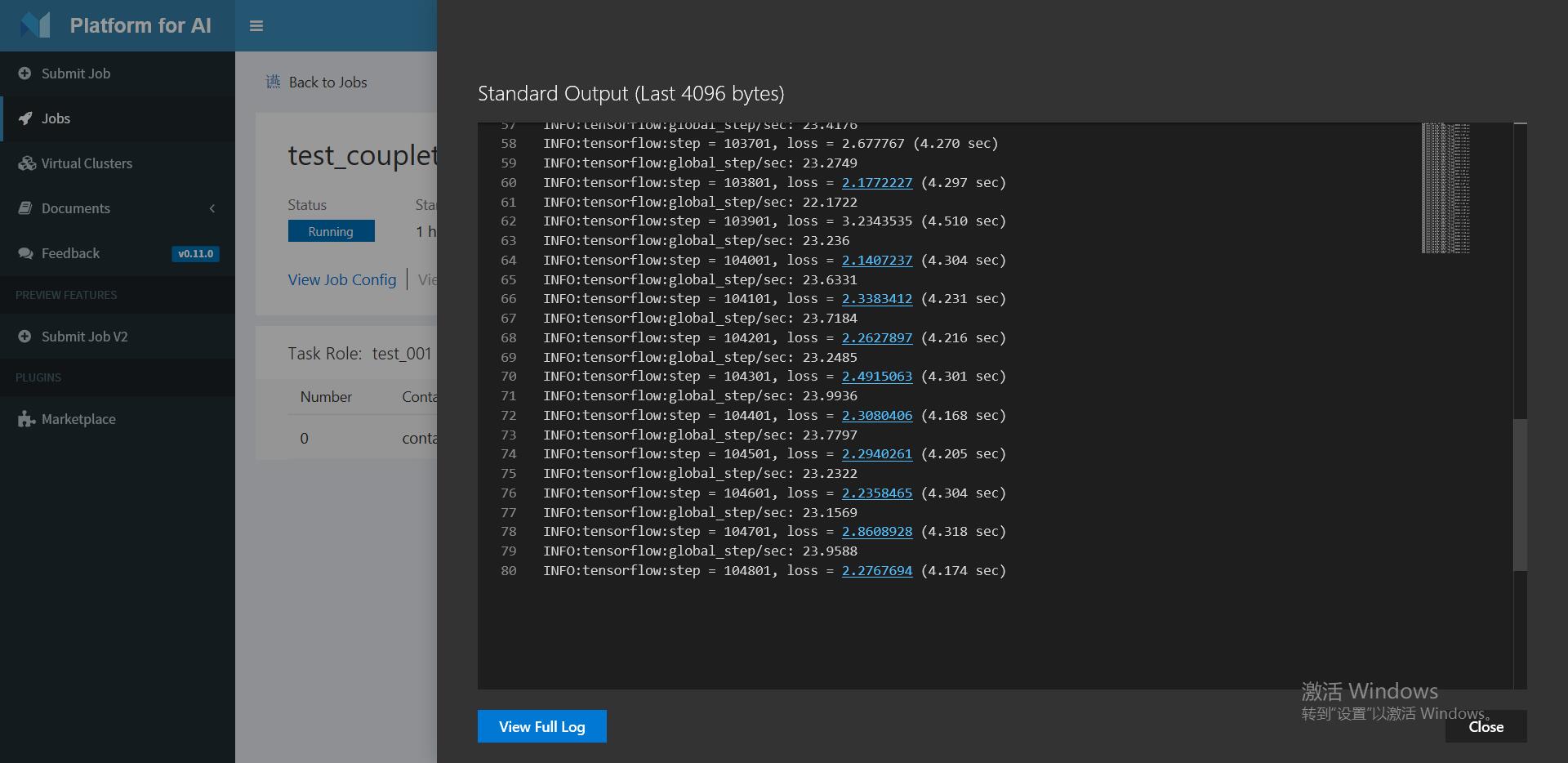
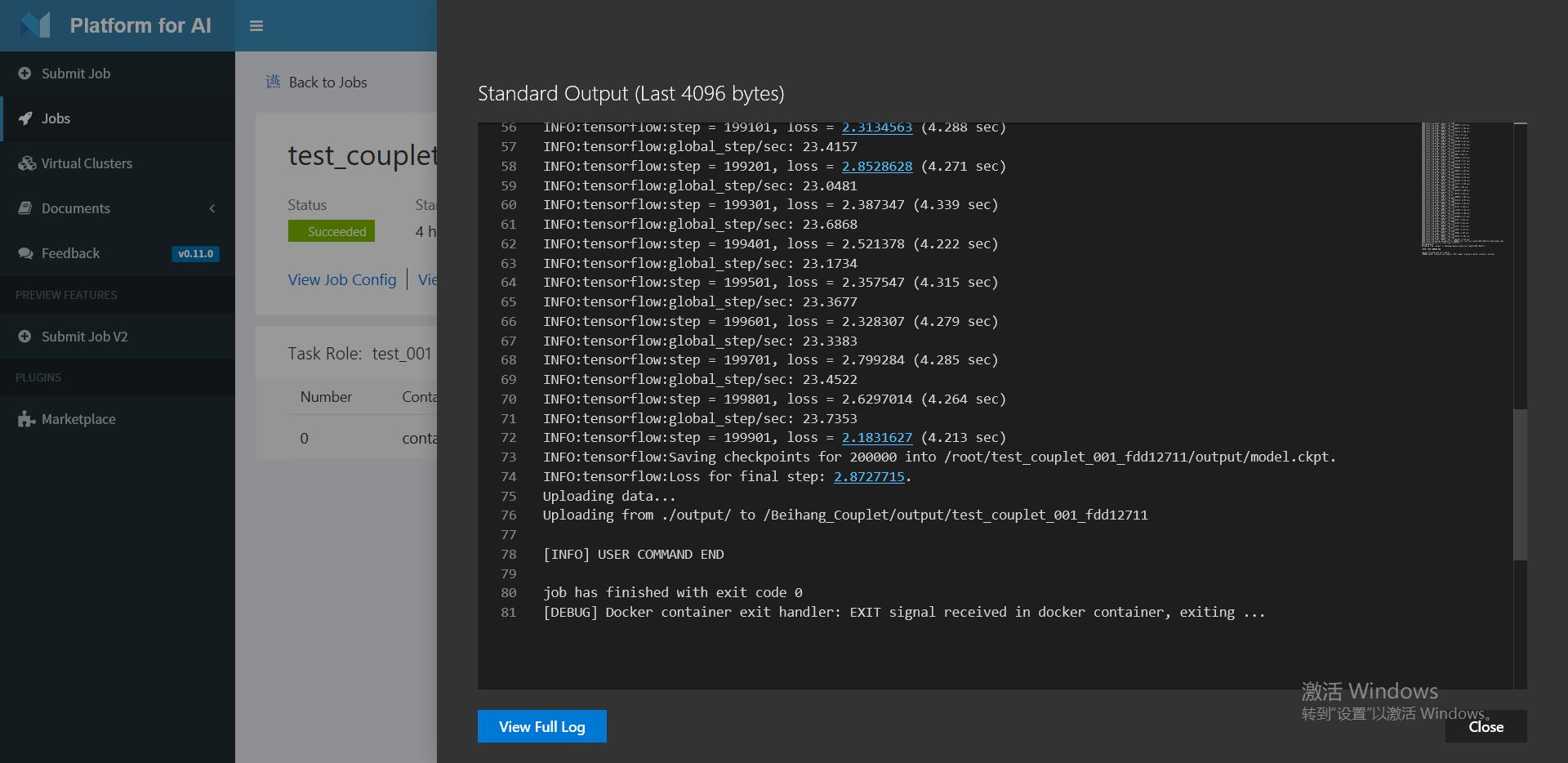
当任务状态显示为succeed,任务完成,训练模型结果传回hdfs。在程序中,我们编写的默认传回路径为output/目录下,以JobName命名的文件夹中 - 使用心得
- 配置简单,使用方便,能方便管理Job
- 该平台性能强大,功能多样,资源丰富
- 在VSCode中搜索OpenPAI插件并安装
-
NNI简介
- NNI(Neural Network Intelligence)是微软开源的自动化机器学习调参工具。支持分布式调度和自动化超参数调整,具有可视化界面。
- NNI (Neural Network Intelligence) 是一个工具包,可有效的帮助用户设计并调优机器学习模型的神经网络架构,复杂系统的参数(如超参)等。
- NNI 的特性包括:易于使用,可扩展,灵活,高效。
-
NNI使用心得
- 安装环境(TensorFlow/NNI)
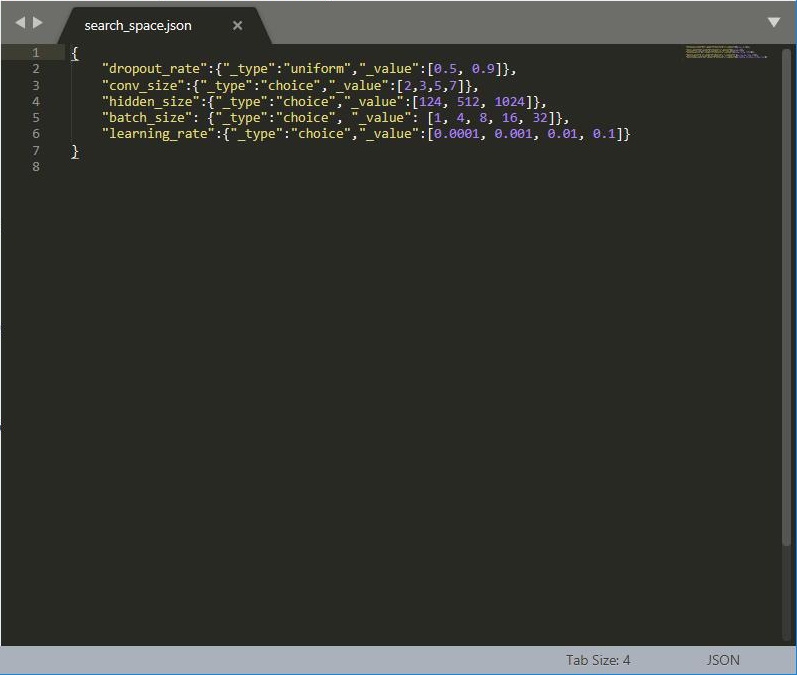
- 配置参数搜索空间的json文件:
- 使用yml运行,在OpenPAI上运行experiment
- 使用体会:操作简单,界面友好
