C++课程学习笔记第十周:C++11新特性
前言:本文主要是根据MOOC网北大课程——《程序设计与算法(三):C++面向对象程序设计》内容整理归纳而来,整理的课程大纲详见 https://www.cnblogs.com/inchbyinch/p/12398921.html
本文介绍了C++11的新特性,包括初始化、默认值、auto/decltype/nullptr/for/typeid关键字,哈希表、正则表达式、多线程,Lambda表达式,右值引用和move语义,智能指针,四种类型强制转换运算符,异常处理。
1 初始化、默认值、auto/decltype/nullptr/for
//提供了花括号式的初始化方法
int arr[3]{1, 2, 3};
vector<int> iv{1, 2, 3};
map<int, string> mp{{1, "a"}, {2, "b"}};
string str{"Hello World"};
int * p = new int[20]{1,2,3};
//可以设置类的成员变量默认初始值
class B{
public:
int m = 1234;
int n;
};
int main(){
B b;
cout << b.m << endl; //输出 1234
return 0;
}
//auto关键字,用于定义变量,编译器可以自动判断变量的类型
//示例1
map<string, int, greater<string> > mp;
for( auto i = mp.begin(); i != mp.end(); ++i)
cout << i->first << "," << i->second ;
//i的类型是:map<string, int, greater<string> >::iterator
//示例2
template <class T1, class T2>
auto add(T1 x, T2 y) -> decltype(x + y) {
return x+y;
}
auto d = add(100,1.5); // d是double d=101.5
//decltype关键字,求表达式的类型
int i;
double t;
struct A { double x; };
const A* a = new A();
decltype(a) x1; // x1 is A *
decltype(i) x2; // x2 is int
decltype(a->x) x3; // x3 is double
decltype((a->x)) x4 = t; // x4 is double&
//nullptr关键字。C++中宏定义NULL为0,定义nullptr为空指针的关键字
//nullptr可以转换为其他类型指针和布尔类型,但不能转为整数
//详见 https://www.cnblogs.com/developing/articles/10890886.html
int main() {
int* p1 = NULL;
int* p2 = nullptr;
shared_ptr<double> p3 = nullptr;
if(p1 == p2)
cout << "equal 1" <<endl;
if( p3 == nullptr) //智能指针可以直接与NULL、nullptr比较
cout << "equal 2" <<endl;
//if( p3 == p2) ; //error,智能指针会做类型检查
if( p3 == NULL)
cout << "equal 4" <<endl;
bool b = nullptr; // b = false
//int i = nullptr; //error,nullptr不能自动转换成整型
return 0;
}
//输出:equal 1[回车]equal 2[回车]equal 4[回车]
//基于范围的for循环
struct A { int n; A(int i):n(i) { } };
int main() {
int ary[] = {1,2,3,4,5};
for(int & e: ary)
e*= 10;
for(int e : ary) //输出10,20,30,40,50,
cout << e << ",";
cout << endl;
vector<A> st(ary,ary+5);
for( auto & it: st)
it.n *= 10;
for( A it: st) //输出100,200,300,400,500,
cout << it.n << ",";
return 0;
}
2 运行时类型检查运算符typeid
C++运算符typeid是单目运算符,可以在程序运行过程中获取一个表达式的值的类型。typeid运算的返回值是一个type_info类的对象,里面包含了类型的信息。
//typeid和type_info用法示例
#include <iostream>
#include <typeinfo> //要使用typeinfo,需要此头文件
using namespace std;
struct Base { }; //非多态基类
struct Derived : Base { };
struct Poly_Base {virtual void Func(){ } }; //多态基类
struct Poly_Derived: Poly_Base { };
int main(){
long i; int * p = NULL;
cout << "1) int is: " << typeid(int).name() << endl; //输出 1) int is: int
cout << "2) i is: " << typeid(i).name() << endl; //输出 2) i is: long
cout << "3) p is: " << typeid(p).name() << endl; //输出 3) p is: int *
cout << "4) *p is: " << typeid(*p).name() << endl ; //输出 4) *p is: int
//非多态类型
Derived derived;
Base* pbase = &derived;
cout << "5) derived is: " << typeid(derived).name() << endl;
//输出 5) derived is: struct Derived
cout << "6) *pbase is: " << typeid(*pbase).name() << endl;
//输出 6) *pbase is: struct Base
cout << "7) " << (typeid(derived)==typeid(*pbase) ) << endl;//输出 7) 0
//多态类型
Poly_Derived polyderived;
Poly_Base* ppolybase = &polyderived;
cout << "8) polyderived is: " << typeid(polyderived).name() << endl;
//输出 8) polyderived is: struct Poly_Derived
cout << "9) *ppolybase is: " << typeid(*ppolybase).name() << endl;
//输出 9) *ppolybase is: struct Poly_Derived
cout << "10) " << (typeid(polyderived)!=typeid(*ppolybase) ) << endl;
//输出 10) 0
}
3 哈希表、正则表达式、多线程
//无序容器<unordered_map>,用法同<map>一样
//实现:哈希表;插入和查找速度几乎为常数,但也更耗空间。
int main(){
unordered_map<string,int> turingWinner; //图灵奖获奖名单
turingWinner.insert(make_pair("Dijkstra",1972));
turingWinner.insert(make_pair("Scott",1976));
turingWinner["Ritchie"] = 1983;
string name;
cin >> name; //输入姓名来查找
unordered_map<string,int>::iterator p =turingWinner.find(name);
if( p != turingWinner.end())
cout << p->second;
else
cout << "Not Found" << endl;
return 0;
}
//正则表达式
//可用于:有效性验证、从文本中抓取感兴趣信息、分词(Tokenize)、替换等等
//C++11以后支持原生字符,C++03之前不支持;可用assert(...)
//https://www.cnblogs.com/coolcpp/p/cpp-regex.html
int main(){
regex reg("b.?p.*k");
cout << regex_match("bopggk",reg) <<endl; //输出 1, 表示匹配成功
cout << regex_match("boopgggk",reg) <<endl; //输出 0, 匹配失败
cout << regex_match("b pk",reg) <<endl ; //输出 1, 表示匹配成功
regex reg2("\\d{3}([a-zA-Z]+).(\\d{2}|N/A)\\s\\1");
//可用原生字符如 std::regex reg1(R"(<(.*)>.*</\1>)");
string correct="123Hello N/A Hello";
string incorrect="123Hello 12 hello";
cout << regex_match(correct,reg2) <<endl; //输出 1,匹配成功
cout << regex_match(incorrect,reg2) << endl; //输出 0, 失败
}
//多线程
// https://blog.csdn.net/lizun7852/article/details/88753218
// https://blog.csdn.net/lijinqi1987/article/details/78396512
// https://www.cnblogs.com/wangguchangqing/p/6134635.html
// https://liam.page/2017/05/16/first-step-on-multithread-programming-of-cxx/
void GetSumT(vector<int>::iterator first,vector<int>::iterator last,int &result){
result = accumulate(first,last,0); //调用C++标准库算法
}
int main(){ //主线程
int result1, result2, result3;
vector<int> largeArrays;
for(int i=0; i<60000000; i++){
if(i%2==0)
largeArrays.push_back(i);
else
largeArrays.push_back(-1*i);
}
thread first(GetSumT,largeArrays.begin(),
largeArrays.begin()+20000000,std::ref(result1)); //子线程1
thread second(GetSumT,largeArrays.begin()+20000000,
largeArrays.begin()+40000000,std::ref(result2)); //子线程2
thread thrid(GetSumT,largeArrays.begin()+40000000,
largeArrays.end(),std::ref(result3)); //子线程3
first.join(); //主线程要等待子线程执行完毕
second.join();
third.join();
int resultSum = result1+result2+result3+result4+result5; //汇总各个子线程的结果
return 0;
}
4 Lambda表达式
为了避免在主函数体外写过多的函数体或类,对于只使用一次的简单函数或者函数对象,可以采用匿名函数。
//形式:
[外部变量访问方式说明符](参数表)->返回值类型 { 语句组 }
- [] 不使用任何外部变量
- [=] 以传值的形式使用所有外部变量
- [&] 以引用形式使用所有外部变量
- [x, &y] x 以传值形式使用,y 以引用形式使用
- [=,&x,&y] x,y 以引用形式使用,其余变量以传值形式使用
- [&,x,y] x,y 以传值的形式使用,其余变量以引用形式使用
- “->返回值类型”也可以没有,没有则编译器自动判断返回值类型。
//示例1
int main(){
int x = 100,y=200,z=300;
cout << [ ](double a,double b) { return a + b; }(1.2,2.5) << endl;
auto ff = [=, &y, &z](int n) { //可以赋给一个名字,便于重复或简明使用
cout << x << endl;
y++; z++;
return n*n;
};
cout << ff(15) << endl;
cout << y << "," << z << endl;
}
//示例2
int a[4] = { 4,2,11,33 };
sort(a, a+4, [](int x, int y)->bool {return x%10 < y%10; });
for_each(a, a+4, [](int x) {cout << x << " " ;}); //11 2 33 4
//示例3
vector<int> a { 1,2,3,4};
int total = 0;
for_each(a.begin(), a.end(), [&](int& x){ total += x; x *= 2; });
cout << total << endl; //输出 10
for_each(a.begin(), a.end(), [](int x){ cout << x << " ";});
//示例4:实现递归求斐波那契数列第n项
//function<int(int)> 表示返回值为int,有一个int参数的函数
function<int(int)> fib = [&fib](int n) //实现递归求斐波那契数列第n项
{ return n <= 2 ? 1 : fib(n-1) + fib(n-2); };
cout << fib(5) << endl; //输出5
5 右值引用和move语义
参考:
左值和右值
在C语言中:
- 左值就是既可以出现在赋值表达式左边,也可以出现在赋值表达式右边的表达式e;
- 右值就是只能出现在赋值表达式右边的表达式。
在C++中:
- 左值:指向一块内存,并且允许通过 & 操作符获取该内存地址的表达式;
- 右值:非左值的即为右值。
move语义
move语义就是在复制过程中使用浅拷贝,然后把被复制对象所持的资源所有权注销,并不涉及到复制和销毁所持有的资源。
在类的复制构造函数和赋值操作符重载函数中,浅拷贝会带来一系列问题,深拷贝则又太耗资源,因此在一些特殊的场合(比如赋值后右值就不再使用),可以使用move语义来避免深拷贝。
类的复制构造函数在三个地方使用:用同类对象初始化、函数参数传值、函数返回对象。函数返回对象时调用复制构造函数的行为已被现代编译器优化;函数参数传值可以通过改为传引用来规避;用同类对象来初始化时调用复制构造函数的行为可以通过move语义来规避(仅限于不再使用这个同类对象的情况,详见swap示例)。
move语义的实现:通过右值引用再一次重载复制构造函数和赋值操作符。当赋值操作的右边是一个左值时,编译器调用常规赋值函数(进行深拷贝);当右边是一个右值时,编译器调用右值引用的赋值函数(进行浅拷贝)。换句话说,通过重载,左值选择常规引用,右值选择move语义。
//示例1:右值赋值
#include <iostream>
#include <cstring>
using namespace std;
class A{
int* i;
public:
A():i(new int[500]){ cout<<"class A construct!"<<endl; }
A(const A &a):i(new int[500]){
memcpy(a.i,i,500*sizeof(int));
cout<<"class A copy!"<<endl;
}
~A(){ delete []i; cout<<"class A destruct!"<<endl; }
};
A get_A_value(){ return A(); }
int main(){
A a = get_A_value();
return 0;
}
右值引用
右值引用,就是不同于A&左值引用的引用,其表现形式为A&&。右值引用的行为类似于左值引用,但有几点显著区别,最重要的区别是:当函数重载决议时,左值倾向于左值引用,右值倾向于右值引用。
//示例
void foo(A &a); //lvalue reference overload
void foo(A &&a); //rvalue reference overload
A a;
A foobar(){};
foo(a); //argument is lvalue: calls foo(A&)
foo(foobar()); //argument is rvalue: calls foo(A&&)
注意:
- 若只实现void foo(A&),而不实现void foo(A&&),则foo只能左值调用。
- 若只实现void foo(const A&),而不实现void foo(A&&),则foo能同时被左值和右值调用,但是左值右值无任何语义区别(因为左值和右值均可以赋给const A&类型)。
- 若只实现void foo(A &&),而不实现void foo(A&)或void foo(const A&),则foo仅能被右值调用,如果被左值调用会触发编译错误。
- 变量被声明为右值引用后,既可以为左值也可以为右值,比如在重载函数void foo(A && a)中,a被默认当成左值用,需要强制转义才能做右值。区别左值和右值的标准是:它是否有名字,有名字就是左值,无名字就是右值。
强制move语义
C++11允许程序员不仅仅在右值上使用move语义,同样也允许程序员在左值上使用move语义,只需要用move函数即可将左值强制转换为右值(move类似一个类型强制转换符)。
//示例:swap函数
template<class T>
void swap(T& a, T& b) {
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
A a, b;
swap(a, b);
移动构造函数和移动赋值函数
重载复制构造函数和赋值函数,当传入左值时选择常规引用,传入右值时选择move语义。
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
class String{
public:
char * str;
String():str(new char[1]) { str[0] = 0;} //无参构造函数
String(const char * s) {
str = new char[strlen(s)+1];
strcpy(str,s);
}
String(const String & s) { //复制构造函数
cout << "copy constructor called" << endl;
str = new char[strlen(s.str)+1];
strcpy(str,s.str);
}
String & operator=(const String & s) { //赋值函数
cout << "copy operator= called" << endl;
if( str != s.str) {
delete [] str;
str = new char[strlen(s.str)+1];
strcpy(str,s.str);
}
return * this;
}
String(String && s):str(s.str) { //移动复制构造函数
cout << "move constructor called"<<endl;
s.str = new char[1]; //释放掉被拷贝对象的资源所有权
s.str[0] = 0;
}
String & operator = (String && s) { //移动赋值函数
cout << "move operator= called"<<endl;
if (str!= s.str) {
delete [] str;
str = s.str;
s.str = new char[1];
s.str[0] = 0;
}
return *this;
}
~String() { delete [] str; }
};
6 智能指针
参考:
- https://www.cnblogs.com/lanxuezaipiao/p/4132096.html
- https://www.jianshu.com/p/e4919f1c3a28
- https://www.cnblogs.com/tenosdoit/p/3456704.html
- https://blog.csdn.net/thinkerleo1997/article/details/78754919
- https://www.cyhone.com/articles/right-way-to-use-cpp-smart-pointer/
为啥需要智能指针?
- 为了处理用动态内存时的内存泄露和悬空指针的问题;
- 内存泄露的两种情况:忘记delete,或者抛出异常时没有继续走下面的delete语句;
- 智能指针把动态内存的指针封装成一个类,使用上像一个指针,但实际上是一个对象,利用对象生命周期结束后自动消亡这一特点,在析构函数中调用delete,达到自动回收内存的效果。
智能指针有哪几类?为了解决啥问题?
- C++98提供了第一种智能指针:auto_ptr,C++11又增加了三种:unique_ptr、shared_ptr、weak_ptr,之后auto_ptr被摒弃。均在头文件< memory >中。
- 所有的智能指针类都有一个explicit构造函数,以指针作为参数,因此不能自动将指针转换为智能指针对象,必须显式调用。(只接受动态分配内存的指针。)
- 用智能指针对象来托管一个动态内存指针需要解决对象赋值的问题(赋值后会产生对象多次析构delete的问题),通常有两种解决方案,一是资源独享(auto_ptr和unique_ptr采用的策略),二是通过计数来保证多个对象共同托管一个指针时只delete一次(shared_ptr采用的策略)。
- auto_ptr虽然保证了资源独享,但是将对象p1赋值给p2后,对象p1为空指针,后续若不小心用 * 号访问其指向的内存时,程序会崩溃。相比之下,unique_ptr更为严格,它在进行赋值操作时会做检查,若右边为右值时可正常赋值,若为左值时则编译报错,提醒程序员此处有风险。即用unique_ptr替代auto_ptr的好处是可以避免潜在的内存崩溃问题,更安全。(若unique_ptr实在需要赋值,则可用move)
//示例1:智能指针需要显式调用构造函数
shared_ptr<double> pd;
double * p_reg = new double;
//pd = p_reg; // not allowed (implicit conversion)
pd = shared_ptr<double>(p_reg); // allowed (explicit conversion)
//shared_ptr<double> pshared = p_reg; // not allowed (implicit conversion)
shared_ptr<double> pshared(p_reg); // allowed (explicit conversion)
//示例2:为了避免赋值后访问空指针的风险,unique_ptr要求赋值时右边为右值
auto_ptr<string> p1(new string ("auto"));
auto_ptr<string> p2;
p2 = p1; //编译允许,但后续若不小心使用*p1时程序崩溃
unique_ptr<string> p3 (new string ("auto"));
unique_ptr<string> p4;
//p4 = p3; //编译出错,以免后续使用*p3
p4 = move(p3); //用move转为右值,需要特别小心,在更新p3前使用*p3会程序崩溃
p3 = unique_ptr<string>(new string("another")); //更新后可以继续使用
//示例3:shared_ptr用法
#include <memory>
#include <iostream>
using namespace std;
struct A {
int n;
A(int v = 0):n(v){ }
~A() { cout << "id " << n << " destructor" << endl; }
};
int main(){
shared_ptr<A> sp1(new A(2)); //sp1托管A(2)
shared_ptr<A> sp2(sp1); //sp2也托管 A(2)
cout << "1)" << sp1->n << "," << sp2->n << endl; //输出1)2,2
shared_ptr<A> sp3;
A * p = sp1.get(); //获取智能指针对象内部托管的指针
cout << "2)" << p->n << endl;
sp3 = sp1; //sp3也托管 A(2)
cout << "3)" << (*sp3).n << endl; //输出1)2
sp1.reset(); //sp1放弃托管 A(2)
if( !sp1 ) cout << "4)sp1 is null" << endl; //会输出
A * q = new A(3);
sp1.reset(q); // sp1托管q
cout << "5)" << sp1->n << endl; //输出 3
cout << "end main" << endl;
return 0; //程序结束,会delete 掉A(2)
}
7 四种类型强制转换运算符
参考:
将类型名作为强制类型转换运算符的做法是C语言的老式做法,C++为保持兼容而予以保留。但有一些缺陷如下:
- 没有从形式上体现转换功能和风险的不同。
- 将多态基类指针转换成派生类指针时不检查安全性,即无法判断转换后的指针是否确实指向一个派生类对象。
- 难以在程序中寻找到底什么地方进行了强制类型转换,难以debug。
为此,C++引入了四种功能不同的强制类型转换运算符以进行强制类型转换:static_cast,reinterpret_cast,const_cast,dynamic_cast。形式如下:
强制类型转换运算符 <要转换到的类型> (待转换的表达式)
static_cast
static_cast用来进用行比较“自然”和低风险的转换,比如整型和实数型、字符型之间互相转换。
static_cast不能来在不同类型的指针之间互相转换,也不能用于整型和指针之间的互相转换,也不能用于不同类型的引用之间的转换。
//用法示例
class A{
public:
operator int() { return 1; }
operator char * (){ return NULL; }
};
int main(){
A a;
int n; char * p = "New Dragon Inn";
n = static_cast<int>(3.14); // n 的值变为 3
n = static_cast<int>(a); //调用a.operator int, n的值变为 1
p = static_cast<char*>(a); //调用a.operator int *,p的值变为 NULL
//n = static_cast<int>(p); //编译错误,static_cast不能将指针转换成整型
//p = static_cast<char*>(n); //编译错误,static_cast不能将整型转换成指针
return 0;
}
reinterpret_cast
reinterpret_cast用来进行各种不同类型的指针之间的转换、不同类型的引用之间转换、以及指针和能容纳得下指针的整数类型之间的转换。转换的时候,执行的是逐个比特拷贝的操作。(不做安全检查,风险大。)
//用法示例(虽然编译正常,但实际不可这么瞎搞)
class A{
public:
int i; int j;
A(int n):i(n),j(n) { }
};
int main(){
A a(100);
int& r = reinterpret_cast<int&>(a); //强行让 r 引用 a
r = 200; //把 a.i 变成了 200
cout << a.i << "," << a.j << endl; // 输出 200,100
int n = 300;
A * pa = reinterpret_cast<A*>( & n); //强行让 pa 指向 n
pa->i = 400; // n 变成 400
pa->j = 500; //此条语句不安全,很可能导致程序崩溃
cout << n << endl; // 输出 400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); //la太长,只取低32位0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa);
//pa逐个比特拷贝到u
cout << hex << u << endl; //输出 5678abcd
typedef void (* PF1) (int);
typedef int (* PF2) (int,char *);
PF1 pf1; PF2 pf2;
pf2 = reinterpret_cast<PF2>(pf1); //两个不同类型的函数指针之间可以互相转换
}
const_cast
用来进行去除const属性的转换。将const引用转换成同类型的非const引用,将const指针转换为同类型的非const指针时用它。有风险。
//用法示例
const string s = “Inception”;
string & p = const_cast<string&>(s);
string * ps = const_cast<string*>(&s); // &s的类型是const string *
dynamic_cast
- dynamic_cast专门用于将多态基类的指针或引用,强制转换为派生类的指针或引用,而且能够检查转换的安全性。
- 对于不安全的指针转换,转换结果返回NULL指针。对于不安全的引用转换则抛出异常。
- dynamic_cast不能用于将非多态基类的指针或引用,强制转换为派生类的指针或引用。
//用法示例
class Base{ //有虚函数,因此是多态基类
public:
virtual ~Base() { }
};
class Derived:public Base { };
int main(){
Base b;
Derived d;
Derived * pd;
pd = reinterpret_cast<Derived*>(&b);
if(pd == NULL) //不会为NULL。reinterpret_cast不检查安全性,总是进行转换
cout << "unsafe reinterpret_cast" << endl; //不会执行
pd = dynamic_cast<Derived*>(&b);
if(pd == NULL) //结果会是NULL,因为&b不是指向派生类对象,此转换不安全
cout << "unsafe dynamic_cast1" << endl; //会执行
pd = dynamic_cast<Derived*>(&d); //安全的转换
if(pd == NULL) //此处pd不会为NULL
cout << "unsafe dynamic_cast2" << endl; //不会执行
return 0;
}
8 异常处理
参考:
程序的错误大致可以分为三种,分别是语法错误、逻辑错误和运行时错误:
- 语法错误在编译和链接阶段就能发现,只有 100% 符合语法规则的代码才能生成可执行程序。语法错误是最容易发现、最容易定位、最容易排除的错误,程序员最不需要担心的就是这种错误。
- 逻辑错误是说我们编写的代码思路有问题,不能够达到最终的目标,这种错误可以通过调试来解决。
- 运行时错误是指程序在运行期间发生的错误,例如除数为 0、内存分配失败、数组越界、文件不存在等。C++ 异常(Exception)机制就是为解决运行时错误而引入的。
注意:
- 异常机制实际上就是定义一个异常类,通过异常对象来通信。需include < stdexcept >
- 如果一个函数在执行的过程中,抛出的异常在本函数内就被catch块捕获并处理了,那么该异常就不会抛给这个函数的调用者(也称“上一层的函数”);如果异常在本函数中没被处理,就会被抛给上一层的函数。(可以根据需要来决定是在函数内部处理异常,还是把异常抛给调用者。)
- 在函数内部发生异常后返回到上一层函数时,该函数在栈中被清除,里面的局部变量也会消亡。不管是否把异常抛给上一层函数,try块中定义的局部对象在发生异常时都会消亡。
//用法示例:自定义异常类
class CException{
public:
string msg;
CException(string s):msg(s) { }
};
double Devide(double x, double y){
if(y == 0)
throw CException("devided by zero"); //把异常抛给调用者
cout << "in Devide" << endl;
return x / y;
}
int CountTax(int salary){
try {
if(salary < 0) throw -1;
cout << "counting tax" << endl;
}
catch (int) { //函数内部处理异常
cout << "salary < 0" << endl;
}
cout << "tax counted" << endl;
return salary * 0.15;
}
int main(){
double f = 1.2;
try {
CountTax(-1);
f = Devide(3,0);
cout << "end of try block" << endl;
}
catch(CException e) {
cout << e.msg << endl;
}
cout << "f=" << f << endl;
cout << "finished" << endl;
return 0;
}
C++标准库中有一些类代表异常,这些类都是从exception类派生而来。
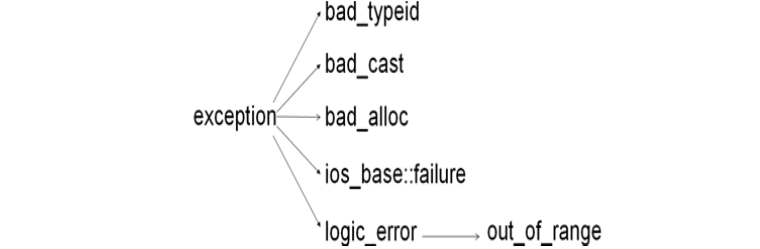
//示例1:在用dynamic_cast进行从多态基类对象到派生类的引用的强制类型转换时,如果转换是不安全的,则会抛出bad_cast异常
#include <iostream>
#include <stdexcept>
#include <typeinfo>
using namespace std;
class Base{ virtual void func(){} };
class Derived : public Base{
public:
void Print() { }
};
void PrintObj( Base & b){
try {
Derived & rd = dynamic_cast<Derived&>(b);
//此转换若不安全,会抛出bad_cast异常
rd.Print();
}
catch (bad_cast& e) {
cerr << e.what() << endl;
}
}
int main (){
Base b;
PrintObj(b);
return 0;
}
//示例2:在用new运算符进行动态内存分配时,如果没有足够的内存,则会引发bad_alloc异常
int main (){
try {
char * p = new char[0x7fffffff]; //无法分配这么多空间,会抛出异常
}
catch (bad_alloc & e) {
cerr << e.what() << endl;
}
return 0;
}
//示例3:用vector或string的at成员函数根据下标访问元素时,如果下标越界,就会抛出out_of_range异常
int main (){
vector<int> v(10);
try {
v.at(100)=100; //抛出out_of_range异常
}
catch (out_of_range& e) {
cerr << e.what() << endl;
}
string s = "hello";
try {
char c = s.at(100); //抛出out_of_range异常
}
catch (out_of_range& e) {
cerr << e.what() << endl;
}
return 0;
}
