
How browers work?
来源:http://taligarsiel.com/Projects/howbrowserswork1.htm
介绍
网页浏览器或许是被人们用到的最广的一个软件。在这本书我将解释浏览器在屏幕后是怎么工作的?我们将会看到当你在地址栏输入“google.com”直到你在浏览器页面看到Google的页面这个过程到底发生了什么事情。
我们将会说到的浏览器
目前有5种主流的浏览器:Internet Explorer,Firefox,Safari,Chrome以及Opera
我将从开源的浏览器中给出例子-部分开源的浏览器有Firefox,Chrome和Safari
根据W3C浏览器统计数据,目前(2009年10月),Firefox,Safari和Chrome加起来所占用户使用份额接近60%
所以目前在浏览器商业市场上开源的浏览器份额还是很重大的一部分。
浏览器的主要功能
浏览器主要的功能是呈现那些你选择的网络资源,通过从服务器端请求这些资源,然后将其显示到浏览器的窗口。这些资源的格式一般是html,而且有pdf,图片image等等。这些资源的位置有用户指定通过url(统一资源标识符)。更多的内容在其他章节。
浏览器解释和显示html文件的方式是在html和css规格中指定的。这些规格由W3C组织维护-W3C:万维网联盟,是一个专于网页的标准组织。
html目前的版本号为4,版本5在开发中。css目前的版本号是2,版本3在开发中。
一直以来浏览器仅仅只是符合一部分的这些规格标准并且开发他们自己的扩展程序。对于网页作者,即网页开发人员来说,这导致了严重的兼容性问题。目前大部分的浏览器都大体上符合这些规格。
多数浏览器的用户界面在很多地方是共同的。这些共同的用户界面元素是:
地址栏:插入url
前进和后退的按钮
收藏选项
刷新和停止按钮:刷新或者停止正在加载的当前网页
主页按钮:让你到你的主页
奇怪的是,浏览器的用户界面在任何的正式规格说明中都没有指定,他只是长期以来的经验形成的良好的做法,而被浏览器互相模仿。而且html5的规格里也没有定义浏览器必须有的用户界面的元素,而只是列出了一些共同的元素。这些元素是地址栏、状态栏和工具栏。当然对于有些浏览器有一些特殊的地方,比如火狐的下载管理器。
——以上翻译于2012年12月28日
浏览器的高水平的结构(浏览器具有很强的结构)
浏览器的主要组件有:
1、用户界面:这里包括地址栏,前进/后退按钮,收藏菜单等等。浏览器的每一部分都会显示除非你的主页面正是请求页面的状态。(这个不是很懂???)
2、浏览器引擎:查询和操作渲染引擎的界面(不懂???)
3、渲染引擎:响应显示请求内容。例如:假如请求的内容是HTML,他响应的就是解析(parse)html和css以及将解析过的内容显示到屏幕上。
4、网络:用于网络调用。像http的请求一样。他拥有每个独立平台的接口和下面每个平台的实现(???)
5、UI后端:用于绘制基本的小工具,如:组合框,窗口。他引入了一种不是特定平台的通用接口。在这里面他使用了操作系统用户界面的方法。
6、JavaScript解释程序:用户解析和执行JavaScript代码。
7、数据存储:这是一个数据持久层(persistence layer)。浏览器需要存储各种各样的数据在硬盘上,比如说cookies。新html规范(html5)定义网页数据库(web database)是一个在浏览器中完整的数据库(虽然是轻量级的)
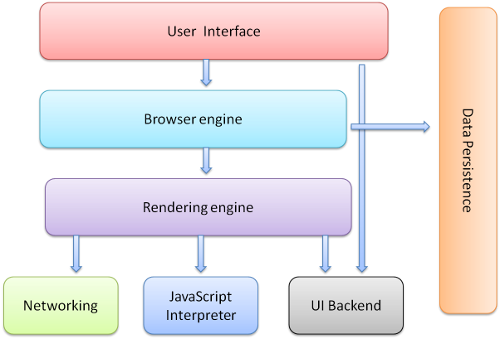
图1:浏览器主要组件.
这是很重要的对于注解(解释)Chrome有并联的渲染引擎-每一个都对应一个标签页。每一个标签页都是一个独立的过程。
我将会对每一个组件用一章讲解。
——以上翻译于2012年12月29日
组件之间的通讯
Firefox和Chrome都各自开发了专用的通讯基础应用程序(infrastructures)
这将会在分别的特定的章节讨论。
渲染引擎
渲染引擎的职责是...嗯,所谓渲染,即将请求的内容显示在浏览器屏幕上。
默认情况下,渲染引擎能够显示html和xml文档和图片。他能够显示其他类型的资源通过插件(浏览器的扩展程序)。举一个例子:是浏览器显示pdf文档通过pdf阅读器插件(扩展程序)。我们将针对插件和扩展程序在特定章节讲解。在这一章我们还是主要讨论一下主要的用例——显示那些用css格式化的html和图片
渲染引擎
我们参照的浏览器: Firefox, Chrome 和 Safari是在两个渲染引擎上建立的。Firefox使用Gecko ——Mozilla自制的渲染引擎。而Safari和Chrome都使用的是WebKit.
WebKit是一个开源的渲染引擎,最开始是为linux平台做的,后来被苹果公司修改了以支持Mac和Windows,详情请看http://webkit.org/
主要流程(flow)
渲染引擎开始会从网络层得到请求得到的文档内容。这经常会在8k chunks内完成(???)
下面就是渲染引擎的基本流程:

图2:渲染引擎基本流程
渲染引擎会首先解析(parse)html文档,并且将标签转化为在一棵树中的DOM节点,称为“内容树”(content tree)。它将会解析样式数据,包括外部css文件和在样式元素内的(in style elements)(???)。这些样式信息 同 html中的可视指令(visual instructions)将会用于创建另一种树——渲染树(the render tree)。
the render tree 包含的矩形(rectangles)——这些矩形带有可视的属性,例颜色,大小(尺寸)。这些矩形会按照正确的顺序显示在屏幕上。
在介绍完the render tree的结构后,再来讨论一个叫布局的过程(a "layout" process)。这意味着如果给每一个节点确切的坐标,那
————————————————————————— · END · —————————————————————————
维修工张大侠:www.cnblogs.com/imzhangze
欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步