常见的网站攻击手段及预防措施
XSS
XSS攻击的全称是跨站脚本攻击(Cross Site Scripting),为了不和层叠样式表 (Cascading Style Sheets,CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS,是WEB应用程序中最常见到的攻击手段之一。跨站脚本攻击指的是攻击者在网页中嵌入恶意脚本程序, 当用户打开该网页时,脚本程序便开始在客户端的浏览器上执行,以盗取客户端cookie、 盗取用户名密码、下载执行病毒木马程序等等。
有一种场景,用户在表单上输入一段数据后,提交给服务端进行持久化,其他页面上需要从服务端将数据取出来展示。还是使用之前那个表单nick,用户输入昵称之后,服务端会将nick保存,并在新的页面展现给用户,当普通用户正常输入hollis,页面会显示用户的 nick为hollis:
<body>
hollis
</body>但是,如果用户输入的不是一段正常的nick字符串,而是<script>alert("haha")</script>, 服务端会将这段脚本保存起来,当有用户查看该页面时,页面会出现如下代码:
<body>
<script>
alert("haha")
</script>
</body>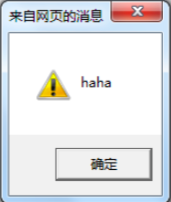
XSS该如何防御
XSS之所以会发生,是因为用户输入的数据变成了代码。因此,我们需要对用户输入的数据进行HTML转义处理,将其中的“尖括号”、“单引号”、“引号” 之类的特殊字符进行转义编码。
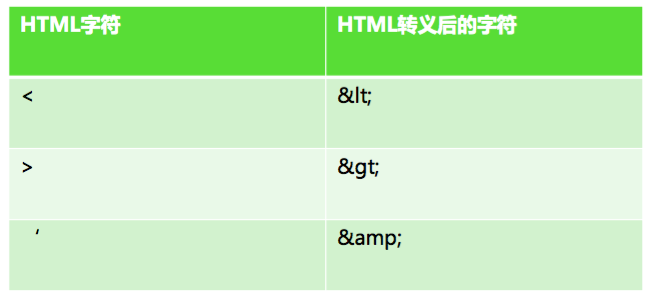
如今很多开源的开发框架本身默认就提供HTML代码转义的功能,如流行的jstl、Struts等等,不需要开发人员再进行过多的开发。使用jstl标签进行HTML转义,将变量输出,代码 如下:
<c:out value="${nick}" escapeXml="true"></c:out>只需要将escapeXml设置为true, jstl就会将变量中的HTML代码进行转义输出。
CSRF
CSRF攻击的全称是跨站请求伪造(cross site request forgery), 是一种对网站的恶意利用,尽管听起来跟XSS跨站脚本攻击有点相似,但事实上CSRF与XSS差别很大,XSS利用的是站点内的信任用户,而CSRF则是通过伪装来自受信任用户的请求来利用受信任的网站。你可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义向第三方网站发送恶意请求。CRSF能做的事情包括利用你的身份发邮件、发短信、进行交易转账等等,甚至盗取你的账号。

假设某银行网站A,他以GET请求来发起转账操作,转账的地址为www.xxx.com/transfer.do?accountNum=10001&money=10000,accountNum参数表示转账的目的账户,money参数表示转账金额。 而某大型论坛B上,一个恶意用户上传了一张图片,而图片的地址栏中填的并不是图片的地址,而是前面所说的转账地址:
<img src="http://www.xxx.com/transfer.do?accountNum=10001&money=10000">当你登陆网站A后,没有及时登出,这个时候你访问了论坛B,不幸的事情发生了,你会发现你的账户里面少了10000块……
为什么会这样呢,在你登陆银行A的时候,你的浏览器端会生成银行A的cookie,而当你访问论坛B的时候,页面上的标签需要浏览器发起一个新的HTTP请求,以获得图片资源, 当浏览器发起请求的时候,请求的却是银行A的转账地址www.xxx.com/transfer.do?accoun tNum=10001&money=10000,并且会带上银行A的cookie信息,结果银行的服务器收到这个请求后,会认为是你发起的一次转账操作,因此你的账户里边便少了10000块。
CSRF的防御
cookie设置为HttpOnly
CSRF攻击很大程度上是利用了浏览器的cookie,为了防止站内的XSS漏洞盗取cookie,需要在cookie中设置”HttpOnly”属性,这样通过程序(如JavascriptS脚本、Applet等)就无法读取到cookie信息,避免了攻击者伪造cookie的情况出现。
增加token
CSRF攻击之所以能够成功,是因为攻击者可以伪造用户的请求,该请求中所有的用户验证信息都存在于cookie中,因此攻击者可以在不知道用户验证信息的情况下直接利用用户的cookie来通过安全验证。由此可知,抵御CSRF攻击的关键在于:在请求中放入攻击者所不能伪造的信息,并且该信息不存在于cookie之中。鉴于此,系统开发人员可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务端进行token校验,如果请求中没有token或者token内容不正确,则认为是CSRF攻击而拒绝该请求。
通过Referer识别
根据HTTP协议,在HTTP头中有一个字段叫Referer,它记录了该HTTP请求的来源地址。在通常情况下,访问一个安全受限页面的请求都来自于同一个网站。比如某银行的转账是通过用户访问http://www.xxx.com/transfer.do页面完成,用户必须先登录www.xxx.com,然后通过点击页面上的提交按钮来触发转账事件。当用户提交请求时,该转账请求的Referer值就会是提交按钮所在页面的URL(本例为www.xxx.com/transfer.do)。如果攻击者要对银行网站实施CSRF攻击,他只能在其他的网站构造请求,当用户通过其他网站发送请求到银行时,该请求的Referer的值是其他网站的地址,而不是银行转账页面的地址。因此,要防御CSRF攻击,银行网站只需要对于每一个转账请求验证其Referer值,如果是以www.xxx.com域名开头的地址,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer是其他网站的话,就有可能是CSRF攻击,则拒绝该请求。
SQL注入攻击
所谓SQL注入,就是通过把SQL命令伪装成正常的HTTP请求参数,传递到服务端,欺骗服务器最终执行恶意的SQL命令,达到入侵目的。攻击者可以利用SQL注入漏洞,查询非授权信息, 修改数据库服务器的数据,改变表结构,甚至是获取服务器root权限。总而言之,SQL注入漏洞的危害极大,攻击者采用的SQL指令,决定攻击的威力。当前涉及到大批量数据泄露的攻击事件,大部分都是通过利用SQL注入来实施的。
假设有个网站的登录页面,如下所示:
假设用户输入nick为zhangsan,密码为password1,则验证通过,显示用户登录:

否则,显示用户没有登录:
SQL注入攻击原理
Connection conn = getConnection();
String sql = "select * from hhuser where nick = '" + nickname + "'" + " and passwords = '" + password + "'";
Statement st = (Statement) conn.createStatement();
ResultSet rs = st.executeQuery(sql);
List<UserInfo> userInfoList = new ArrayList<UserInfo>();
while (rs.next()) {
UserInfo userinfo = new UserInfo();
userinfo.setUserid(rs.getLong("userid"));
userinfo.setPasswords(rs.getString("passwords"));
userinfo.setNick(rs.getString("nick"));
userinfo.setAge(rs.getInt(