Apache Flink——介绍
1 引入
作为大数据主流运用的计算引擎之一,Flink近年来的发展趋势是非常惊人的,一方面是Flink自身的不断迭代更新,另一方面是选择应用Flink框架的平台越来越多。作为一个年轻的大数据计算引擎,还有很多人对Flink还不够了解。那么Flink是什么?
在Flink之前,主流的计算框架以Hadoop和Spark占据主流。Hadoop可以算得上是第一代大数据计算框架,能够很好地完成批处理任务;而其后的Spark,则是在Hadoop的基础上进行性能的提升,内存计算、迭代计算,实现了计算性能上的大大提升。
而随着流处理概念的兴起,Spark又开始显现出了不足,因此催生了Flink。Flink框架可以说是实现真正意义上的实时流处理,大大降低了流计算的延迟,更能满足当下的大数据处理需求,因此得到众多平台的重用。
Flink真正开始在大众范围内普及,是在2015年左右,但是其实早在2008年,Flink就已经在开始初步研发了,直到2014年进入Apache孵化器,随后成为Apache的顶级开源项目之一。
Flink是一个针对流数据和批数据的分布式处理引擎。对Flink而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。在Flink框架当中,所有的任务当成流来处理,因此实现了更低延迟的实时流处理。
发展至今,Flink生态圈也逐步开始完善。Flink首先支持了Scala和Java的API,Python也在测试中。Flink通过Gelly支持了图操作,还有机器学习的FlinkML。
为了更广泛的支持大数据的生态圈,Flink也实现了很多Connector的子项目,比如与Hadoop HDFS集成。并且,Flink也宣布支持了Tachyon、S3以及MapRFS。
True stream processing engine
Stream processing is a rapidly-growing data processing paradigm范例 for real-time实时分析 analytics and event-driven事件驱动 applications. Apache Flink is a distributed data processing framework for stateful有状态 computations over unbounded and bounded data streams.
2 Features of Flink
- Next-generation engine for stream processing
- Low latency & high throughput
- Robust Fault tolerance, apps应用程序 start exactly where they failed
- Rich set of libraries
- App state is re-scalable应用状态可重新缩放, possible to add resources while the app is running
- Exactly once semantics语义
- Event Time Handling处理
- State management
3 Batch Vs Stream
Streaming — a type of data processing engine that is designed with infinite data sets无限数据集 in mind考虑
In batch processing, we first collect & then push for processing. Since the data being processed is accumulated积累的 in advance it is bounded data. This mode方式 of processing is useful for historical fact-finding历史事实调查. It is query driven strategy.
In stream processing, we feed the data to the processing engine as soon as就 it arrives. Since data is not accumulated beforehand事先 it is unbounded data. This processing is useful for live fact-finding实时事实调查. It is a data-driven strategy.
Stream processing can be both stateless as well as stateful.流处理既可以是无状态的,也可以是有状态的。
Stateful stream processing means a “State” is shared between events(stream entities). And therefore past events can influence the way current events are processed当前事件的处理方式.
4 Flink Ecosystem
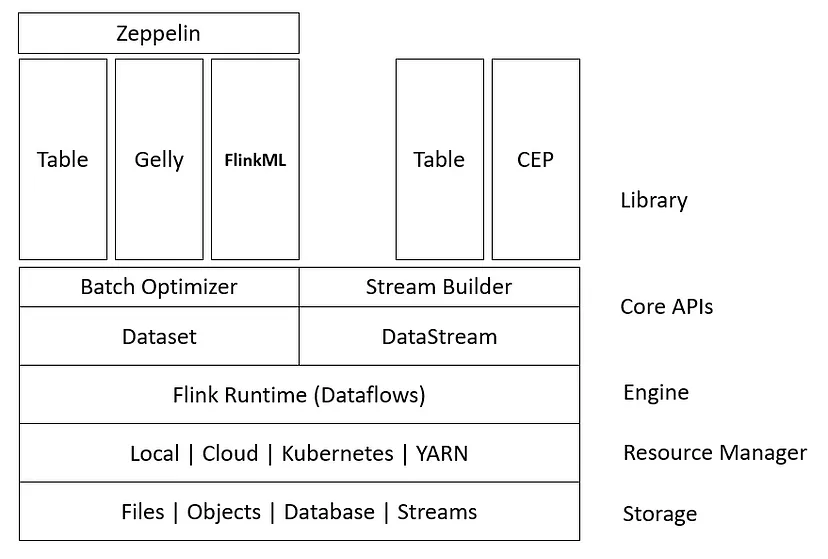
Flink’s architecture is based on a distributed dataflow programming model where data is processed as a series of transformations转换 on distributed data streams.
5 Components of Flink
- Client — Submits Jobs (Data Flow Graph)
- Job manager — Accepts the task. It transforms the DFG submitted by the client into an ExecutionGraph for event execution. It has the following以下 services. Dispatcher — Starts a new Job master for each submitted job. Job Master — Manages the execution of a single job. Resource Manager — Assigns the tasks to the task managers for execution. Checkpoint coordinator协调器 — Ensures fault tolerance. The dispatcher also powers支持 a web dashboard仪表板 & HTTP endpoint端点 that provide information about job executions.
- Task manager — Executes the tasks (Can be one or more). These Task Managers contain slots. Slots are an abstraction used to represent表示 CPU & memory resources available on Task Manager. Slots are smallest unit of resource scheduling. Each task runs within a task slot.
- Actor system: Part of Akka framework. Provides services such as scheduling, configuration, logging, etc.
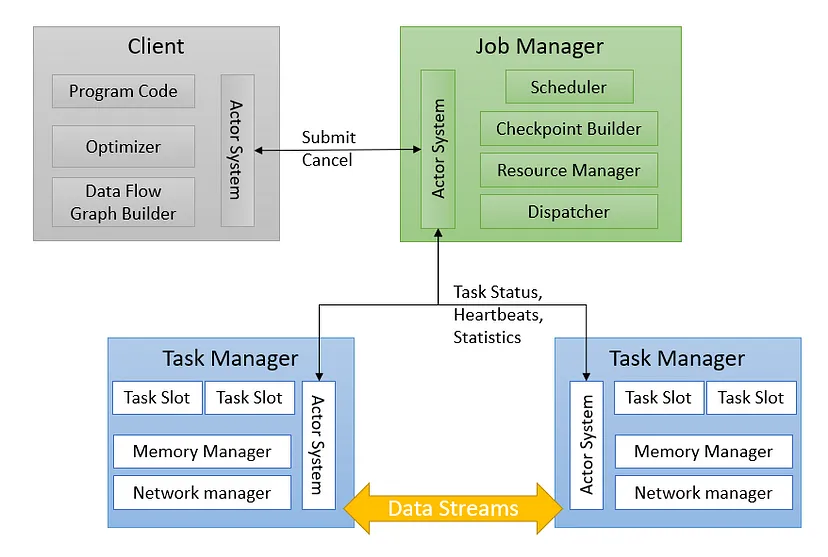
Flink application is represented as a Job graph, where the nodes are the operators and links determine决定 the input and output, to and from various operators. Task manager has one or more Task slots that provide an execution environment for the tasks.
Apache Flink is built on Kappa Architecture.
6 Data Transfer
TaskManager leverages利用 a pool of network buffers to send and receive data. The sender task serializes the records into a byte buffer and puts the buffer into a queue. The receiver task takes the buffer from the queue and de-serializes the incoming records. If the tasks are in the same process, there is no need for a network connection.
6.1 Flink Data Exchange Strategy
Forward | Broadcast | Key-based | Random
Flink also leverages Credit based flow control流量控制, task chaining任务链 for data transfer数据传输.
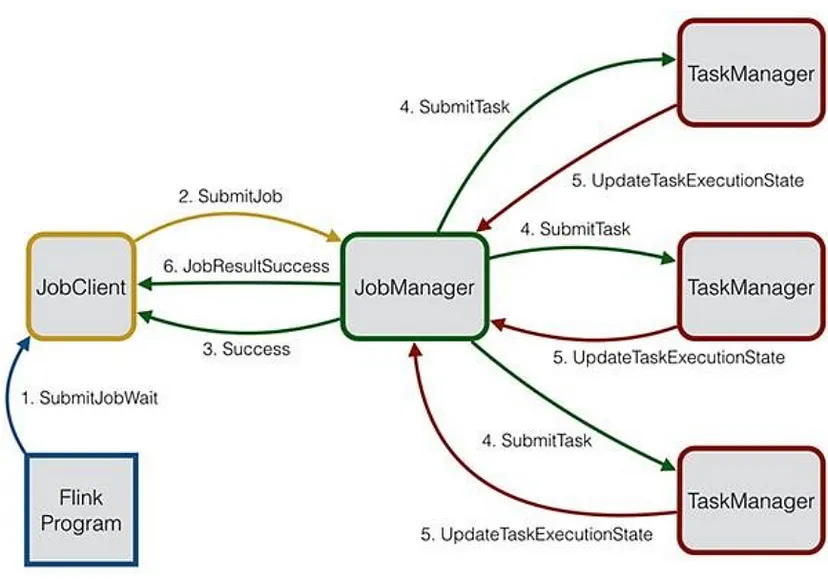
7 Program flow
8 Operators
In Flink, each function like map, filter, reduce, etc is implemented as a long-running长时间运行 operator. There are the following major operators:
Map | FlatMap | Reduce | Filter | Iterate | Window | KeyBy
A task is one parallel instance of an Operator or Operator chain.
9 Window
Windows split the streams into “buckets桶” of finite size, over其上 which computations can be applied.
Tumbling | Sliding | Session | Global
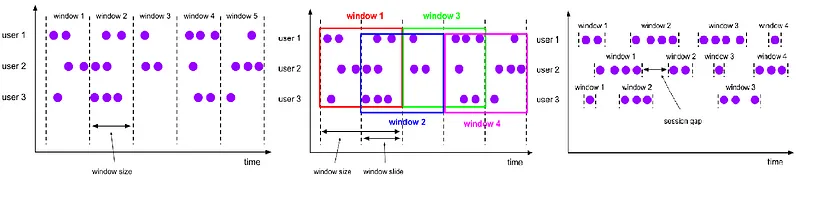
Trigger — A Trigger determines when a window should be evaluated评估 to emit the results for that part of the window.
Evictors — An Evictor can remove elements from a pane窗格 before/after the evaluation of WindowFunction and after the window, evaluation求值 gets triggered by a Trigger.
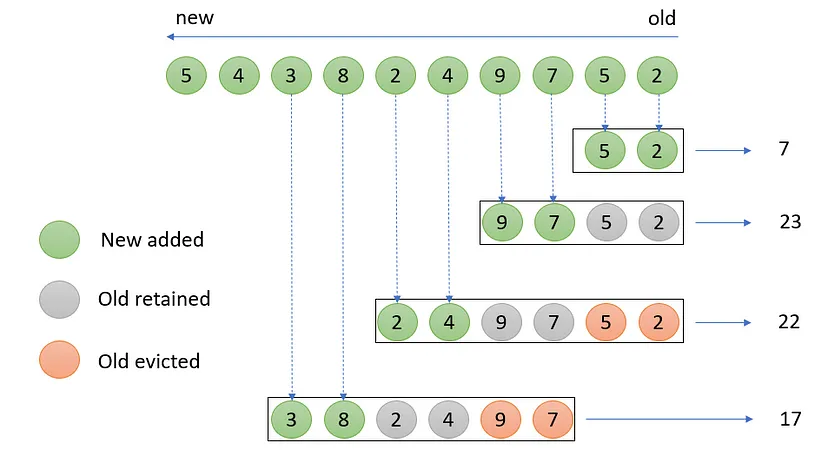
Watermarks — Watermark(t) indicates that all data with a timestamp not greater than t has arrived, and will not come again in the future, so the window can be safely triggered and destroyed.
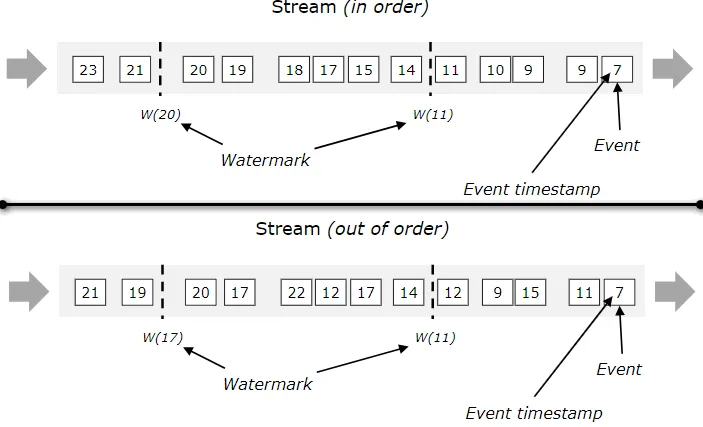
10 Time Notions
- Processing time — time of a particular machine that will process the specific element. This is the default in Flink.
- Event time — It is the time when an event is generated at the source. It’s the actual time实际时间 of an event.
- Ingestion摄入 time — It is a time when the Flink receives an event for processing.
11 Fault tolerance
State — State can be considered as memory in operators that remember information about past input. Each task manager maintains its own Rocks DB file and the backup of its state. RocksDB as backend后端 is a good option when:
- The state of our job is larger than what can fit in local memory
- We need incremental checkpointing增量检查点
- We need predictable latency
Flink supports two types of the state namely, Operator & Keyed State.
Checkpoints — Task managers take a backup备份 of their state and store it in a durable持久 store (such as HDFS) at regular intervals定期, this is called checkpoints.
Savepoints — When a user, using an API, manually takes a backup of the cluster state then it is called Savepoint.
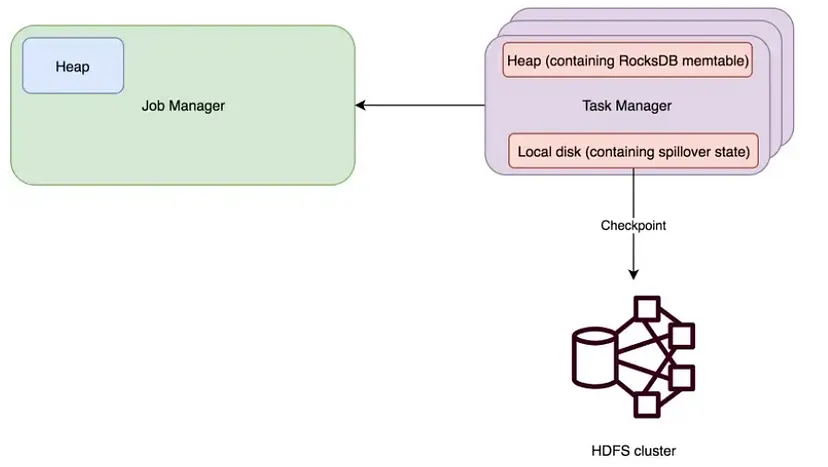
The state persistence持久性 in the filesystem has the following file pattern.

hdfs:///path/to/state.checkpoints.dir/{JOB_ID}/chk-{CHECKPOINT_ID}/
12 Scalability
In Flink, re-scaling重新缩放 is done by redistributing重新分配 the “state” to its worker machines. When Flink receives a re-scaling request then it will take the saved state from HDFS (checkpoint) and then redistribute it to more instances of the operator. This requires a job restart.
Using an adaptive scheduler Flink automatically upscales/downscales Flink application when the amount of data to process increases or decreases.
Flink also supports a reactive mode where Flink will add more Task Managers. Flink decides when to add and remove Task Managers based on resource availability. In K8s-based deployment, a Horizontal Pod autoscaler is used.
13 Data & Task Parallelism
14 Spark & Flink
RDD → Dataflows
SparkMLib →FlinkML
Custom Memory Management →Automatic Memory Manager
DAG-based Execution Engine →Cyclic Dependency Graph
Second latency →Sub second latency
Explicit Backpressure → In built backpressure setting
15 Deployment Mode
Session — Shared job manager
Application — Dedicated Job Manager
Deployments部署 also have modes Active主动 & passive被动 in terms of resource readiness准备.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号