
我说Java基础重要,你不信?来试试这几个问题
什么是字节码?Java采用字节码的好处是什么?
那我在问问SparkSQL的字节码生成是怎么做的不过分吧?
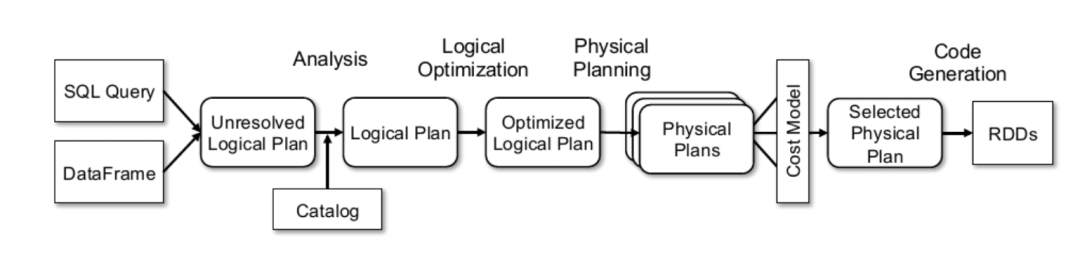
代码生成技术广泛应用于现代的数据库系统中。代码生成是将用户输入的表达式、查询、存储过程等现场编译成二进制代码再执行,相比解释执行的方式,运行效率要高很多。尤其是对于计算密集型查询、或频繁重复使用的计算过程,运用代码生成技术能达到数十倍的性能提升。
Spark SQL在其catalyst模块的expressions中增加了codegen模块,对于SQL语句中的计算表达式,比如select num + num from t这种的sql,就可以使用动态字节码生成技术来优化其性能。
spark1.x就已经有代码生成技术,2.0进一步优化。
spark1.4,使用代码生成技术加速表达式计算。表达式代码生成(expression codegen)表达式代码生成主要是想解决大量虚函数调用(Virtual Function Calls),泛化的代价等。需要注意的是,上面通过表达式生成完整的类代码只有在将 spark.sql.codegen.wholeStage 设置为 false 才会进行的,否则只会生成一部分代码,并且和其他代码组成 Whole-stage Code。
spark2.0支持同一个stage的多个算子组合编译成一段二进制。主要就是将一串的算子,转换成一段代码(Spark sql转换成java代码),从而提高性能。一串的算子操作,可以转换成一个java方法,这样一来性能会有一定的提升。通过引入全阶段代码生成,大大减少了虚函数的调用,减少了 CPU 的调用,使得 SQL 的执行速度有很大提升。
代码编译:通过janino实现的。
Janino 是一个超级小但又超级快的 Java™ 编译器. 它不仅能像 javac 工具那样将一组源文件编译成字节码文件,还可以对一些 Java 表达式,代码块,类中的文本(class body)或者内存中源文件进行编译,并把编译后的字节码直接加载到同一个 JVM 中运行。Janino 不是一个开发工具, 而是作为运行时的嵌入式编译器,比如作为表达式求值的翻译器或类似于 JSP 的服务端页面引擎。通过引入了 Janino 来编译生成的代码,结果显示 SQL 表达式的编译时间减少到 5ms。在 Spark 中使用了 ClassBodyEvaluator 来编译生成之后的代码,参见 org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator。
Java的IO熟悉吧?
那我问个HDFS上传和MapReduce读取文件有什么区别不过分吧?
MapReduce的InputFormat常见子类包括:
- TextInputFormat (普通文本文件,MR框架默认的读取实现类型)
- KeyValueTextInputFormat(读取一行文本数据按照指定分隔符,把数据封装为kv类型)
- NLineInputFormat(读取数据按照行数进行划分分片)
- CombineTextInputFormat(合并小文件,避免启动过多MapTask任务)
HDFS读取文件:
public static void copyBytes(InputStream in, OutputStream out, int buffSize) throws IOException {
PrintStream ps = out instanceof PrintStream ? (PrintStream)out : null;
byte[] buf = new byte[buffSize];
for(int bytesRead = in.read(buf); bytesRead >= 0; bytesRead = in.read(buf)) {
out.write(buf, 0, bytesRead);
if (ps != null && ps.checkError()) {
throw new IOException("Unable to write to output stream.");
}
}
}
Java中的Serializable熟悉吧?
那我问问你知道的任何一个框架的序列化是怎么做的?为什么这些框架不用Java原生的序列化不过分吧?
Flink为什么要自己实现序列化框架?
目前,绝大多数的大数据计算框架都是基于JVM实现的,为了快速地计算数据,需要将数据加载到内存中进行处理。当大量数据需要加载到内存中时,如果使用Java序列化方式来存储对象,占用的空间会较大降低存储传输效率。
例如:一个只包含布尔类型的对象需要占用16个字节的内存:对象头要占8个字节、boolean属性占用1个字节、对齐填充还要占用7个字节。
Java序列化方式存储对象存储密度是很低的。也是基于此,Flink框架实现了自己的内存管理系统,在Flink自定义内存池分配和回收内存,然后将自己实现的序列化对象存储在内存块中。
Java生态系统中有挺多的序列化框架,例如:Kryo、Avro、ProtoBuf等。Flink自己实现了一套序列化系统可以让我们编写程序的时候,尽快地发现问题,更加节省内存空间,并直接进行二进制数据的处理。
例如:POJO类型对应的是PojoTypeInfo、基础数据类型数组对应的是BasicArrayTypeInfo、Map类型对应的是MapTypeInfo、值类型对应的是ValueTypeInfo。
除了对类型地描述之外,TypeInformation还提供了序列化的支撑。在TypeInformation中有一个方法:createSerializer方法,它用来创建序列化器,序列化器中定义了一系列的方法。其中,通过serialize和deserialize方法,可以将指定类型进行序列化。并且,Flink的这些序列化器会以稠密的方式来将对象写入到内存中。
Spark的目标是在便利与性能中取得平衡,所以提供2种序列化的选择。
- Java serialization
在默认情况下,Spark会使用Java的ObjectOutputStream框架对对象进行序列化,并且可以与任何实现java.io.Serializable的类一起工作。您还可以通过扩展java.io.Externalizable来更紧密地控制序列化的性能。Java序列化是灵活的,但通常相当慢,并且会导致许多类的大型序列化格式。
- Kryo serialization
Spark还可以使用Kryo库(版本2)来更快地序列化对象。Kryo比Java串行化(通常多达10倍)要快得多,也更紧凑,但是不支持所有可串行化类型,并且要求您提前注册您将在程序中使用的类,以获得最佳性能
Kryo serialization 性能和序列化大小都比默认提供的 Java serialization 要好,但是使用Kryo需要将自定义的类先注册进去,使用起来比Java serialization麻烦。自从Spark 2.0.0以来,我们在使用简单类型、简单类型数组或字符串类型的简单类型来调整RDDs时,在内部使用Kryo序列化器。
Java中的反射了解吧?
那我问问Spark SQL将RDD转换为DataFrame如何实现的不过分吧?
Spark SQL支持将现有RDDS转换为DataFrame的两种不同方法,其实也就是隐式推断或者显式指定DataFrame对象的Schema。
- 1.使用反射机制( Reflection )推理出schema (结构信息)
第一种将RDDS转化为DataFrame的方法是使用Spark SQL内部反射机制来自动推断包含特定类型对象的RDD的schema
(RDD的结构信息)进行隐式转化。采用这种方式转化为DataFrame对象,往往是因为被转化的RDD[T]所包含的T对象本身就是具有典型-一维表严格的字段结构的对象,因此Spark SQL很容易就可以自动推断出合理的Schema这种基于反射机制隐式地创建DataFrame的方法往往仅需更简洁的代码即可完成转化,并且运行效果良好。
Spark SQL的Scala接口支持自动将包含样例类( case class对象的RDD转换为DataFrame对象。在样例类的声明中 已预先定义了表的结构信息,内部通过反射机制即可读取样例类的参数的名称、类型,转化为DataFrame对象的Schema.样例类不仅可以包含Int、Double、String这样的简单数据类型,也可以嵌套或包含复杂类型,例如Seq或Arrays。
- 2.由开发者指定Schema
RDD转化DataFrame的第二种方法是通过编程接口,允许先构建个schema,然后将其应用到现有的RDD(Row),较前一种方法由样例类或基本数据类型 (Int、String) 对象组成的RDD加过toDF ()直接隐式转化为DataFrame不同,不仅需要根据需求、以及数据结构构建Schema,而且需要将RDD[T]转化为Row对象组成的RDD (RDD[Row]),这种方法虽然代码量一些,但也提供了更高的自由度,更加灵活。
LinkedHashMap知道吧?
那我问问Spark做内存管理有一种叫"存储内存",用了什么数据结构?淘汰策略是什么不过分吧?
由于同一个 Executor 的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对 LinkedHashMap 中的旧 Block 进行淘汰(Eviction),而被淘汰的 Block 如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该 Block
遍历 LinkedHashMap 中 Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新 Block 所需的空间。其中LRU 是 LinkedHashMap 的特性。
快速失败(fail-fast)和安全失败(fail-safe)听过吧?
Flink哪里的设计用到了fail-fast理念?
In case of a program failure (due to machine-, network-, or software failure), Flink stops the distributed streaming dataflow. The system then restarts the operators and resets them to the latest successful checkpoint. The input streams are reset to the point of the state snapshot. Any records that are processed as part of the restarted parallel dataflow are guaranteed to not have been part of the previously checkpointed state.
你很懂ConcurrentHashMap?
那我问问Spark/Flink中哪里用到了ConcurrentHashMap?
友情提示:Spark中的所有Settings,Flink中的ParameterUtil,太多了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号