
全链路压测(2):方案调研和项目立项
前言
全链路压测从零开始系列的第一篇文章介绍了全链路压测的背景、定义、和传统压测的差异以及如何解决差异带来的不稳定性,
落地要面临的挑战和完整的压测实践流程以及长期的能力建设演变,算是对全链路压测有了一个比较系统和全面的介绍。
本篇是系列的第二篇,从这篇文章开始,我会基于自己的个人落地实践经验,给大家分享从零开始落地全链路压测,要做哪些事情,以及这个过程中遇到的挑战、踩过的坑以及该如何解决这些问题。
申报立项
一般来说,像生产全链路压测这种复杂的需要多个技术团队参与的复杂技术项目,在企业内部都会有一个项目申报和评估立项的过程。
项目申报
下面是一个项目申报的模板,大家可以参考下:
|
背景 |
为什么要做这件事?(线上故障频发,性能问题凸显,云资源成本太高) |
|
目的 |
为了解决什么问题?(降低线上故障率和损失,降低硬件成本) |
|
方案 |
具体的解决方案是什么?(生产环境全链路压测) |
|
价值 |
做这件事带来的价值是什么?(提高用户体验,团队练兵,保障业务价值的实现) |
|
资源 |
做这件事需要什么资源?(研发、运维、DBA、测试等) |
|
时间 |
什么时候开始,什么时候上线? |
评估立项
项目申报后,就是多方评估是否立项的环节,在这个环节,主要有如下几件事:
- 目前存在的问题是否真的有这么严重?
- 这些问题如果不解决是否会对业务造成影响?
- 做这件事,能否解决目前存在的问题?
- 做这件事,要投入的时间资源和对业务及团队的价值,有多大?
- 这件事的优先级有多高?
调研评估
在项目正式启动前会有个调研环节。这里的调研主要指的是基于自身当前所处阶段及面临的问题和实现生产全链路压测之间的差异,以及如何解决差异的解决方案。
我个人总结下来,方案调研可以分为如下四个阶段:
看:大厂都是怎么做的?
全链路压测是个技术复杂度比较高的跨团队的技术项目,最初也是大厂的自留地。
在调研方案时候,有必要看看大厂都是如何做的,避免走太多弯路。前面提到了落地生产全链路压测的几个挑战,下面我从这几个挑战点来做个梳理对比,帮大家快速的了解,大厂是如何做的。
|
挑战点/大厂 |
阿里 |
美团 |
京东 |
滴滴 |
饿了么 |
|
核心链路梳理 |
鹰眼系统 |
/ |
trace系统 |
/ |
|
|
数据安全隔离 |
流量/线程染色透传 影子库表 |
流量/线程染色透传 影子库表 |
流量/线程染色透传 影子库表+特殊标记 |
流量/线程染色透传 影子库表 |
流量/线程染色透传 特殊标记(逻辑隔离) |
|
避免业务侵入 |
/ |
/ |
/ |
/ |
/ |
|
性能定位分析 |
/ |
/ |
/ |
/ |
/ |
|
服务安全保护 |
/ |
/ |
/ |
/ |
/ |
PS:针对上表的一些术语和“/”内容,这里做个说明。
1、链路梳理
现在大多数企业都是采用微服务架构来设计系统,且业务场景多样化,导致了系统架构异常复杂。
要覆盖所有压测范围内的场景,就需要对涉及的所有应用及其调用关系进行梳理,手工来梳理,耗时且费力。
上面提到的几家大厂的鹰眼啊Mtrace系统之类的,实际上都是基于分布式链路追踪工具自研或二次开发的。
分布式链路追踪工具,推荐开源的Jaeger,Jaeger是Uber推出的一款开源分布式追踪系统,兼容OpenTracing API。
分布式追踪系统用于记录请求范围内的信息,例如,一次远程方法调用的执行过程和耗时。是排查系统问题和系统性能的利器,同时在链路梳理方面,能提高很多效率。
Jaeger的UI相较于Zipkin更加直观和丰富,还有则是sdk比较丰富,go语言编写,上传采用的是udp传输,效率高速度快。
- Github地址:jaegertracing/jaeger
- 官方地址:Jaeger: 开源分布式端到端链路追踪系统
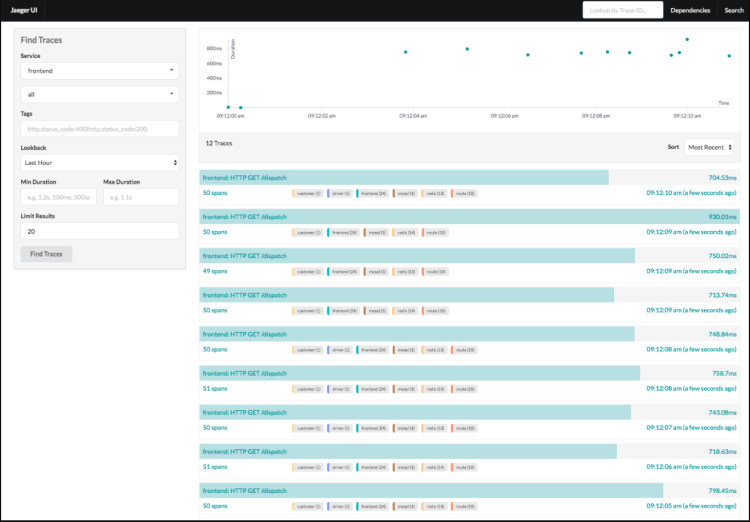
2、数据隔离
- 流量染色:对于单服务来说,识别压测流量只要在请求头中加特殊压测标识即可,HTTP和RPC服务是一样的。
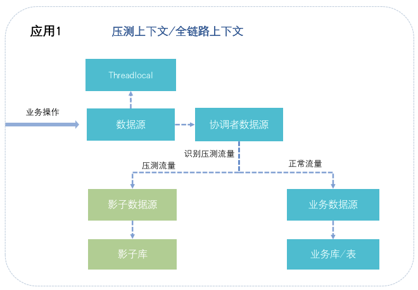
- 影子库表:核心思想是使用线上同一个数据库实例,包括共享数据库实例中的内存资源,因为这样才能更接近真实场景,只是在写入数据时会写在另一个“影子库表”中。大概原理如下:
3、避免业务侵入
如果要通过修改业务应用或者采用数据库表数据标记的方式来实现,势必会对生产业务造成一定影响(要改造需要大量资源和时间)。
4、性能定位分析
全链路压测的初衷还是为了发现并解决系统在峰值流量冲击下的稳定性问题,因此性能定位分析的工具和完善的监控体系是必备的。一般在企业级技术监控领域,大体分为五种类型的监控:
- 基础监控:包括带宽、CDN、服务器CPU、Memory、DiskIO、Network、Load5等指标;
- 指标监控:服务+接口维度,常见指标有QPS、TPS、SLB、RT、99RT、timeout、activethreads等指标;
- 业务监控:拿电商来说,常见的有同比下单量、支付量、履约率、DAU、GMV、支付取消率等多重指标;
- 链路追踪:如上面提到的Jaeger,是排查系统问题和系统性能的利器,同时在链路梳理方面,能提高很多效率;
- 舆情监控:主要指对外部的一些讯息的监控,比如某APP突然挂了、下不了单、有BUG可以刷单、客诉等一些列对企业或者品牌不利的因素,便于快速处理甚至公关;
5、服务安全保护
全链路压测是在生产环境进行,压测过程中,要考虑不对生产服务造成影响。因此需要一套完整的机制来保证,压测在正常实施的同时,不对生产服务应用造成影响。一般都会通过熔断和流量干预的机制来保证。
听:SaaS服务商怎么说?
国内全链路压测的SaaS服务商,目前只有2家:数列科技和perfma。这里以我比较熟悉的数列的SaaS产品举例子,他们的全链路压测产品主要优势有如下几点:
- 业务代码0侵入:在接入、采集和实现逻辑控制时,不需要修改任何业务代码;
- 链路自动梳理:仅需部署客户端,无需对应用进行任何改造,就可以看到所有的服务调用关系,快速理解系统架构,并且通过链路架构图可以详细了解链路经过的应用、缓存、中间件、DB,甚至第三方的API,每条链路的所有走向都一目了然;
- 数据安全隔离:在不污染生产环境业务数据情况下进行全链路压测,可以对写类型接口进行直接的性能测试;
- 安全性能压测:在生产环境进行性能压测,对业务不会造成影响;
- 性能瓶颈快速定位:性能测试结果直接展现业务链路中性能瓶颈的节点;
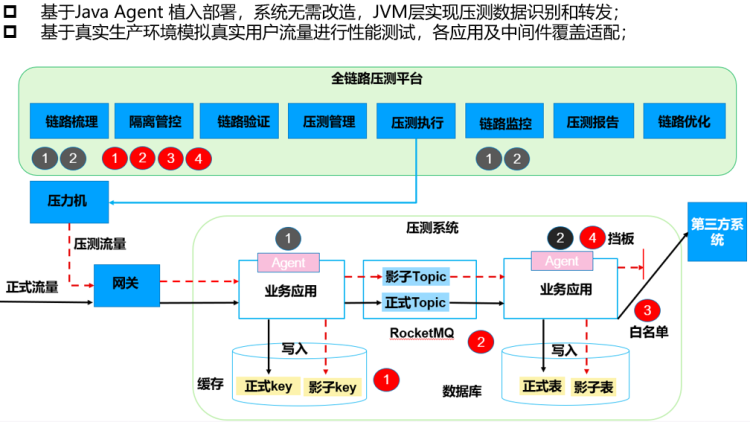
而且今年他们已经将自己的全链路压测产品开源了,并且支持多环境压测,下面是他们的压测多环境支持流程图:
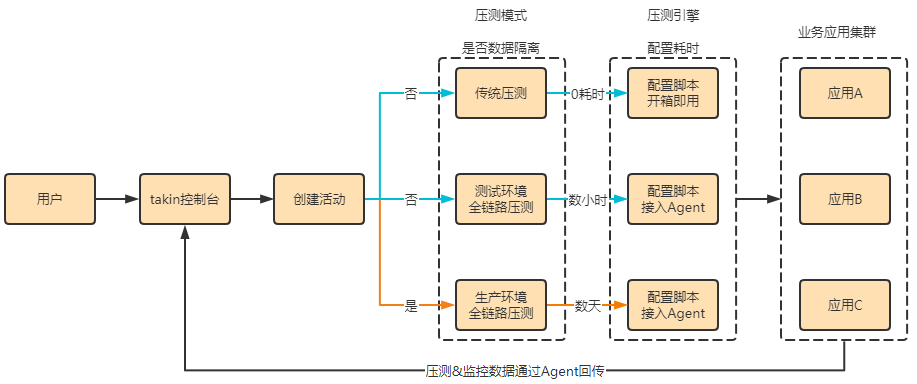
Github地址:开源全链路压测平台Takin
做:小范围接入改造看效果
看完大厂是怎么做的,以及SaaS服务商的产品,接下来就是要进行小范围验证了。一般进行小范围接入改造,主要有如下几点需要注意:
- 环境:如果有多套测试环境,可以选择一套使用率较低的,否则建议临时单独搭建一套缩容的环境进行改造接入以及测试验证;
- 业务:前期在调研验证阶段,建议选择核心业务对应的应用服务来进行验证,这样更方面了解具体的效果是否达到预期(当然,在落地阶段,刚开始建议选择非核心业务);
- 资源:这里主要指人力资源,在项目立项后,建议有专门的人手资源来做这件事,否则项目很容易延期甚至无疾而终,在工作产出考核上,也不太好;
评:自研或SaaS产品的ROI
经过上述三个阶段的调研和验证,这里需要对项目最终的整套解决方案做一个选型确定:是选择自研还是SaaS服务商的全链路压测产品。
从我个人的落地实践经验和了解来说,无论是自研,还是选择SaaS服务商,需要考量的因素主要有如下几点:
1.研发能力:一般来说,大厂或者中大型独角兽公司,研发能力和资源相对会比较强,且出于造轮子和KPI的目的,选择自研是相对来说比较好的方案。
当然对于中小型企业来说,研发能力和资源会弱一些,这种情况我建议还是选择三方服务商的SaaS服务或者开源产品,性价比会更高一些;
2.业务接受能力:如果是自研,特别是选择改造业务代码的方案时,一定要考虑到业务的接受能力。因为每次变更都会对线上带来新的不稳定因素,且改造占用的时间和资源会和业务需求迭代有所冲突。
如果是中间件层面改造或者采用的是无侵入的SaaS产品及开源产品,那么相对来说这个矛盾就仅限于技术团队内部;
3.项目预算投入:这里的预算包括时间、风险、需要投入的人力物力等。
4.ROI(投入产出比):实际上一个项目到了最后,要不要做的最终考虑因素就是投入产出比,以更低的风险和成本解决更大范围的严重问题,永远是优先级最高的。
总结
本篇主要对全链路压测的项目立项和调研环节要考量的点以及业内的一些方案&SaaS及开源产品做了介绍。
下一篇开始,会介绍落地实践过程中具体要做的一些事情,包括工具选型、流量评估等,会结合具体的业务场景来为大家分享如何从零开始的落地全链路压测。
建了一个全链路压测沟通交流群,目前群人数已超过100,想加群的同学请公众号回复关键字:全链路压测。
添加我好友,我邀请进群,加群请备注说明来意。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2018-10-09 Locust:简介和基本用法