

自动化测试如何管理测试数据
前段时间,知识星球里有同学问到:自动化case越多,测试数据越多,数据的管理成本也越来越高,是否需要一个数据池来专门管理测试数据?
这是一个好问题,也是很多测试同学在自动化测试实践中必须面对的一个问题。
近几年随着技术不断发展,新的工具、方法论和技术实践越来越多,自动化测试在具体工作中有了很多方法论和实践,这些实践的背后是什么原因在推动技术的发展,我觉得是个很值得复盘和回溯的事情。
这篇文章,我想聊聊自动化测试数据管理的方式,是如何迭代和不断演进的。
先看下面这张图,我将自动化测试成熟度演变分为如下几个阶段,关于如何管理数据,我会从下述几个阶段分开描述。
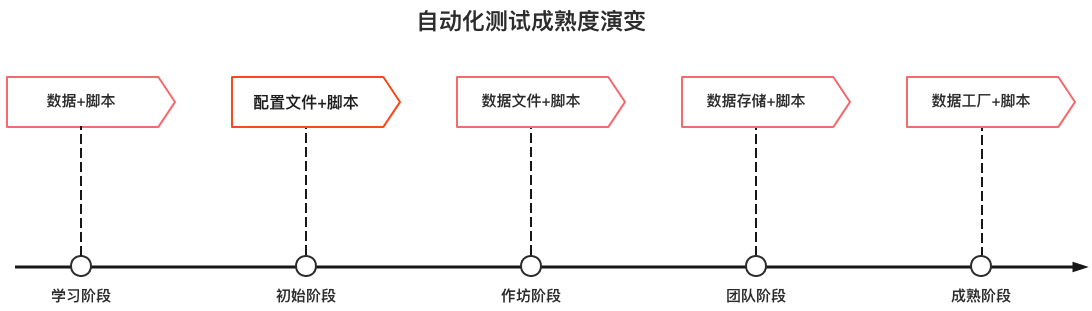
PS:上图不同阶段的标识,只是为了说明每个阶段的测试数据特性,而非这个阶段的具体技术实现方式和细节。
学习阶段
很多测试同学在刚开始学自动化测试的时候,基本都是脚本和测试数据写在一起,从实际工作应用的角度来说很不推荐。
因为随着业务和技术的变化迭代,测试脚本和数据也要重新修改并执行,直接增加了自动化测试工作的维护成本,这样做有悖于自动化测试的本质(回归&提高效率)。
但对于新手或者初学者来说,将脚本+数据写在一起,它是可以快速实现和有直接反馈的一个demo。
初始阶段
自动化测试的数据管理第二个阶段,就是将测试数据写在配置文件里,通过键值对的方式去读取一些公用的数据,比如用户名密码、数据库连接配置、要访问的服务域名等。
这种做法大概在16年-17年是很常见的一种方式,也是很多刚开始尝试做自动化测试工作的同学常用的方式。当然那个时候在测试圈子里,所谓的PO模式、数据和脚本分离已经有了一定的讨论和实践。
不过这个阶段有个很有意思的点,很多公司为了自动化而自动化,专门招一个人来做自动化。求职市场也比较火爆,很多公司其实就是一个人做自动化测试,脚本数据都在本地保存和执行,这样做也无伤大雅。
作坊阶段
所谓的作坊阶段就是指测试团队有了一定规模,业务迭代速度和场景的复杂度有了一定提升,这个时候从需要有自动化开始转变为对效率的期待。
很典型的一点就是这个时候所谓的版本管理和持续集成开始为测试同学注重起来,当然通俗来说就是SVN&Git和Jenkins开始在测试团队应用了起来,当然也仅限于使用。
还有一点就是部分测试同学开始意识到测试报告的重要性,大概18年左右,当时很多测试群和网上很多资料,都是关于HTMLTestRunner和Allure的各种魔改,以高大上和美观为主要追求。
当然,对于自动化测试需要的测试数据,大家也开始接受了数据和脚本分离,通过csv文件来存储测试数据。
这样做的好处是测试场景变化后,只需要修改测试数据即可,提高了测试脚本的可维护性,也便于多人维护同一批测试数据。
团队阶段
到了第四阶段也就是团队阶段,测试团队的流程规范和技术体系开始逐步建立起来了,自动化测试也从独立的岗位变成了功能测试同学入厂标配。
为了便于测试数据的统一管理,也考虑到测试数据的持久化问题,大家开始引入数据库来进行测试数据存储,这样做进一步的降低了脚本和数据的耦合性,脚本就是不同的测试场景和case,数据作为公共部分被引入即可。
这个阶段还有个很有意思的点,测试平台的概念开始在各技术大会和技术沙龙上被提及,很多测试管理者甚至测试同学也在工作和不同场合中开始言必称开发平台。
成熟阶段
第五个阶段就是所谓的数据池或者造数工厂的概念了,所谓的造数工厂,其实就是通过直接调用应用程序的方法来产生数据,在自动化测试脚本或者服务联调、问题复现阶段直接引用。
这样做有几个特点:一是各种测试平台(不仅限于自动化测试平台)开始在企业内落地,二是催生了很多测试开发岗位,三是平台的适用范围开始由测试团队向其他技术团队扩散,也就是所谓的打通+赋能。
当然还有一些其他有意思的点,比如测试开始提倡全栈,各种招聘jd上要求懂前后端容器devops等各种东西,再比如测试圈子里开始讨论码代码能力到什么程度可以做测试开发,也是卷的不行。
追溯反思
综合上面几个阶段测试数据管理的方式以及近几年测试圈子或者说技术领域的一些现象,可以得到如下几个结论:
- 市场和企业对测试团队的要求越来越高;
- 手工测试开始逐渐向真正的工程师转变进化;
- 测试职能从功能验证开始转向质量保障和效率提升;
- 未来所谓的测试岗位几乎都会要求业务+技术既要还要;
当然,市场在不断变化,对于人的要求也在变得更丰富和具体,能跟随发展和市场要求的人,才能存活下来。
如果非要用几个关键字来概括上面的几个阶段的话,我认为这几个词可能会更合适:
市场期待——企业跟随——探索实践——效率提升——协同配合




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本