lambda表达式和闭包的区别
Closures的诞生
LISP是世界上第二款高阶编程语言(第一款是IBM的FORTRAN),也是第一款函数式编程语言,诞生于1958年,它是基于lambda演算设计的。
而LISP中有一个特性,而后将函数作为一等公民的编程语言都有这个特性——Functional Arguments,也就是说函数可以作为参数存在,它可以赋值给变量,也可以作为其它函数的入参,或者作为其它函数的返回值。
但是实现Functional Arguments有一个难点,简称为FUNARG Problem,这是当初编程语言设计者们的难题,长达十几年的时间里有没有很好的解决方案。
而FUNARG problem 发生在一个函数返回另一个持有自由变量的函数时。
例如下面这一段代码:
DEFINE F(X) TO BE
LET G(Y) BE
RETURN X^2 + Y^2
END
RETURN G
END
P ← F(3)
调用F(3)返回了一个函数G,将它赋值给P,以便后面可以通过P调用这个函数。这个函数引用了一个值为3的自由变量,所以系统需要将这个binding(标识符和值的映射)记录下来。这有什么难的吗?是的,非常难,因为早期语言都使用动态作用域,为了能继续解释FUNARG问题,这里需要先解释下动态作用域和静态作用域。
我们先来说说词法作用域(lexical scoping),也可以称为(static scoping)静态作用域。
现在的大部分语言都使用的是词法作用域,词法作用域的意思是:变量的作用范围取决于它在源代码中定义的位置,在词法解析阶段即可确定(例如static修饰符)
例如在java中:
class Foo {
int a = 1;
void foo() {
int b = 2;
}
}
a的作用范围在整个Foo对象中,而b的作用范围仅仅只在foo函数中。
而动态作用域则相反,变量的作用范围取决于函数的调用链,例如:
DEFINE foo() TO BE
PRINT A
END
DEFINE bar(X) TO BE
A = X + 1
foo()
END
A = 2
bar(A) // 打印 3
foo() // 打印 2
同样是打印A,但是通过不同调用路径,最终打印出不同的值。
为了更直观的描述动态作用域,这里画了一张图:在动态作用域的语言中,binding一般都使用符号表堆栈记录(symbol table stack),当函数调用时都会为它创建一张新的表记录去它当中定义的局部变量和形参,防止和函数外部的相同标识符混淆,例如S0和S1都拥有A这个符号,但是它们分别保存着不同的值,互不影响。另外,每张符号表都会和它的上一张表关联,形成一条调用链。而函数就是通过回溯这条调用链查找变量的值,如果所有表中都找不到该标识符,那么就会抛出一个error。
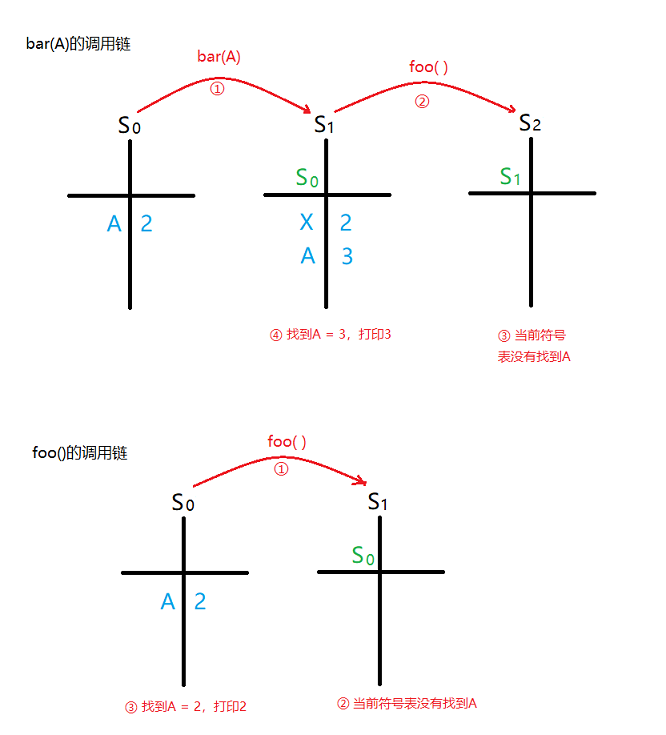
好了,说完动态作用域的问题,那么我们回到FUNARG Problem中。之前说到,系统需要将P代表的函数中引用到的自由变量的binding记录下来,但是想保存这组binding是非常困难的,因为要防止命名冲突的情况,否则每次调用P的执行结果都可能不一致。这就是所谓的FUNARG Problem,它是程序设计者们需要解决的。
应该是1964年左右,因为Peter J Landin(后面简称兰丁)在这时候提出了闭包概念
在当时,为了解决FUNARG问题,在LISP的某些版本和兰丁的SEGD用符号表树(symbol table tree)代替符号表栈(symbol table stack),为了讲述什么是闭包,我们来看下面这种情况。
LET G(X) BE
LET F(Z) BE
RETURN Z^2 + X
END
RETURN F
END
FA ← G(1)
FB ← G(2)
FA(3) // 期望结果是10
FB(3) // 期望结果是11
如上面的代码所示,FA和FB都持有一个自由变量X,而我们期望FA的值是10,而FB的值是11,虽然它们拥有相同的入参,但是它们持有的自由变量X的值不一样。而如何保存自由变量X的值呢?当时所有语言的都是使用符号表栈来保存binding,这意味着FUNARG问题无法解决,更何况这里需要保存三个不同的X,而解决这一方案的方法就是符号表树。
符号表栈在解释动态作用域的时候就已经画过图。
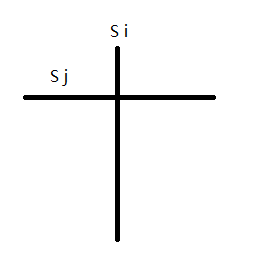
Si是当前符号表的名字,Sj则是上一张符号表的名字,下半部分则是binding的信息。
而符号表树的图就有点区别, 多了个Sk区域,表示可以从Sk中找需要的binding,而不是顺着Sj回去找。
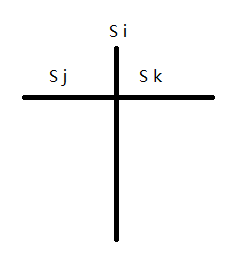
好了,我们回来这段代码:
LET G(X) BE
LET F(Z) BE
RETURN Z^2 + X
END
RETURN F
END
FA ← G(1)
FB ← G(2)
FA(3) // 期望结果是10
FB(3) // 期望结果是11
当G(1)调用时,符号表是这样的:
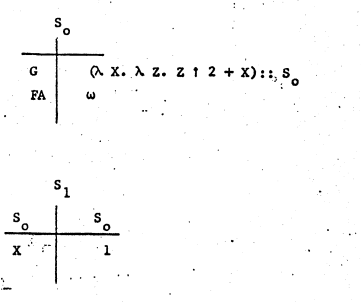
(λx. λz. z ^ 2 + x)::S0,函数可以用lambda的形式存储在栈中,S0则表示这个函数中的binding在S0中搜索。 ω 则表示这个值还未初始化。当G(1)执行时,创建一个新的表S1。
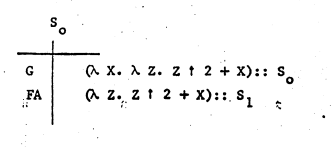
当G(1)执行完毕后FA也有了个值,它引用了S1这张表,而S1中保存着X = 1这个binding。
同理,当G(2)执行后,如下:
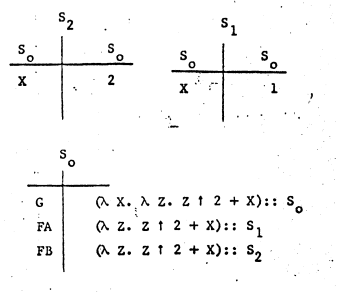
FB也引用了一张S2的表,其中保存着x = 2这个binding。
当FA(3)调用时,新建了一张S3的表:
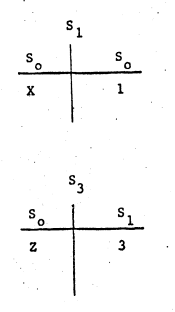
从S1中查找到自由变量X的值,最终计算出结果为10
同理,FB的值为11。
S0引用着S1和S2这两张子表,这就是所谓的符号表树。而引用着子表的lambda表达式也被称为closure。
lambda表达式和闭包的区别
There is a lot of confusion around lambdas and closures, even in the answers to this StackOverflow question here. Instead of asking random随机询问 programmers who learned about closures from practice with certain programming languages or other clueless无能为力 programmers, take a journey to the source (where it all began). And since lambdas and closures come from Lambda Calculus invented by Alonzo Church back in the '30s30 年代 before first electronic computers even existed, this is the source I'm talking about.
Lambda Calculus is the simplest programming language in the world. The only things you can do in it:►
-
APPLICATION: Applying one expression to another, denoted表示为
f x.
(Think of it as a function call, wherefis the function andxis its only parameter) -
ABSTRACTION抽象: Binds a symbol occurring in an expression to mark that this symbol is just a "slot", a blank box空白框 waiting to be filled with value, a "variable" as it were. It is done by prepending前置 a Greek letter希腊字母
λ(lambda), then the symbolic name (e.g.x), then a dot.before the expression. This then converts the expression into a function expecting期待 one parameter.
For example:λx.x+2takes the expressionx+2and tells that the symbolxin this expression is a bound variable绑定变量 – it can be substituted取代 with a value you supply as a parameter.
Note that the function defined this way is anonymous – it doesn't have a name, so you can't refer to it yet, but you can immediately call it (remember application?) by supplying it the parameter it is waiting for, like this:(λx.x+2) 7. Then the expression (in this case a literal文字 value)7is substituted asxin the subexpressionx+2of the applied lambda, so you get7+2, which then reduces to9by common arithmetics算术 rules.
So we've solved one of the mysteries:
lambda is the anonymous function from the example above,λx.x+2.
In different programming languages, the syntax for functional abstraction (lambda) may differ. For example, in JavaScript it looks like this:
function(x) { return x+2; }
and you can immediately apply it to some parameter like this:
(function(x) { return x+2; })(7)
or you can store this anonymous function (lambda) into some variable:
var f = function(x) { return x+2; }
which effectively有效地 gives it a name f, allowing you to refer to it and call it multiple times later, e.g.:
alert( f(7) + f(10) ); // should print 21 in the message box
But you didn't have to name it. You could call it immediately:
alert( function(x) { return x+2; } (7) ); // should print 9 in the message box
In LISP, lambdas are made like this:
(lambda (x) (+ x 2))
and you can call such a lambda by applying it immediately to a parameter:
( (lambda (x) (+ x 2)) 7 )
OK, now it's time to solve the other mystery: what is a closure. In order to do that, let's talk about symbols (variables) in lambda expressions.
As I said, what the lambda abstraction does is binding a symbol in its subexpression, so that it becomes a substitutible可替代的 parameter. Such a symbol is called bound. But what if there are other symbols in the expression? For example: λx.x/y+2. In this expression, the symbol x is bound约束 by the lambda abstraction λx. preceding it其前面. But the other symbol, y, is not bound – it is free. We don't know what it is and where it comes from, so we don't know what it means and what value it represents, and therefore we cannot evaluate评价 that expression until we figure out what y means.
In fact, the same goes同样的 with the other two symbols, 2 and +. It's just that we are so familiar with these two symbols that we usually forget that the computer doesn't know them and we need to tell it what they mean by defining them somewhere, e.g. in a library or the language itself.
You can think of the free symbols as defined somewhere else, outside the expression, in its "surrounding周围 context", which is called its environment. The environment might be a bigger expression that this expression is a part of (as Qui-Gon Jinn said: "There's always a bigger fish" 😉 ), or in some library, or in the language itself (as a primitive).
This lets us divide lambda expressions into two categories:
-
CLOSED expressions: every symbol that occurs in these expressions is bound by some lambda abstraction. In other words, they are self-contained; they don't require any surrounding context to be evaluated. They are also called combinators组合器.
-
OPEN expressions: some symbols in these expressions are not bound – that is, some of the symbols occurring in them are free and they require some external information, and thus they cannot be evaluated until you supply the definitions of these symbols.
You can CLOSE an open lambda expression by supplying the environment, which defines all these free symbols by binding them to some values (which may be numbers, strings, anonymous functions aka也称为 lambdas, whatever…).
And here comes the closure part:
The closure of a lambda expression is this particular set of symbols defined in the outer context (environment) that give values赋值 to the free symbols in this expression, making them non-free anymore不再. It turns转变 an open lambda expression, which still contains some "undefined" free symbols, into a closed one, which doesn't have any free symbols anymore.
For example, if you have the following lambda expression: λx.x/y+2, the symbol x is bound, while the symbol y is free, therefore the expression is open and cannot be evaluated unless you say what y means (and the same with + and 2, which are also free). But suppose假设 that you also have an environment like this:
{ y: 3,
+: [built-in addition],#内置加法
2: [built-in number],
q: 42,
w: 5 }
This environment supplies definitions for all the "undefined" (free) symbols from our lambda expression (y, +, 2), and several extra symbols (q, w). The symbols that we need to be defined are this subset of the environment:
{ y: 3,
+: [built-in addition],
2: [built-in number] }
and this is precisely正 the closure of our lambda expression 😃
In other words, it closes an open lambda expression. This is where the name closure came from in the first place, and this is why so many people's answers in this thread are not quite correct 😛
So why are they mistaken? Why do so many of them say that closures are some data structures in memory, or some features of the languages they use, or why do they confuse closures with lambdas? 😗
Well, the corporate marketoids市场人士 of Sun/Oracle, Microsoft, Google etc. are to blame, because that's what they called these constructs in their languages (Java, C#, Go etc.). They often call "closures" what are supposed to be just lambdas. Or they call "closures" a particular特定 technique技术 they used to implement lexical scoping词法作用域, that is也就是说, the fact that a function can access the variables that were defined in its outer scope at the time of its definition. They often say that the function "encloses封装" these variables, that is, captures them into some data structure to save them from being destroyed after the outer function finishes executing. But this is just made-up编造 post factum在它之后 "folklore etymology民间传说词源" and marketing, which only makes things more confusing, because every language vendor供应商 uses its own terminology术语.
And it's even worse更糟糕的是 because of the fact that there's always a bit of truth in what they say, which does not allow you to easily dismiss忽略 it as false 😛 Let me explain:
If you want to implement a language that uses lambdas as first-class citizens, you need to allow them to use symbols defined in their surrounding context (that is, to use free variables in your lambdas). And these symbols must be there even即使 when the surrounding function returns. The problem is that these symbols are bound to some local storage of the function (usually on the call stack), which won't be there anymore when the function returns. Therefore, in order for a lambda to work the way you expect, you need to somehow "capture" all these free variables from its outer context and save them for later, even when the outer context will be gone. That is, you need to find the closure of your lambda (all these external variables it uses) and store it somewhere else (either by making a copy, or by preparing space for them upfront预先, somewhere else than on the stack). The actual method you use to achieve this goal is an "implementation detail" of your language. What's important here is the closure, which is the set of free variables from the environment of your lambda that need to be saved somewhere.
It didn't took too long for people to start calling调用 the actual data structure they use in their language's implementations to implement closure as the "closure" itself. The structure usually looks something like this:
Closure {
[pointer to the lambda function's machine code],
[pointer to the lambda function's environment]
}
and these data structures are being passed around as parameters to other functions, returned from functions, and stored in variables, to represent lambdas, and allowing them to access their enclosing封闭 environment as well as the machine code to run in that context. But it's just a way (one of many) to implement closure, not the closure itself.
As I explained above, the closure of a lambda expression is the subset of definitions in its environment that give values to the free variables contained in that lambda expression, effectively closing the expression (turning an open lambda expression, which cannot be evaluated yet, into a closed lambda expression, which can then be evaluated, since all the symbols contained in it are now defined).
Anything else is just a "cargo cult巫术" and "voo-doo magic诅咒魔术" of programmers and language vendors unaware of the real roots of these notions概念.
原文链接:What is the difference between a ‘closure’ and a ‘lambda’?
一个lambda表达式,没有绑定其它环境时,我们称它为open lambda,而绑定了其它环境的lambda表达式,我们称它们为闭包(closure),评估一个open lambda的结果就是一个闭包。
实际上,上面图中 (λx. x + y)::Si格式表示的值,都属于闭包,包括G,FA,FB。
而关于动态作用域其实还有另一个知识我们需要知道:deep binding(深约束)和shallow binding(浅约束)。
在一开始的有关动态作用域的说明中,按照函数调用顺序遍历找到最近的与之相关的符号,我们称之为浅约束。
而将函数作为参数时,需要将自由变量在单独的一个环境中保存,然后该函数引用这个单独的环境,我们称之为深约束。而这样捆绑起来的整体也就是我们所说的闭包。
换句话说,动态作用域中解决FUNARG问题的技术是深约束,而深约束中使用到的环境和函数这个整体称为闭包。
深约束的实现是非常困难的,另外程序员使用起来也是非常困难的,或者说非常容易出错,因为它需要使用到特殊的关键字标记函数或变量。
而将闭包发扬光大的是Scheme语言(1975年),Scheme是首个使用了词法作用域的LISP方言,据说它评估lambda表达式都会产生闭包,不需要程序员们考虑深约束浅约束的问题,不需要太关心自由变量引发的FUNARG问题。所以闭包也被称为词法闭包,解析器可以通过作用域自己判断产生闭包而不需要通过预定义的关键字去标记它。
总结
闭包起源于早期编译器上的问题(FUNARG问题),关于如何处理函数内引用的外部变量,例如Java就强制你用final修饰自由变量,避免产生歧义。现在这个词用来描述一个环境,函数引用了自由变量而已。
而lambda就更简单,它只是一个编程语言中匿名函数的语法糖,借用了一个数学系统的命名而已。
总的来说,如果想解释闭包是什么,有两种意义,分别是形式上的和概念上的。
-
概念上的闭包:在实现深约束(解决FUNARG问题)的过程中,函数需要引用到一个环境,而函数和这个环境形成的整体我们称为闭包。可以说闭包无处不在,例如对象。
-
形式上的闭包:词法上下文中引用了自由变量的函数,在不同语言中有不同的表现形式,并且衍生了很多运用方式,比如隐藏数据,作为简易对象使用。
相关的一些概念:
-
lambda表达式:可以用来表示函数的语法糖,本质是一个匿名函数。
-
动态/词法作用域:动态作用域中变量的作用范围和函数的调用顺序和定义方式有关,运行时才能确定。而词法作用域中,变量的作用范围是在源代码中就可以确定的。
-
深约束:动态作用域中为了解决FUNARG问题的技术,将引用环境和函数绑定在一起,函数会在绑定的环境中查找binding,实现起来非常困难。
-
浅约束:动态作用域的查找binding的默认工作方式,函数通过遍历调用过程,找到最近的binding。
简单介绍和闭包相关的大佬:
- Alonzo Church(阿隆佐·邱奇):30年代发明了lambda演算的数学家。
- John McCarthy(约翰·麦卡锡): 50年代基于lambda演算发明了LISP语言的大佬。
- Peter J Landin(彼得·兰丁):60年代提出了闭包的概念,包括语法糖,闭包等术语都是他创造的,对现代编程语言的贡献非常大。
- Joel Moses:1970年发表了关于闭包的论文的大佬,该论文作为实现Scheme的参考之一。
- Gerald Jay Sussman(杰拉德·杰伊·萨斯曼):1975年,与盖伊·史提尔二世共同开发了Scheme编程语言。
- Guy Lewis Steele Jr(盖伊·史提尔):1975年,与杰拉德·杰伊·萨斯曼共同开发了Scheme编程语言。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号