


《SRE实战手册》学习笔记之切入SRE
前言
这篇文章是《SRE实战手册》学习笔记的第二篇,理解SRE之后,就要找到切入点来落地。
理解SRE中的指标和目标
SRE强调稳定性,一般是看整体的系统情况,也就是常说的"3个9"、"4个9"这样可量化的数字。
这个“确定成功请求条件,设定达成占比目标”的过程,在SRE中就是设定稳定性衡量标准的SLI和SLO的过程。
1、SRE的两个核心
SLI(Service Level Indicator):服务等级指标,即选择哪些指标来衡量稳定性(状态码为非 5xx 的比例);
SLO(Service Level Objective):服务等级目标,指设定的稳定性目标(大于等于 99.99%);
落地SRE的第一步:选择合适的SLI,设定合理的SLO,SLO是SLI要达成的目标。
监控体系是SRE体系中很重要的组成部分,也是最直观的指标产出展示方式。
2、常见的监控指标

3、选择监控指标的考量点
两个因素
- 要衡量谁的稳定性?即先找到稳定性主体;
- 这个指标能够标识这个实例是否稳定吗?
两大原则
- 选择能够标识主体是否稳定的指标,如果不是该主体本身或不能标识主体稳定性的指标,就要排除在外;
- 针对电商这类有用户界面的业务系统,优先选择与用户体验强相关或用户可以明显感知的指标;
4、快速识别SLI指标的方法
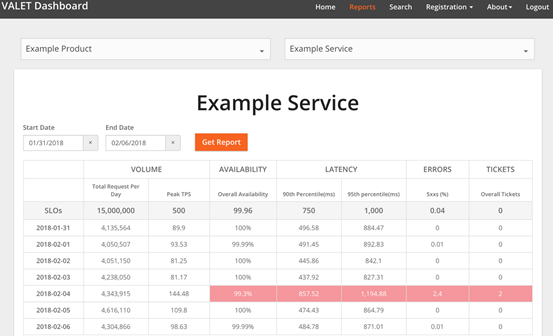
VALET是5个单词的首字母,分别是Volume、Availability、Latency、Error 和 Ticket。
1)Volume-容量:指服务承诺的最大容量是多少。比如一个应用集群的 QPS、TPS、会话数以及连接数;
2)Availablity-可用性:代表服务是否正常。比如请求调用的非 5xx 状态码成功率,就可以归于可用性;
3)Latency-时延:指响应是否足够快,这是会直接影响用户体验的指标。时延的分布符合正态分布,建议以类似“90%RT<=80ms,或者 95%RT<=120ms”这样的方式来设定时延SLO的置信区间。设定不同的置信区间来找出这样的用户占比,有针对性地解决;
4)Errors-错误率:错误率有多少?除了 5xx之外,还可以把 4xx列进来,或增加一些自定义的状态码,看哪些状态是对业务有损的,来保障业务和用户体验;
5)Tickets-人工介入:是否需要人工介入?如果一项工作或任务需要人工介入,那说明一定是低效或有问题的,这里可以将tickets理解为门票。
一个周期内,门票数量是固定的,比如每月 20 张,每次人工介入,就消耗一张,如果消耗完了,还需要人工介入,那就是不达标了。
5、Google-VALET-dashboard
6、如何通过SLO计算系统可用性
系统可用性Availability = Successful request / Total request,常见的计算方式有如下两种:
1)根据成功的定义来计算:Successful =(状态码非 5xx)&(时延<=80ms);
2)SLO方式计算:Availability=SLO1&SLO2&SLO3(即综合维度的指标衡量);
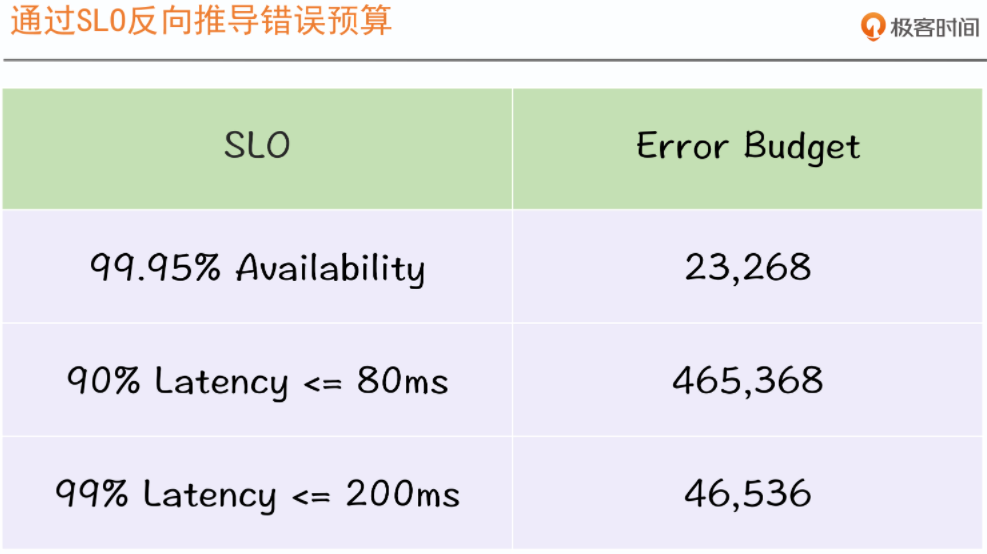
SLO1:99.95%状态码成功率;
SLO2:90%RT<=80ms;
SLO3:99%RT<=200ms;
对系统相关监控指标要分层,识别出我们要保障稳定性的主体(系统、业务或应用)是什么,然后基于这个主体来选择合适的 SLI 指标。
不是所有的指标都是适合做 SLI 指标,它一定要能够直接体现和反映主体的稳定性状态。可以优先选择用户或使用者能感受到的体验类指标,比如时延、可用性、错误率等。
达成稳定性目标的共识机制
知道了SRE的核心是设定目标和指标,但在具体落地过程中,该如何找到切入点呢?反过来看,可以制定一个允许犯错的次数标准,只需要去监控这些错误,就是一个很好的落地切入点。
1、设定错误预算
允许犯错的次数标准在SRE体系中叫做Error Budget,即错误预算。错误预算其实和驾照记分制是一样的,最大的作用就是“提示你还有多少次犯错的机会”。
错误预算的计算方式通过SLO推导得到,参考计算公式:Availability=SLO1&SLO2&SLO3。
2、如何应用错误预算
2.1稳定性燃尽图
特点:尽可能直观的将错误预算表现出来,随时可以看到它的消耗情况。同时加入错误预算消耗告警,如达到80%时开始预警,通过控制各种变更等手段来降低预算消耗频次。
参考:Google的错误预算燃尽图
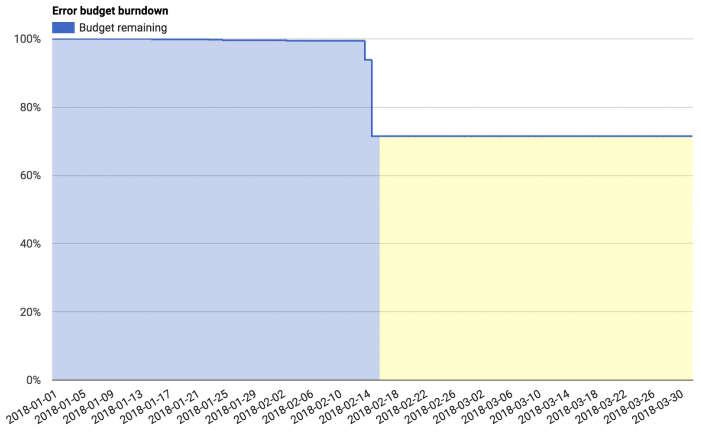
注意事项:
- 应用错误预算,应该设定合理的周期,推荐4个自然周;
- 要考虑到特殊场景如双11大促,如果这些特殊场景处在某个考核周期内,应适当放大错误预算的值;
2.2故障定级机制
判断一个问题是不是故障,除了看影响时长,还有一点就是按照问题消耗的错误预算比例来评估。
通过错误预算来定义故障等级就可以做到量化,一旦可以被量化就意味着可以标准化,有了标准就可以进而推进达成共识。
参考:业内常见的故障定级维度和定义
P0:系统中断1小时以上,造成大范围的用户不可用;
P1:系统中断30分钟到1小时,造成部分用户不可用;
P2:系统核心模块或功能出问题,造成大量用户投诉;
P3:系统次要模块或功能出问题,造成部分用户投诉;
P4:便于模块或功能出问题,未导致不可用或投诉,但影响用户体验;
其他维度:如造成公司资产损失超过一定额度或者企业品牌受影响,这些因素要综合考虑!
2.3稳定性共识机制
由于每个人对稳定性的认知不同,因此通过建立稳定性共识机制并且积极推动,也是一种很好的实践方式。
参考:推动稳定性共识机制的2个指导原则
- 预算充足或者未消耗完之前,对问题的发生要有容忍度;
- 剩余预算消耗过快或即将消耗完之前,SRE 有权中止和拒绝任何线上变更;
从推行的角度来讲,涉及到跨团队沟通共识机制。建立稳定性共识机制一定是 Top-Down,也就是自上而下,至少要从技术 VP 或 CTO 的角度去推行。
而且当有意见不一致的情况出现时,还要逐步上升,直至 CTO 角度来做决策。一定要自上而下推进周边团队或利益方达成共识。
2.4基于错误预算的告警
监控告警有一点很重要的是告警降噪收敛。即不要被“狼来了”的告警搞定疲惫不堪,要有对应的处理机制。
参考:常见的告警降噪收敛方案
- 告警合并:即相同或相似的告警,合并后发送;
- 基于错误预算告警,即只关注对稳定性造成影响的告警,如“单次问题错误预算消耗超过20%”;
3、如何衡量SLO的有效性
衡量 SLO 及错误预算策略是否有效,就是看实际运行后是否真的能达到我们的期望。见下面三个关键维度:
- SLO达成情况:用达成(Met),或未达成(Missed)来表示。
- "人肉"投入程度:英文表示为Toil,泛指需要大量人工投入、重复繁琐且没有太多价值的事情。用投入程度高(High)和低(Low)来表示;
- 用户满意度:Customer Satisfaction,可理解为用户体验,通过真实和虚拟的渠道获得。真实渠道如客服投诉、客户访谈和舆情监控获取;虚拟渠道如真机模拟拨测。用投入程度高(High)和低(Low)来表示;
参考:不同维度不同情况的应对策略
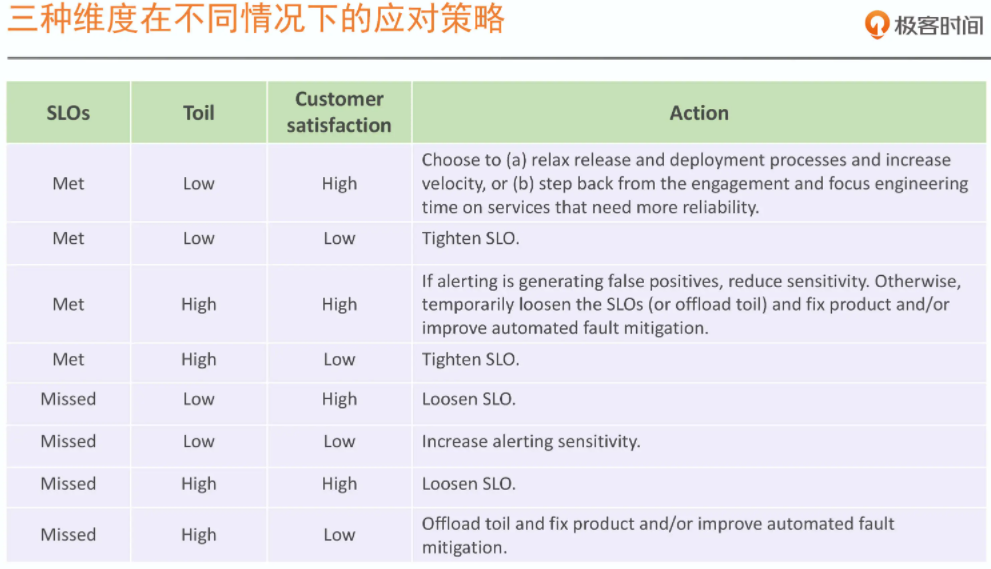
针对上述的几种情况,将这些策略总结起来,主要有如下三种策略:
3.1收紧SLO
原因为目标设定太低,即SLO达成(Met),但是用户不满意(Low),常见表现方式为客诉增多或内部吐槽变多;
3.2放宽SLO
原因为目标设定太高,SLO达不成(Missed),但用户反馈很不错(High),这样会造成错误预算提前消耗完,导致很多变更暂停,产品延期,甚至会做一些无谓的优化,这时可以适当放宽SLO;
3.3保持现状,对有问题的维度采取针对性的优化
在SLO可以达成的情况下,尽量提升用户价值交付效率,围绕这个终极目标,不断优化自己的SLO和错误预算策略。
落地SLO时要考虑的因素
1、确定核心链路SLO
所谓核心链路,即某个系统为用户提供业务价值的主流程。
以电商系统来说,导购-搜索-商品详情-购物车-下单-支付即为核心链路。
指导原则:先确定核心链路的SLO,然后根据核心链路进行SLO拆解。
1.1确定核心链路
通过全链路跟踪的技术手段来找出所有应用,即呈现出调用关系的系统拓扑图。
常见工具:cat、jaeger、zipkin、pinpoint、skywalking。
1.2确定核心应用
根据业务场景和特点,从繁杂的应用中通过不断讨论和分析来确认核心应用。
以电商系统为例,核心应用一般有index、search、product、order、coupom、payment等。
参考:核心交易链路图
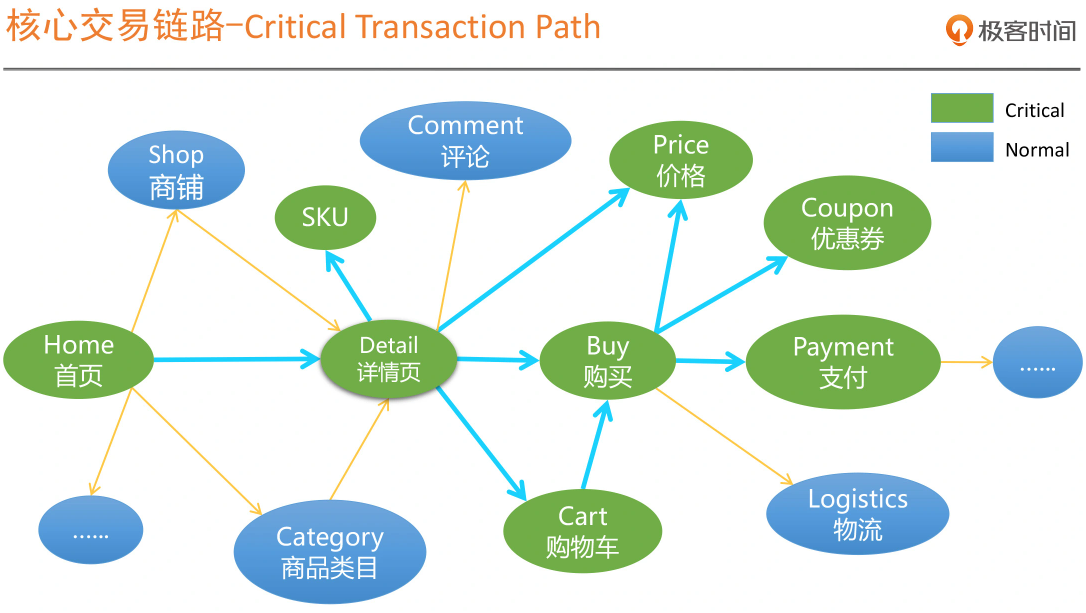
1.3确认强弱依赖
核心应用之间的依赖关系,称之为强依赖,而其它应用之间的依赖关系,我们称之为弱依赖。
其中包含两种关系,一种是核心应用与非核心应用之间的依赖,另一种是非核心应用之间的依赖。
当然,还可以通过其他方式确认强弱依赖关系,比如:是否可以直接熔断等。
2、设定SLO的四大原则
2.1核心应用的SLO要更严格,非核心应用可以放宽。 这么做是为了确保SRE精力能够更多地关注在核心业务上;
2.2强依赖之间的核心应用,SLO要一致。 如下单的 Buy 应用依赖 Coupon 这个促销应用,我们要求下单成功率的 SLO 要 99.95%,就会要求 Coupon 的成功率 SLO 也要达到 99.95%;
2.3核心应用对非核心的弱依赖,有降级、熔断和限流等服务治理手段。 这样做是为了避免由非核心应用的异常而导致核心应用 SLO 不达标;
2.4核心应用错误预算要共享,如果某核心应用错误预算消耗完,那整条链路原则上都要停止变更操作。
可以根据实际情况适当宽松,如果某核心应用自身预算充足,且变更不影响核心链路功能,可以按照自己的节奏继续做变更。
3、如何验证核心链路SLO
3.1容量压测
容量压测的主要作用,就是看 SLO 中的 Volume,也就是容量目标是否可以达成。
另一个作用就是看在极端的容量场景下,验证限流降级熔断等服务治理策略是否可以生效。
3.2Chaos Engineering-混沌工程
混沌工程可以帮助我们做到在线上模拟真实的故障,做线上应急演练,提前发现隐患。
容量压测是模拟线上真实的用户访问行为,混沌工程是模拟故障发生场景,主动产生线上异常和故障。
混沌工程是 SRE 稳定性体系建设的高级阶段,一定是 SRE 体系在服务治理、容量压测、链路跟踪、监控告警、运维自动化等相对基础和必需的部分非常完善的情况下才能考虑。
4、如何选择系统验证的时机
参考:Google的建议
4.1错误预算充足就可以尝试,尽量避开错误预算不足的时间段。因为在正常业务下,我们要完成 SLO 已经有很大的压力了,不能再给系统稳定性增加新的风险。
4.2评估故障模拟带来的影响,比如,是否会损害到公司收益?是否会损害用户体验相关的指标?如果造成的业务影响很大,那就要把引入方案进行粒度细化,分步骤,避免造成不可预估的损失。
4.3选择业务量相对较小的情况下做演练。这样即使出现问题,影响面也可控,而且会有比较充足的时间执行恢复操作,同时在做全链路压测之前,先进行单链路和混合链路演练,只有单链路全部演练通过,才会执行更大规模的多链路和全链路同时演练。
4.4生产系统稳定性在任何时候,都是最高优先级要保证的。不能因为演练导致系统异常或故障,这是不被允许的。所以,一定要选择合适的时机,在有充分准备和预案的情况下实施各类验证工作。

