
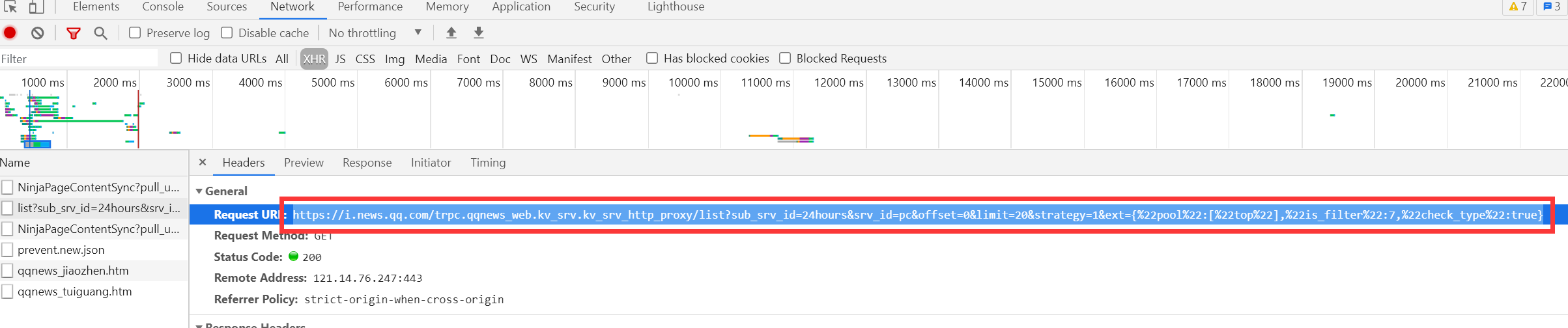
在爬取这个网站的时候,如果直接用requests进行请求,得到的HTML并没有目标数据,所以我估计这不是静态网页,而是动态网页,于是就到XHR查看了一下,果真,那些数据是在如图所示的链接中:
1 import requests 2 import json 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36', 5 'Cookie': 'pgv_info=ssid=s9071181272; ts_last=news.qq.com/; pgv_pvid=7613784555; ts_uid=465011805; ad_play_index=77; pac_uid=0_8ed4c1084a611', 6 } 7 url = 'https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=24hours&srv_id=pc&offset=0&limit=20&strategy=1&ext={%22pool%22:[%22top%22],%22is_filter%22:7,%22check_type%22:true}' 8 9 10 news_dic = requests.get(url = url, headers = headers,data = data).json()['data']['list'] 11 # print(type(news_dic)) 12 # print(news_dic) 13 14 for new in news_dic: 15 print({'标题':new['title'],'链接':new['url']})
