

自动化测试如何区分用例集合
前面的文章介绍过如何设计自动化测试case,有同学在后台问到:业务比较复杂,有很多串行并行甚至组合的业务场景,执行case时经常遇到由于前后依赖导致的case失败问题,该如何处理?
当业务复杂度和工作量上来之后,在具体的实践中这是个避不开的问题。那如何解决这个问题?我建议可以通过按照业务和场景区分用例集合的方式来解决。
业务量和复杂度增长现状是什么?
以我的亲身经历而言,当业务爆发式增长时,测试团队会面临如下几点变化和调整:
|
对比项 |
业务增长前 |
业务增长后 |
|
团队组织架构 |
大团队 |
大团队小team,按照业务域划分不同小团队 |
|
团队协作方式 |
互相协作,沟通成本低 |
跨team协作频次变高,构成成本高 |
|
团队技术栈构成 |
比较单一,学习和迁移成本低 |
技术栈多样,学习和迁移成本高 |
|
测试case覆盖率 |
只覆盖核心场景,保证主流程正向流程 |
PO/P1/P2场景,正向逆向场景都覆盖 |
|
测试人员职责划分 |
每个人都熟悉整体业务流程和场景 |
每个人只熟悉岗位职责内的业务流程和场景 |
这里我们只讨论和自动化测试case相关的区别。
业务增长自然而然带来的是流程的复杂度提升和业务场景的多样性,同时用户体验和线上的小问题影响范围,也会扩大。
因此在测试case的覆盖率上,覆盖的颗粒度会更细致。
以电商下单场景为例:核心流程在case设计和执行以及结果校验时,主要会关心商品库存、是否使用优惠券、是否参与活动以及订单数据是否入库到之后的是否支付成功,这是一个正向的核心场景case。如下图所示:
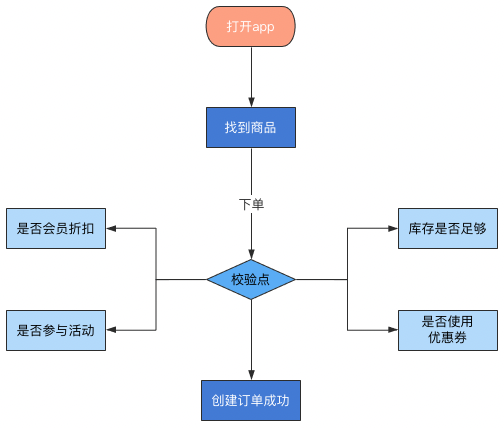
正常的下单流程能否走下去,主要依赖于上图的几个校验点。
假设,团队按照不同的业务域拆分为好多个小团队,职责和边界划分更细致时,该怎么做呢?
如何区分自动化测试的用例集合?
还是以电商的主要业务流程为例说明,假设团队拆分的更细致,业务链路依赖更复杂,怎么办?如下图:
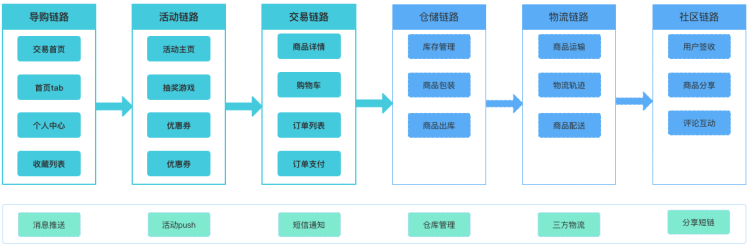
可以看到每个链路都会依赖于上下游链路的部分数据或者调用关系。面对如此复杂的场景和跨团队协调,这个时候区分用例集合的好处就体现了出来。那么如何区分用例集合呢?看下图:
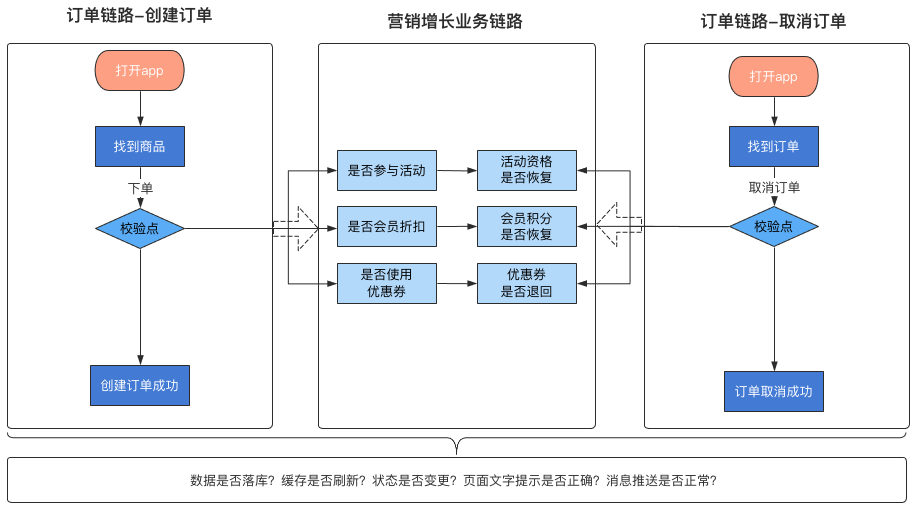
如上图所示,如果团队是按照业务域或者业务链路做了区分,团队内同学负责的模块也不一致,区分的大致思路如上。
如何理解呢?就是每个人只负责设计自己所负责模块的case,考虑好正向逆向流程的校验点,然后调用和依赖模块对应的场景和数据,和对方约定好,遵循互信原则即可。
区分用例集合的过程要注意什么?
区分用例集合的注意事项,主要参考如下几点:
- 业务团队按照一定的原则划分,而不是混乱;
- 每个团队之间要明确好业务边界和职责边界;
- 调用依赖和边界遵循统一的调用方式(如restful);
- 测试数据的存储和校验建议统一维护而非各自独立;
- 测试用例要按照不同条件做区分(类似打标签形式);
- 持续集成任务要按照前后依赖做好执行时序的区分;




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
2018-09-16 常见的性能测试缺陷