PyTorch练手项目三:模型微调
本文目的:基于kaggle上狗的种类识别项目,展示如何利用PyTorch来进行模型微调。
PyTorch中torchvision是一个针对视觉领域的工具库,除了提供有大量的数据集,还有许多预训练的经典模型。这里以官方训练好的resnet50为例,拿来参加kaggle上面的dog breed狗的种类识别。
1 导入相关库,设置一些超参
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, models, transforms
import pandas as pd
import os
from PIL import Image
from sklearn.model_selection import StratifiedShuffleSplit
print(torch.__version__) #1.1.0
print(torchvision.__version__) #0.3.0
#定义一些超参
IMG_SIZE = 224 #模型要求的输入尺寸
IMG_MEAN = [0.485, 0.456, 0.406] #图像预处理中需要的均值和方差
IMG_STD = [0.229, 0.224, 0.225]
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #尽量使用GPU
BATCH_SIZE = 64 #每一个batch的大小
EPOCHS = 7 #训练轮数
2 准备数据
Pytorch中数据的读取通常需要封装成Dataset类对象和DataLoader类对象。
2.1 获取数据并整理
首先下载官方的数据并解压,只要保持数据的目录结构即可,这里指定一下目录的位置,并且看下内容。(注意:labels.csv文件中有10222条标签,对应的是train文件夹中图像。)
#DATA_ROOT = r'D:\KaggleDatasets\competitions\dog-breed-identification'
#注1:常用'/'表相对路径,'\'表绝对路径,网页网址和linux系统下一般用'/'
DATA_ROOT = '/KaggleDatasets/competitions/dog-breed-identification'
df = pd.read_csv(os.path.join(DATA_ROOT, 'labels.csv'))
df.head()
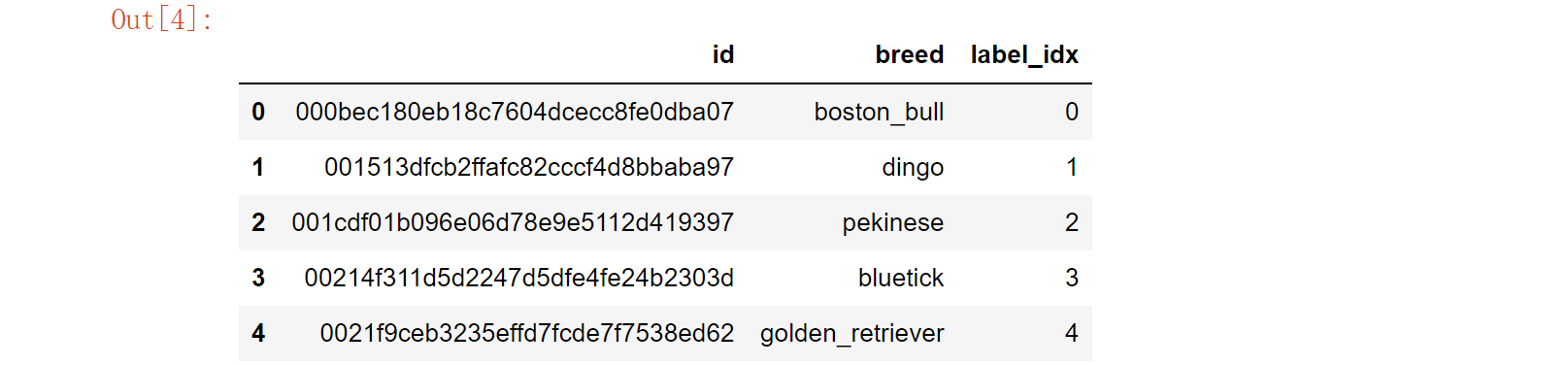
为了后续方便,这里定义两个字典,并将类别序号添加进DataFrame中。
#分别以标签字符串和序号为索引,定义两个字典
breeds = df.breed.unique()
breed2idx = dict((breed,idx) for idx,breed in enumerate(breeds))
idx2breed = dict((idx,breed) for idx,breed in enumerate(breeds))
len(breeds) #120
#将类别序号添加到df的列
df['label_idx'] = pd.Series(breed2idx, index=df.breed).values
#df.shape #(10222, 3)
df.head()
将数据分割成训练集和验证集。这里只分割10%的数据作为训练时的验证数据。
#分割数据集
shuffle_split = StratifiedShuffleSplit(n_splits=1, test_size=0.1, random_state=0) #分层切割
train_idx, val_idx = next(iter(shuffle_split.split(df, df.breed))) #split方法返回迭代器
train_df = df.iloc[train_idx].reset_index(drop=True) #(9199, 3)
val_df = df.iloc[val_idx].reset_index(drop=True) #(1023, 3)
注2:StratifiedShuffleSplit().split(X, y)
- 含义:This cross-validation object is a merge of StratifiedKFold and ShuffleSplit
- split(X, y)方法中,X实际上只用了 np.zeros(n_samples) 来产生占位符,而切分主要靠y
- KFold(shuffle=True)与ShuffleSplit的区别是:前者只shuffle一次,后者每次切分之前都要shuffle
注3:sklearn中几种数据切分方法
- train_test_split:普通切分
- KFold:普通K折切分
- StratifiedKFold:分层K折切分
- StratifiedShuffleSplit:每次shuffle后分层切分
2.2 自定义Dataset
torch.utils.data.Dataset是一个抽象类, 自定义的Dataset需要继承它并且实现两个成员方法:
- __ len __ () :返回整个数据集的长度。
- __ getitem __ () :每次怎么读取数据。
另外,transform过程也在此处传进来。
#自定义Dataset
class DogDataset(Dataset):
def __init__(self, df, img_path, transform=None):
self.df = df
self.img_path = img_path
self.transform = transform
def __len__(self):
return self.df.shape[0] #返回数据集长度
def __getitem__(self, idx): #每次根据idx返回一个(image,label)数据对
img_name = os.path.join(self.img_path, self.df.id[idx]) + '.jpg'
img = Image.open(img_name) #建议用PIL,而非skimage
label = self.df.label_idx[idx]
if self.transform:
img = self.transform(img)
return img, label
#自定义训练集和验证集的transform
train_transform = transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.RandomResizedCrop(IMG_SIZE),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(30),
transforms.ToTensor(),
transforms.Normalize(IMG_MEAN, IMG_STD),
])
test_transform = transforms.Compose([
transforms.Resize(IMG_SIZE), #注4:传入一个int时,短边缩放到IMG_SIZE,长边按比例缩放
transforms.CenterCrop(IMG_SIZE),
transforms.ToTensor(),
transforms.Normalize(IMG_MEAN, IMG_STD),
])
#生成dataset
train_dataset = DogDataset(train_df, os.path.join(DATA_ROOT,'train'), train_transform)
val_dataset = DogDataset(val_df, os.path.join(DATA_ROOT,'train'), test_transform)
2.3 定义DataLoader
类定义为:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, ...)
可以看到主要参数有这么几个:
- dataset:即上面自定义的dataset;
- batch_size:一个batch中样本个数;
- shuffle:划分batch前是否打乱顺序;
- sampler:定义抽样的策略;
- batch_sampler:定义批次抽样的策略;
- num_worker:定义多线程方法,默认为0。
#生成dataloader
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=True)
3 准备模型
使用Pytorch中torchvision.models.resnet50。由于ImageNet是识别1000个物体,这里狗的分类一共只有120,所以需要对模型的最后一层全连接层进行微调,将输出从1000改为120。
#准备模型
model = models.resnet50(pretrained=True) #可用dir(model)查看属性及方法
#将所有参数冻结
for param in model.parameters():
param.requires_grad = False
print(model.fc)
#修改fc层。可用model.named_parameters()迭代查看具体名称和参数
num_feature = model.fc.in_features #获取fc层的输入个数
model.fc = nn.Linear(num_feature, len(breeds)) #重新定义fc层
print(model.fc)
#print(model)
#将model移至GPU
model.to(DEVICE)

注5:关于预训练模型的使用,需要
- 传入pretrained=True,可加载预训练权重;
- 模型使用前需要调用model.train(),或者model.eval()来开启或关闭BN和Dropout等;
- 传给预训练模型的图像应符合:(可见2.2中定义的transform)
- 3通道RGB格式;
- shape为(3,H,W),其中H和W至少为224,若不够则需要Resize;
- 以[0,1]范围加载后用mean=[0.485,0.456,0.406]和std=[0.229, 0.224, 0.225]来Normalize
4 训练
4.1 定义训练参数和函数
训练需要定义损失函数和优化器。另外也打包定义了训练和验证函数。
#指定损失函数和优化器
loss_fn = nn.CrossEntropyLoss() #注6:默认的reduction为mean,即求平均损失
#optimizer = torch.optim.Adam([{'params':model.fc.parameters()}], lr=0.001) #定义fc层学习率
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)
#定义训练函数
#注7:训练5部曲:梯度清零,前向传播,计算损失,反向传播,梯度更新。
def train(model, train_loader, device, epoch):
model.train() #注8:开启训练模型,即开启BN和Dropout等
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) #注9:模型和数据均要移至GPU
#data和target的size分别为torch.Size([64, 3, 224, 224])、torch.Size([64])
optimizer.zero_grad() #梯度清零
yhat = model(data) #前向传播 torch.Size([64, 120])
loss = loss_fn(yhat, target) #计算损失
loss.backward() #反向传播
optimizer.step() #更新梯度
print('Train epoch {}\t Loss {:.6f}'.format(epoch, loss.item()))
#定义测试函数
def test(model, val_loader, device):
model.eval()
test_loss = 0 #记录测试损失
correct = 0 #记录预测正确个数
with torch.no_grad():
for batch_idx, (data, target) in enumerate(val_loader):
data, target = data.to(device), target.to(device)
yhat = model(data)
test_loss += loss_fn(yhat, target).item() #每次加上一个batch的平均损失值
pred = torch.max(yhat, dim=1, keepdim=True)[1] #注10:找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item() #累加正确的样本个数
test_loss /= len(val_loader) #注意此处是除以batch个数,而非len(val_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct, len(val_loader.dataset),
100. * correct / len(val_loader.dataset)))
4.2 开始训练
#开始训练
for epoch in range(1, EPOCHS+1):
%time train(model, train_loader, DEVICE, epoch)
test(model, val_loader, DEVICE)
从结果可以看出,运行几轮之后准确率大约在80%左右,比随机猜测(0.83%)要好很多。
Train epoch 1 Loss 1.935438
Wall time: 3min 26s
Test set: Average loss: 1.2672, Accuracy: 723/1023 (70.7%)
Train epoch 2 Loss 1.673698
Wall time: 1min 41s
Test set: Average loss: 0.8607, Accuracy: 782/1023 (76.4%)
Train epoch 3 Loss 1.657430
Wall time: 1min 41s
Test set: Average loss: 0.7643, Accuracy: 795/1023 (77.7%)
Train epoch 4 Loss 1.463368
Wall time: 1min 40s
Test set: Average loss: 0.7109, Accuracy: 806/1023 (78.8%)
Train epoch 5 Loss 1.849077
Wall time: 1min 40s
Test set: Average loss: 0.7227, Accuracy: 803/1023 (78.5%)
Train epoch 6 Loss 1.442590
Wall time: 1min 40s
Test set: Average loss: 0.7080, Accuracy: 796/1023 (77.8%)
Train epoch 7 Loss 1.540823
Wall time: 1min 41s
Test set: Average loss: 0.6738, Accuracy: 822/1023 (80.4%)
5 小结
- 普通任务的过程:准备数据、准备模型、训练、评估或预测;
- 如何对预训练模型进行微调;
- 利用Pandas和sklearn工具处理数据;
- 标注的10个注意事项。
Reference
