
PlayWithHeyCoder
背景:爽哥买了个域名heycoder.com,用做自己的个人技术blog.
后加:特么服务器超级不稳定啊.艹,测试做好心里准备.
写的主要内容是关于一些自己的技术知识的积累和分享。(绝对非广告,绝对背景,我去,特么也没写几篇啊)
前段时间闲着没事儿,看到同事做的数据采集的代码.也想跟着学学.
这不就有了想法儿,就想先用他的网站先试试手,毕竟废水不留外人田嘛.
首先看了下网站的html.得亏代码结构不是很复杂,不然就搞不定呐.嘿嘿... 接下来看操作流程:
- 读取列表,提取链接和文本,并保存
- 根据链接和文本循环读取详细页抓取标题和内容病保存
- 文章按网页目录,网页文件名保存
我觉得,抓取网页内容最重要的就是根据需求获取指定数据(不知道怎么形容了),
当然我认为比较有效率的就是正则匹配查找(特么地,提到正则就头疼啊),
之前对正则只在会看、会用的level(意指简单的能看懂一点,别人写好现成的搜到会用).
接下来说代码,这边只是描述需要用到的正则,具体大家对应代码观看.
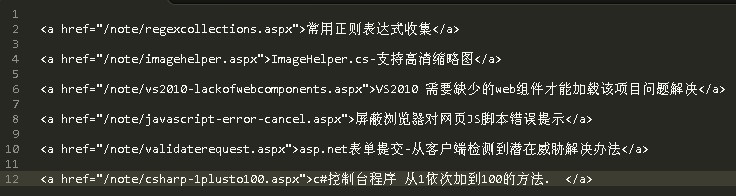
大家去看heycoder的列表页可以看到都是<h3>包含的.看下图.

虽然页面中还有其他的h3标签,但是他别的加了class, 嘎嘎. 省得费事了.
因此我用直接用了最简单的表达式 (?<=<h3>).*(?=</h3>).
正则意思:提取页面中h3包含的内容去除开始和结尾h3标签.
这样提取到的只是带有a标签的内容.还需要提取链接和文本.
因此就google到了这个表达式 @"(?is)<a[^>]*?href=(['""]?)(?<url>[^'""\s>]+)\1[^>]*>(?<text>(?:(?!</?a\b).)*)</a>"
提取到url和text之后,保存到集合中,循环读取详情页内容.
详情页的内容都是<div class="cont_text">包含的.
同样表达式走起 @"(?<=<div class=""cont_text"">)[\s\S]*(?=</div>[\s\S]*<p class=""align-right"">)"
正则意思:提取div包含的内容并去除开始和结尾div标签,并且结束的div必须是在<p class="align-right">前面的.
数据都取到后就是保存了.保存代码就不说了.用的最简单的StreamWriter去操作的.
在此过程中,我google的时候搜到的一些链接,供大家以后使用.
- ab{,2}c 无法匹配ac、abc、abbc、aabbcc,应为ab{0,2}c

- 字符类段落列出的操作中使用的一些字符类,其中0,1,3,5列应去掉^(开始)和$(结束),否则无法匹配

- ^(\d{5}(-\d{4})?$,这个正则少了一个 ) , 应为 ^(\d{5})(-\d{4})?$

此文章会持续更新...
欢迎猿儿们fork.
欢迎指出错误,交流学习.

