
ChatGPT的起源与发展
图灵测试


人工智能(Artifical Intelligence / AI)
1956年8月,在美国达特茅斯学院中,约翰·麦卡锡(语言创始人)、马文·闵斯基(人工智能与认知学专家)、克劳德·香农(信息论创始人)、艾伦·纽厄尔(计算机科学家)、赫伯特·西蒙(诺贝尔经济学奖得主)等科学家聚在一起,讨论用机器来模仿人类学习以及其他方面的智能等问题。并首次提出了“人工智能(Artifical Intelligence)”这个概念。

模式匹配(Pattern Matching)
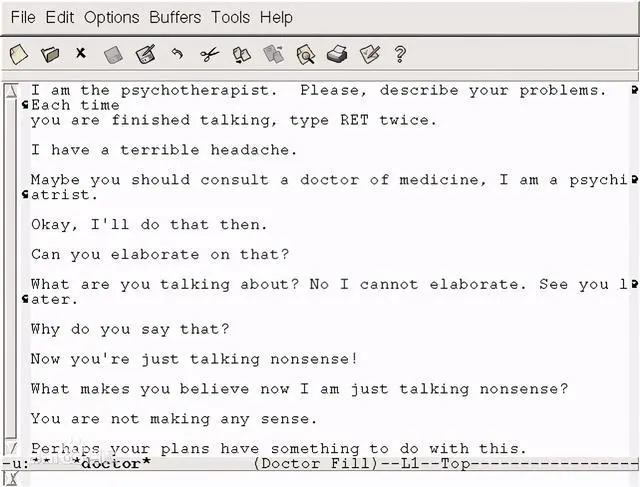
伊丽莎采用了最简单形式的自然语言人工智能——模式匹配,它通过分析语言文本中的关键词,匹配到相关联的场景,并采用提问式的语句,引导使用者说出自己的心声。
例如如果有人告诉伊丽莎,“我妈妈快把我逼疯了”,机器人识别到了“妈妈”这个关键词,那么它就可能用这句话回复,“和我多说点你家里的事情吧。”
它只有文本界面,扮演精神治疗师的角色。它的主要策略是提出问题,并重新表述用户说的话。
你可以理解为它底层的逻辑就是一堆 if ... else ...,根据用户的输入,返回对应的输出,这背后是大约200个固定的匹配规则在起作用。
直到现在,模式匹配仍然是我们生活中非常常见的人工智能产品底层逻辑,比如购物网站的自动回复机器人,或者我们的飞书服务台(虽然感觉有点侮辱人工智能了),它就可以根据我们提前录入的知识库,根据用户的消息内容,匹配到知识库中可能相关的问题,来帮助用户获取答案
机器学习(Machine Learning)
1980年,在美国的卡内基梅隆(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。此后,机器学习开始得到了大量的应用。
与模式匹配不同的是,机器学习不再是给程序设定一系列固定的匹配规则,而是准备大量的问答数据,直接丢给机器人,让机器人像普通人一样自己去学习,从中寻找规律。
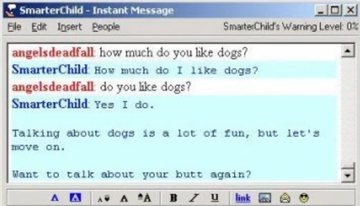
2001年,一个基于机器学习的人工智能机器人诞生了,它叫做“更聪明的小孩(SmarterChild)”它是世界上第一个集成互联网聊天软件的机器人,它与将近3000万的用户进行过聊天。虽然它不能像现在的ChatGPT这么聪明,但是在当时,SmarterChild就已经具备了自然语言的处理能力,可以理解用户的语言并给与回复了。
人工神经网络(ANN)
人工神经网络可以说是机器学习的一种实现方式。
它的理念是模仿人的大脑,使用计算机模拟人脑中的海量神经元,从而使机器具备人脑一样的学习能力。相当于是将人脑的工作机制进行抽象,并使用计算机进行实现。

我们知道,人脑中有一百多亿个神经元,由此可见,想用机器模拟人的神经网络,所需要的资源与算力消耗都是一个不小的数字。
受限于数据与算力的支撑,直到2010年,人工神经网络才开始逐渐成熟并投入使用,目前已经可以在多个领域进行应用,比如基础的人脸识别,声音识别,以及最近非常火的自动驾驶等。
人工神经网络有两种传统的模式,循环神经网络(RNN)与卷积神经网络(CNN)
循环神经网络是一种具有时间序列特性的神经网络,它能够处理序列数据,如文本、音频等。它的处理循序是一个一个词看,一个一个字处理,在长序列的处理过程中容易出现梯度消失或梯度爆炸等问题。
卷积神经网络是一种用于图像和视频处理的神经网络模型,它能够利用卷积操作对图像中的局部特征进行提取。
我们暂且只考虑适用于对话场景下的循环神经网络,也就是序列到序列(Seq2Seq),基于它的学习特点,RNN中每个时间步都需要将前一步的输出作为输入,形成循环结构,每个时间步都需要按照序列顺序进行计算,无法进行并行计算,导致使用该方法进行机器学习的速度实在是太慢了!
Transformer
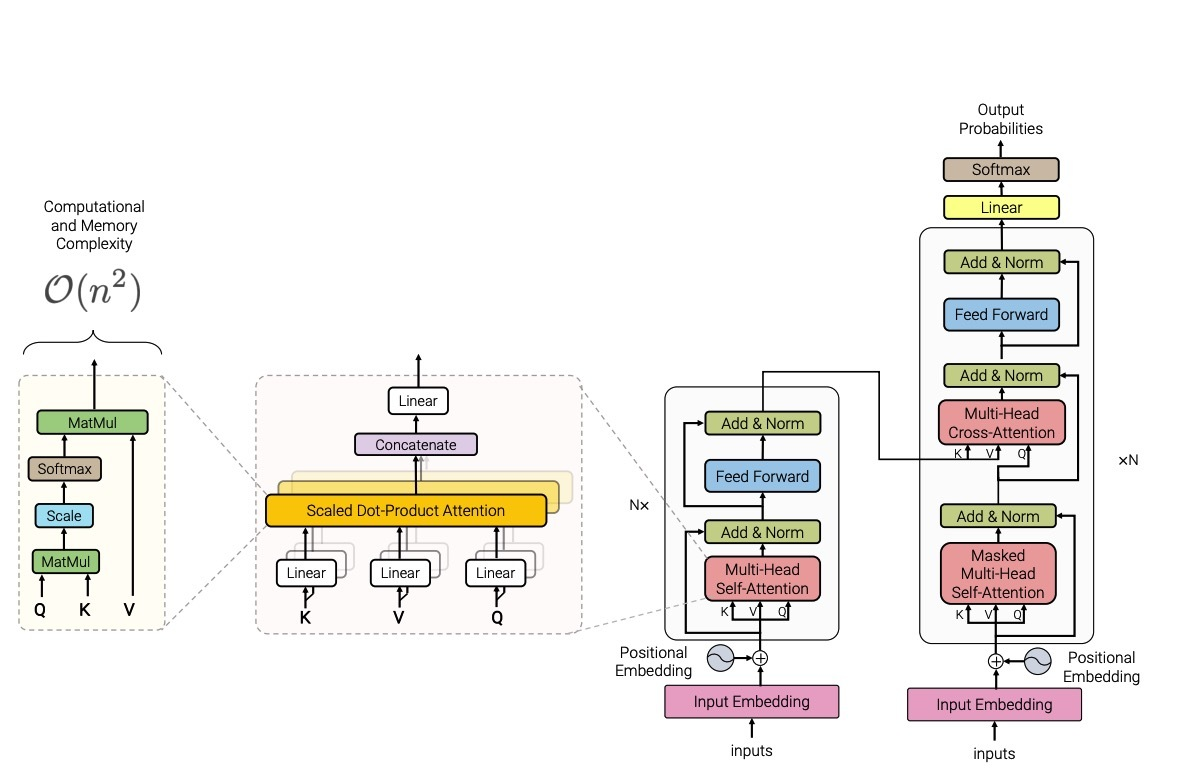
Transformer引入了一种全新的网络结构——自注意力机制(self-attention),它可以直接学习序列中不同位置之间的依赖关系,并在不受序列长度限制的情况下对序列进行编码和解码,进而可以效率的完成序列到序列(Seq2Seq)的学习。
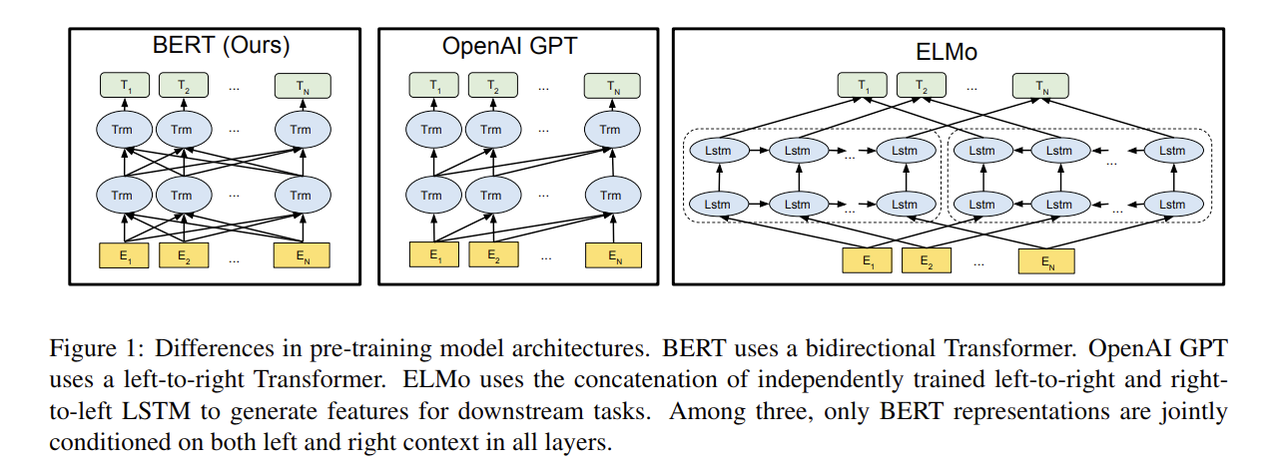
目前几个最先进的自然语言处理模型,比如谷歌的BERT,微软的ChatGPT,都是基于Transformer框架训练而来的。
ChatGPT


由于是非盈利组织,所以该组织研究所产出的一些产品,大多都是公开的,比如我们可以在github上看到openai组织下的众多开源项目,足足140多个项目,传送门
2018年,马斯克退出该组织,同年 OpenAI基于谷歌的 Transformer 模型架构,发布了一个新的语言模型 Generative Pre-trained Transformer(GPT)。
GPT是一个预训练模型,它的先进之处,在于它可以使用大规模语料库进行了无监督的训练,学习大量的语言知识。这使得GPT可以很好地应用于各种自然语言处理任务中,如文本生成、文本分类、命名实体识别等。
相比之下,Transformer本身不是一个预训练模型,而是一个网络模型,需要在具体任务上进行训练。
想要成就一个成熟的生成式AI产品,光有一个好的训练模型是不够的,还涉及到一个非常重要的因素:参数量
参数量指的是通过对训练数据进行深度学习并迭代优化后的模型所包含的参数数量,参数通常指权重和偏置项。
模型的参数量是一个非常重要的指标,因为它直接影响了模型的复杂度和能力。一般来说,参数量越大,模型的表示能力就越强。然而,参数量越大,模型的训练时间和内存等资源消耗也会随之增加。
2019年,由于马斯克的退出以及GPT训练所产生的的大量费用问题无法解决,OpenAI从非盈利组织转型成为了收益封顶的盈利组织,并获得了微软的10亿美元投资,并为OpenAI提供了大量的基础设置与算力资源!


2018年6月,OpenAI推出GPT-1模型(参数量1.5亿)
2019年11月,OpenAI推出GPT-2模型(参数量15亿)
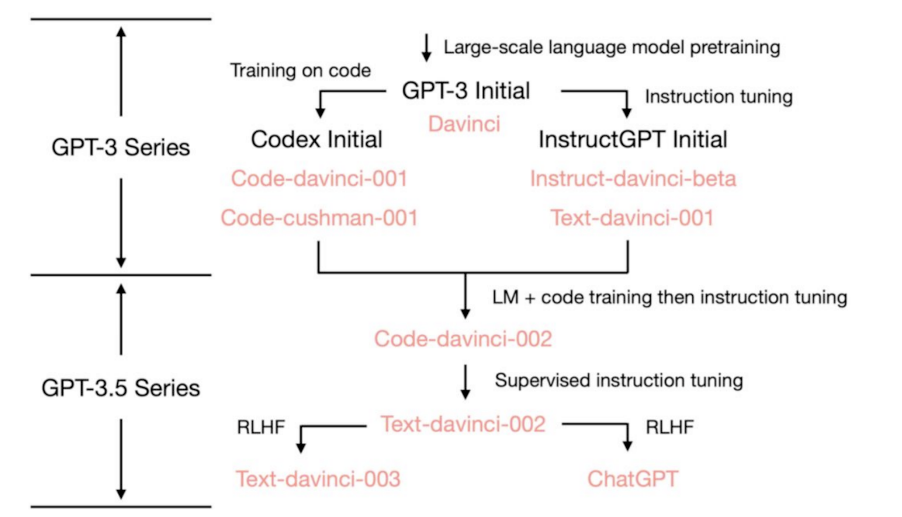
2020年6月,OpenAI推出GPT-3模型(参数量1750亿,由于组织转型等原因,不再开源)
2022年3月,OpenAI推出GPT-3.5模型(在GPT3的基础上加入了人工反馈的强化学习(RLHF)),使得学习效率与正确性获得了极大的提升,也使它的行为更加贴近人类的习惯

在ChatGPT推出后,微软乘胜追击,宣布将推出基于AI的全新搜索引擎 New Bing,目前处于内测阶段。
New Bing引入了自然语言处理和人工智能技术,可以更准确地理解用户的搜索意图,并提供更加智能化的搜索结果。
ChatGPT的发布与微软的New Bing,对Google来说简直就是一个暴击,因为google的搜索业务目前在全球的市场占有率达到了93%,而微软的Bing只有3%,这是一块巨大的蛋糕。

因此,在微软宣布即将推出New Bing后,Google也紧随其后发布了对标的产品 BERT,不过由于发布会准备不够充分,演示频繁出现bug,远无法达到人们心目中的期望,在发布会结束当天,Google股价跌超7%,市值将近蒸发了7000亿,太惨了。。。
除了Google,Meta(facebook母公司)也在2023年2月发布了他们的人工智能大型语言模型 LLaMA,论文地址
LLaMA是一个基础语言模型的集合,参数范围从7B到65B。LLaMA-13B在大多数基准测试中优于GPT-3 (175B),github
2023年3月15日凌晨,OpenAI又发布了 GPT-4
GPT-4 在GPT-3.5的基础上加入了多模态(CLIP)模型,使得它可以同时处理多种类型的输入,比如语言文本、图像等,意思是ChatGPT已经可以与人们互发表情包了!
同时,OpenAI也根据 GPT-3.5 与 ChatGPT开放后所获取的经验,对GPT-4模型进行了大量的优化,使得它在逻辑性、正确性、可控性等多方面都有了极大的提升。

总结
就目前而言,ChatGPT妥妥的是最先进且最智能的泛化聊天机器人,并且正在快速的被人们吸收并加以利用,有些人用它搜索知识,有些人用它生成文案,有些人用它编写代码。
大势所趋下,时间不等人,我们更应该不断思考,人工智能快速发展并普及的背景下,我们能做些什么?
有人说,现在最大的矛盾是,AI的能力与人类想象力之间的矛盾。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步