什么是KMP算法?KMP算法推导
花了大概3天时间,了解,理解,推理KMP算法,这里做一次总结!希望能给看到的人带来帮助!!
如果你觉得有帮助,欢迎分享给其他人!送人玫瑰手有余香!
欢迎留言,哪怕一个字,大家的鼓励就是我写作的动力!
如果你觉得写的很烂,请告诉我哪里写的不好,我尽量调整!
1.什么是KMP算法?
在主串Str中查找模式串Pattern的方法中,有一种方式叫KMP算法
KMP算法是在模式串字符与主串字符匹配失配时,利用已经匹配的模式串字符子集的最大块对称性,让模式串尽量后移的算法。
这里有3个概念:失配,已经匹配的模式串子集,块对称性
失配和隐含信息
在模式串的字符与主串字符比较的过程中,字符相等就是匹配,字符不等就是失配;
隐含信息是,失配之前,都是匹配。
在主串S[0,100]中查找模式串P[0,6],从下标0开始查找,在下标为5的位置失配,记为P[0,5]失配,则有
P[5]!=S[5],又有S[0,4]=P[0,4]
则P[0,4]都是匹配的!
已经匹配的模式串子集
接上一例,模式串是P[0,6],而P[0,4]都是匹配的,所以,已经匹配的模式串子集有
Pcs={ P[0,4],P[0,3],P[0,2],P[0,1],P[0] }
2.块对称性
什么是块对称性?
块对称性,就是字符串前缀,后缀重叠;
比如: a b c d a b c
前缀:除了最后一个字母外,所有的前缀子集;
如: a,ab,abc,abcd,abcda,abcdab
后缀:除了第一个字母外,所有的后缀子集
如: bcdabc,cdabc,dabc,abc,bc,c
这里前缀abc和后缀abc重合

可以把这个重合看做,相对于绿块对称,所以叫它块对称性
块对称有很多种;比如:

咦?大家都在一水平排,怎么有一个飞起来了?
飞起来那个将在利用最大快对称性 小节讲解。
块对称性有什么特点?
特点:拥有块对称性的字符串至少有2块对称重合的的部分;
分析,对称是修饰,重合是关键。而且重合的是前缀和后缀。
如何利用块对称性?

模式串如图,如果模式串和主串Str匹配的过程中,在l这失配即P[0,7]失配,你会怎样?
分析,
第一,模式串的P[0,6]和主串放入S[0,6]是完全匹配的
第二,P[0,6]串是块对称的!
因为P[0,6]刚好有块对称性,我可以把前缀abc移动到后缀abc的位置,然后让d与主串去匹配,这样就利用快对称性了对吧?

总结,可以在P[7]失配时,看失配字符的最大前缀P[0,6]是否有块对称性,如果有,我们就可以向右移动模式串,让左边的重合前缀移动到右边的重合后缀,再让模式串和主串比较!
利用最大块对称性?什么意思?
什么是KMP算法小节里,说KMP是在模式串与主串匹配失配时,利用已经匹配的模式串子集的最大块对称性,尽量让模式串右移!这里的利用最大块对称性是什么意思?
这里利用最大块对称性意味着可能发生递归!
把上个案例的d换成k,如下图:
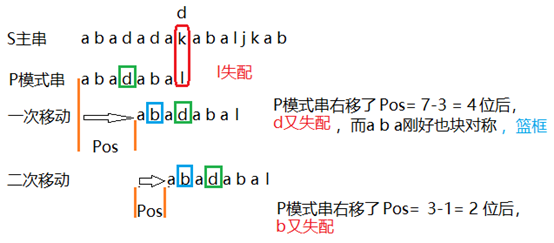
KMP算法会预先计算出模式串所有前缀子集中哪些前缀有块对称性,在这些有块对称性的前缀的后一个字符失配时,利用其块对称性;
比如本例中P[0,6]有块对称性,那么在P[0,7]也就是l失配时,
会先利用P[0,6]的块对称性,即P[0,2]和P[4,6]相遇于字符P[3]块对称,
如果不行,会看P[0,2]块对称重合的部分有没有块对称性,
有,就利用;以此类推,一直递归到没有块对称性为止。
块对称长度的意义-编程
第一次移动中,3是什么?块对称重合长度,也是下次开始比较的位置!
第二次移动中,1是什么?块对称重合长度,也是下次开始比较的位置!

3.next数组推导-计算块对称性
单独的块对称性是没有意义的,块对称性必须结合上失配,才能利用块对称性!
所以,应该计算出Pattern所有前缀子集失配时的块对称性!放到一个叫next[]数组的地方!
如何计算呢?
next数组是计算失配时的块对称性,
当第1个字符失配时,压根就没有前缀后缀的说法,所以有next[0]是不存在块对称性的,记为next[0]=-1;
当第2个字符失配时,它的子集只有1个字符,也是没有前缀后缀,没有块对称性,所以记为next[1]=0;
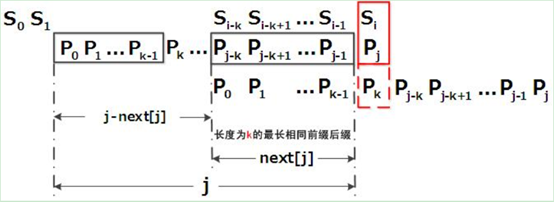
再看图,对于值k,已有p0 p1, ..., pk-1 = pj-k pj-k+1, ..., pj-1,则有next[j] = k。
next[j] = k代表了什么呢?
代表在Pj之前,有长度为k的块对称性,有2个长度为k的重合部分。
总结一下,前提条件如下:
条件1.next[0]是不存在的,next[1]=0;
条件2.对于下标值k,已有p0 p1, ..., pk-1 = pj-k pj-k+1, ..., pj-1,则有next[j] = k。
next[]数组是从0开始被初始的,如果我们能推导出next[j+1] = 什么,是不是就可以计算出next[]数组? 是吧
下面来推导next[j+1]
已知:
p0 p1, ..., pk-1 = pj-k pj-k+1, ..., pj-1,==》 next[j] = k
如果pk与pj匹配,
则有p0 p1, ..., pk-1,pk = pj-k pj-k+1, ..., pj-1pj,==》 next[j+1] = k+1;
原来有2个长度为k的对称重合部分,pk与pj匹配后,2个长度为k对称重合的部分又有了1对字符重合,所以有next[j+1]=k+1;
再看图,next[j]=k,当pj失配时,下一次用pk去和主串匹配;所以next[j]的实际意义是,当pj失配时,下一次应该用哪个字符去和主串匹配!!
条件3.next[ ]数组的值就是当次失配时,下一次匹配的位置!
如果pk与pj不匹配,next[j+1]=?
next[j+1]的实际意义是,p[0,j+1]的pj+1失配时,p[0,j]的块对称重合长度,也是下一次匹配时应该用模式串的哪个字符与主串匹配,哪个字符的下标就是next[j+1]。
具体详参块对称长度的意义-编程
下一次用哪个字符比较呢?
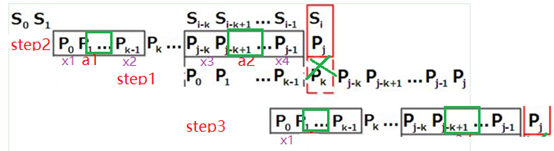
设a1=p0 p1,...,pk-1,a2=pj-k pj-k+1,...,pj-1;a1==a2
当pk与pj不匹配时,不能用a1替换a2,如图绿叉;
因为a2是离与主串最近的部分,所以这时候应该分析a2是否有块对称性,
如果a2有块对称性,那么a1也有块对称性,如图绿框;
所以,这时应该分析p[0,k]的块对称性,也就是next[k]。
设x1与x2关于绿框对称;
x3与x4关于绿框对称;
那么把x1移动到x4的位置,是不是就可以最大利用上;
所以next[j+1]=next[k];
总结一下
If ( p[k] == p[j] ) next[j+1]=k+1
else next[k+1]= next[k]
4.参考文献
https://blog.csdn.net/v_july_v/article/details/7041827
http://www.codeceo.com/kmp-next-array.html
https://www.zhihu.com/question/21474082 next数组推导
https://blog.csdn.net/yearn520/article/details/6729426 next数组推到原则
KMP中,计算目标查询串T的next[]数组是关键;
https://zhuanlan.zhihu.com/p/24274982
https://blog.csdn.net/yearn520/article/details/6729426
http://www.cnblogs.com/c-cloud/p/3224788.html
https://zhuanlan.zhihu.com/p/24649304

 浙公网安备 33010602011771号
浙公网安备 33010602011771号