Google布隆过滤器与Redis布隆过滤器详解
一、什么是布隆过滤器?
布隆过滤器可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。
对于布隆过滤器而言,它的本质是一个位数组:位数组就是数组的每个元素都只占用1bit ,并且每个元素只能是0或者1
布隆过滤器除了一个位数组,还有 K 个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用K个哈希函数对元素值进行K次计算,得到K个哈希值
- 根据得到的哈希值,在位数组中把对应下标的值置为1
下图表示有三个hash函数,比如一个集合中有x、y、z三个元素,分别用三个hash函数映射到二进制序列的某些位上,假设我们判断w是否在集合中,同样用三个hash函数来映射,结果发现取得的结果不全为1,则表示w不在集合里面。

数组的容量即使再大,也是有限的。那么随着元素的增加,插入的元素就会越多,位数组中被置为1的位置因此也越多,这就会造成一种情况:当一个不在布隆过滤器中的元素,经过同样规则的哈希计算之后,得到的值在位数组中查询,有可能这些位置因为之前其它元素的操作先被置为1了
所以,有可能一个不存在布隆过滤器中的会被误判成在布隆过滤器中。这就是布隆过滤器的一个缺陷。但是,如果布隆过滤器判断某个元素不在布隆过滤器中,那么这个值就一定不在布隆过滤器中。总结就是:
- 布隆过滤器说某个元素在,可能会被误判
- 布隆过滤器说某个元素不在,那么一定不在
二、Google布隆过滤器基本使用
- 引入依赖
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>21.0</version> </dependency>
- BloomFilterService
@Service
public class BloomFilterService {@Autowired private UserMapper userMapper; private BloomFilter<Integer> bf; /** * 创建布隆过滤器 * * @PostConstruct:程序启动时候加载此方法 */ @PostConstruct public void initBloomFilter() { List<User> userList = userMapper.selectAllUser(); if (CollectionUtils.isEmpty(userList)) { return; } //创建布隆过滤器(默认3%误差) bf = BloomFilter.create(Funnels.integerFunnel(), userList.size()); for (User user : userList) { bf.put(user.getId()); } } /** * 判断id可能存在于布隆过滤器里面 * * @param id * @return */ public boolean userIdExists(int id) { return bf.mightContain(id); }}
- BloomFilterController
@RestController
public class BloomFilterController {@Autowired private BloomFilterService bloomFilterService; @RequestMapping("/bloom/idExists") public boolean ifExists(int id) { return bloomFilterService.userIdExists(id); }}
三、Google布隆过滤器与Redis布隆过滤器对比
- Google布隆过滤器的缺点
基于JVM内存的一种布隆过滤器
重启即失效
本地内存无法用在分布式场景
不支持大数据量存储
- Redis布隆过滤器
可扩展性Bloom过滤器:一旦Bloom过滤器达到容量,就会在其上创建一个新的过滤器
不存在重启即失效或者定时任务维护的成本:基于Google实现的布隆过滤器需要启动之后初始化布隆过滤器
缺点:需要网络IO,性能比Google布隆过滤器低
四、Redis布隆过滤器安装和基本使用
1)使用Docker安装
[root@localhost ~]# docker run -d -p 6379:6379 --name bloomfilter redislabs/rebloom
2)基本使用
[root@localhost ~]# docker exec -it bloomfilter /bin/bash
root@7a06a3528556:/data# redis-cli -p 6379
127.0.0.1:6379>
Redis布隆过滤器命令:
bf.add:添加元素到布隆过滤器中,只能添加一个元素,如果想要添加多个使用bf.madd命令
bf.exists:判断某个元素是否在过滤器中,只能判断一个元素,如果想要判断多个使用bf.mexists
127.0.0.1:6379> bf.add urls www.taobao.com
(integer) 1
127.0.0.1:6379> bf.exists urls www.taobao.com
(integer) 1
127.0.0.1:6379> bf.madd urls www.baidu.com www.tianmao.com
- (integer) 1
- (integer) 1
127.0.0.1:6379> bf.mexists urls www.baidu.com www.tianmao.com- (integer) 1
- (integer) 1
上面使用的布隆过滤器只是默认参数的布隆过滤器,它在我们第一次add的时候自动创建。Redis还提供了自定义参数的布隆过滤器,需要在add之前使用bf.reserve指令显式创建。如果对应的key已经存在,bf.reserve会报错(error) ERR item exists bf.reserve 过滤器名 error_rate initial_size
布隆过滤器存在误判的情况,在Redis中有两个值决定布隆过滤器的准确率:
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降
127.0.0.1:6379> bf.reserve user 0.01 100
OK
五、会员转盘抽奖
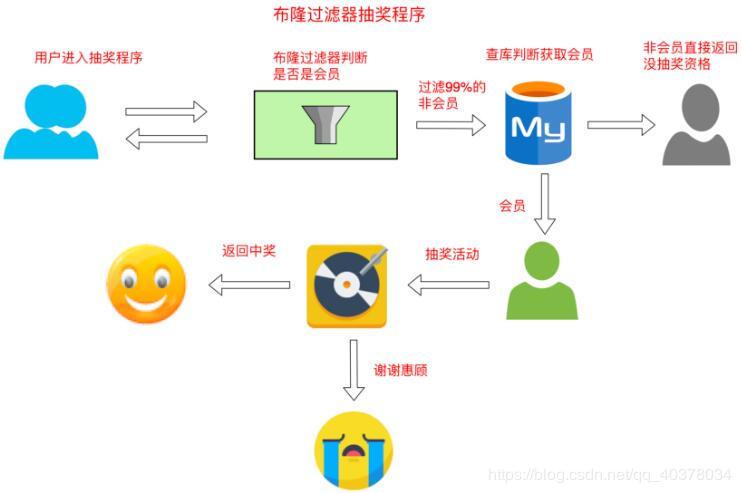
实现思路:在判断用户是否是会员的时候,第一步先通过布隆过滤器过滤掉99%的非会员(误码率为1%的情况下),由于布隆过滤器有可能将一个不存在布隆过滤器中的误判成在布隆过滤器中,也就是有可能会把非会员判断为会员,所以第二步查询数据库中用户对应的数据库信息判断该用户是否是会员
声明:本号所有文章除特殊注明,都为原创,公众号读者拥有优先阅读权,未经作者本人允许不得转载,否则追究侵权责任。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号