现实生活中的 CUDA 编程 Part1 对 GPU 的简单介绍
- Introduction (why care about the hardware)
- Yours new best friends (common tools)
- GPU deep dive (useful terms)

Source: http://furryball.aaa-studio.eu/images/multiplecores.jpg
Introduction
如果您也对编写所有这些内容背后的动机感兴趣,请查看第 0 部分。
与大多数编程问题不同,GPU coding 需要对 hardware 本身的基本 terms 和 concepts 有所了解。 This is necessary for two main reasons::
- If you’re coding I’m CUDA, you’re looking for speed。 虽然一般来说 GPU 会给您带来很快的速度,但您必须知道如何正确使用该设备。
- 您在 CUDA 中 programming 时看到的许多影响和限制是由底层 hardware 引起的,了解 hardware 也会提高您成功 program 的能力。
除此之外,如果你想在 CUDA 中 program ,你需要像在所有工艺中一样,了解你可用的 tools 。
Your new best friends
让我从头开始,向您介绍您将用于 GPU 编程的两个最强大的工具。
NVCC
NVCC(NVidia Cross Compiler)是任何 CUDA 程序的 compiler。Compiler 的行为与任何其他 C\C++ compiler 一样,包括 project 中包含的任何regular、non-CUDA 代码的 compilation 和 linking 过程。 NVCC 的特殊之处在于它可以 compile 所有 CUDA 函数和符号,这是 regular compiler 无法做到的。 除此之外,您只需将当前的 compiler 换成 NVCC,everything should work out as before.。
这也意味着您可以在您之前使用的任何 project building system 中使用 NVCC,例如 makefile。
NVProf
NVProf(NVidia Profiler)是您会发现的第二个最常用的工具。 虽然 profiling(测量程序的每个部分所花费的时间)很常见并且被广泛使用,但它对于 GPU programming 尤为重要。 原因很简单,正如我之前所说(and as I’ll probably say again),我们需要速度。 这驱使我们不断改进我们的时间,而 profiler 在这方面提供了巨大的帮助。 该工具的缺点是它仅分析在 GPU 上运行的代码(“device code”),不提供有关任何 CPU 代码(“host code”)的信息。
GPU Deep Dive
所以,现在我们必须面对GPU architecture 这堵巨大的墙。
Source: https://pascalprecht.github.io/posts/why-i-use-vim/
(完全公开,that learning curve is the Vim learning curve,但我认为它同样适用)。
虽然一开始很难理解,但一旦掌握了 GPU 的 architecture 和 capabilities ,剩下的事情就非常容易了。 需要理解三个主要 ideas:
- GPU Cores
- GPU Threads & thread blocks
- GPU Memory
一旦您对这三个 ideas 充满信心,您就可以开始 program 了!
Let’s tackle them one at a time.
GPU cores
首先,architecture 本身。
与 CPU 不同,GPU 专为 massive parallel computing 而设计。 因此,GPU 的设计有数百个 cores,可以处理数千个 threads,所有线程都 parallel 运行。
重要的是要记住,与 CPU 不同,在 CPU 上,parallel operations 的数量受 CPU 本身的 cores 数量(通常不超过 8 个)限制,GPU 没有这样的限制。 您可以,甚至鼓励,安排数以千计的 parallel threads,以保持 GPU cores 忙碌并最大限度地利用它们。
这个观点很重要,because as we will see,我们将安排比核心更多的进程。
GPU Threads
正如我所说,GPU 能够 parallel 运行数千个 threads,但为了 launch 那么多 threads,我们必须将它们分组为更小的 units,称为 thread blocks。 每个 thread block 大小固定,必须是 warp size(通常为 32)的倍数。 然后我们可以在所谓的 grid 中启动任意数量的 blocks。 每次你想在 GPU 上运行某些东西时,这两个 terms 都会出现,因为你必须同时指定 block size(通常是 static 和 hardcoded)和 grid size(which is usually determined at runtime so that there is one thread for each element of the computation.)
例如,当将两个 arrays 相加时(我们将在下一篇 post 中深入分析这个 example),我们为 array 中的每个 element 运行一个单独的 thread。
GPU Memory
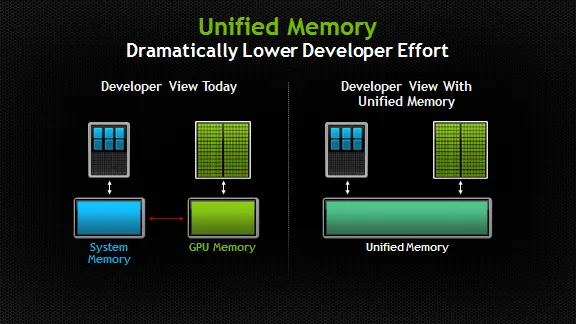
Source: https://devblogs.nvidia.com/unified-memory-in-cuda-6/
在我们开始实际 coding 之前必须了解的最后一个 element 是 GPU 可以访问的 memory。
一般来说,运行 GPU code 时会使用三种 types 的 memory。
- Regular CPU memory(“host memory”)。 这是在 standard code 中 allocating memory 时创建的 memory(即使用 new 关键字或 malloc 函数时)。This code is only accessible by the CPU and not the GPU。
- GPU-only memory(“device memory”)。 此 memory 存在于 GPU 上,可由 GPU 而不是 CPU 访问。
- Unified Memory。 该 memory 可供 CPU 和 GPU 访问。 实际上,unified memory 由 CUDA 自动管理,并根据需要在 CPU 和 GPU 之间传输。 使用 unified memory 简化了 programming 过程,将在下一篇 post 中讨论。
拥有两个 seperate memories 的直接含义是,program 中始终存在瓶颈,这是由必须由 CPU 完成的必要 memory copying 引起的(because, as we said, the GPU has no access to the memory on the host.)
Summary
那么我们今天学到了什么?
我们查看了与每个 CUDA project(NVCC、NVProf)一起使用的常用 tools。
我们还研究了有关 GPU 和 CUDA programming 的基本 terms ,并saw some of their implications on how we should write code for the GPU。
原文链接:Real Life CUDA Programming - Part 1 — A gentle introduction to the GPU

 浙公网安备 33010602011771号
浙公网安备 33010602011771号