Flink重点难点:Flink任务综合调优(Checkpoint/反压/内存)
在阅读本文之前,你应该阅读过的系列:
- 一网打尽Flink中的时间、窗口和流Join
- Flink重点原理与机制 | 网络流控及反压机制
- Flink重点难点:维表关联理论和Join实战
- Flink重点难点:内存模型与内存结构
- Flink重点难点:Flink Table&SQL必知必会(一)
- Flink重点难点:Flink Table&SQL必知必会(二)
CheckPoint调优
我们在Flink重点难点:状态(Checkpoint和Savepoint)容错与两阶段提交一文中对Flink的Checkpoint做过详细的介绍。
Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,Checkpoints可以将同一时间点作业/算子的状态数据全局统一快照处理,包括前面提到的算子状态和键值分区状态。当发生了故障后,Flink会将所有任务的状态恢复至最后一次Checkpoint中的状态,并从那里重新开始执行。
对于Flink Checkpoint的优化至关重要。我们常见的优化 Checkpoint的手段如下:
一、设置最小时间间隔
当Flink应用开启Checkpoint功能,并配置Checkpoint时间间隔,应用中就会根据指定的时间间隔周期性地对应用进行Checkpoint操作。默认情况下Checkpoint操作都是同步进行,也就是说,当前面触发的Checkpoint动作没有完全结束时,之后的Checkpoint操作将不会被触发。在这种情况下,如果Checkpoint过程持续的时间超过了配置的时间间隔,就会出现排队的情况。如果有非常多的Checkpoint操作在排队,就会占用额外的系统资源用于Checkpoint,此时用于任务计算的资源将会减少,进而影响到整个应用的性能和正常执行。
在这种情况下,如果大状态数据确实需要很长的时间来进行Checkpoint,那么只能对Checkpoint的时间间隔进行优化,可以通过Checkpoint之间的最小间隔参数进行配置,让Checkpoint之间根据Checkpoint执行速度进行调整,前面的Checkpoint没有完全结束,后面的Checkpoint操作也不会触发。
streamExecutionEnvironment.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds)
通过最小时间间隔参数配置,可以降低Checkpoint对系统的性能影响,但需要注意的事,对于非常大的状态数据,最小时间间隔只能减轻Checkpoint之间的堆积情况。如果不能有效快速地完成Checkpoint,将会导致系统Checkpoint频次越来越低,当系统出现问题时,没有及时对状态数据有效地持久化,可能会导致系统丢失数据。因此,对于非常大的状态数据而言,应该对Checkpoint过程进行优化和调整,例如采用增量Checkpoint的方法等。
用户也可以通过配置CheckpointConfig中setMaxConcurrentCheckpoints()方法设定并行执行的checkpoint数量,这种方法也能有效降低checkpoint堆积的问题,但会提高资源占用。同时,如果开始了并行checkpoint操作,当用户以手动方式触发savepoint的时候,checkpoint操作也将继续执行,这将影响到savepoint过程中对状态数据的持久化。
二、预估状态容量
除了对已经运行的任务进行checkpoint优化,对整个任务需要的状态数据量进行预估也非常重要,这样才能选择合适的checkpoint策略。对任务状态数据存储的规划依赖于如下基本规则:
1.正常情况下应该尽可能留有足够的资源来应对频繁的反压。
2.需要尽可能提供给额外的资源,以便在任务出现异常中断的情况下处理积压的数据。这些资源的预估都取决于任务停止过程中数据的积压量,以及对任务恢复时间的要求。
3.系统中出现临时性的反压没有太大的问题,但是如果系统中频繁出现临时性的反压,例如下游外部系统临时性变慢导致数据输出速率下降,这种情况就需要考虑给予算子一定的资源。
4.部分算子导致下游的算子的负载非常高,下游的算子完全是取决于上游算子的输出,因此对类似于窗口算子的估计也将会影响到整个任务的执行,应该尽可能给这些算子留有足够的资源以应对上游算子产生的影响。
三、异步Snapshot
默认情况下,应用中的checkpoint操作都是同步执行的,在条件允许的情况下应该尽可能地使用异步的snapshot,这样讲大幅度提升checkpoint的性能,尤其是在非常复杂的流式应用中,如多数据源关联、co-functions操作或windows操作等,都会有较好的性能改善。
Flink提供了异步快照(Asynchronous Snapshot)的机制。当实际执行快照时,Flink可以立即向下广播Checkpoint Barrier,表示自己已经执行完自己部分的快照。同时,Flink启动一个后台线程,它创建本地状态的一份拷贝,这个线程用来将本地状态的拷贝同步到State Backend上,一旦数据同步完成,再给Checkpoint Coordinator发送确认信息。拷贝一份数据肯定占用更多内存,这时可以利用写入时复制(Copy-on-Write)的优化策略。Copy-on-Write指:如果这份内存数据没有任何修改,那没必要生成一份拷贝,只需要有一个指向这份数据的指针,通过指针将本地数据同步到State Backend上;如果这份内存数据有一些更新,那再去申请额外的内存空间并维护两份数据,一份是快照时的数据,一份是更新后的数据。
在使用异步快照需要确认应用遵循以下两点要求:
1.首先必须是Flink托管状态,即使用Flink内部提供的托管状态所对应的数据结构,例如常用的有ValueState、ListState、ReducingState等类型状态。
2.StateBackend必须支持异步快照,在Flink1.2的版本之前,只有RocksDB完整地支持异步的Snapshot操作,从Flink1.3版本以后可以在heap-based StateBackend中支持异步快照功能。
四、压缩状态数据
Flink中提供了针对checkpoint和savepoint的数据进行压缩的方法,目前Flink仅支持通过用snappy压缩算法对状态数据进行压缩,在未来的版本中Flink将支持其他压缩算法。在压缩过程中,Flink的压缩算法支持key-group层面压缩,也就是不同的key-group分别被压缩成不同的部分,因此解压缩过程可以并发执行,这对大规模数据的压缩和解压缩带来非常高的性能提升和较强的可扩展性。Flink中使用的压缩算法在ExecutionConfig中进行指定,通过将setUseSnapshotCompression方法中的值设定为true即可。
五、观察checkpoint延迟时间
checkpoint延迟启动时间并不会直接暴露在客户端中,而是需要通过以下公式计算得出。如果改时间过长,则表明算子在进行barrier对齐,等待上游的算子将数据写入到当前算子中,说明系统正处于一个反压状态下。checkpoint延迟时间可以通过整个端到端的计算时间减去异步持续的时间和同步持续的时间得出。
六、Checkpoint相关配置
默认情况下,Checkpoint机制是关闭的,需要调用env.enableCheckpointing(n)来开启,每隔n毫秒进行一次Checkpoint。Checkpoint是一种负载较重的任务,如果状态比较大,同时n值又比较小,那可能一次Checkpoint还没完成,下次Checkpoint已经被触发,占用太多本该用于正常数据处理的资源。增大n值意味着一个作业的Checkpoint次数更少,整个作业用于进行Checkpoint的资源更小,可以将更多的资源用于正常的流数据处理。同时,更大的n值意味着重启后,整个作业需要从更长的Offset开始重新处理数据。
此外,还有一些其他参数需要配置,这些参数统一封装在了CheckpointConfig里:
val cpConfig: CheckpointConfig = env.getCheckpointConfig
默认的Checkpoint配置是支持Exactly-Once投递的,这样能保证在重启恢复时,所有算子的状态对任一条数据只处理一次。用上文的Checkpoint原理来说,使用Exactly-Once就是进行了Checkpoint Barrier对齐,因此会有一定的延迟。如果作业延迟小,那么应该使用At-Least-Once投递,不进行对齐,但某些数据会被处理多次。
// 使用At-Least-Once
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
如果一次Checkpoint超过一定时间仍未完成,直接将其终止,以免其占用太多资源:
// 超时时间1小时
env.getCheckpointConfig.setCheckpointTimeout(3600*1000)
如果两次Checkpoint之间的间歇时间太短,那么正常的作业可能获取的资源较少,更多的资源被用在了Checkpoint上。对这个参数进行合理配置能保证数据流的正常处理。比如,设置这个参数为60秒,那么前一次Checkpoint结束后60秒内不会启动新的Checkpoint。这种模式只在整个作业最多允许1个Checkpoint时适用。
// 两次Checkpoint的间隔为60秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(60*1000)
默认情况下一个作业只允许1个Checkpoint执行,如果某个Checkpoint正在进行,另外一个Checkpoint被启动,新的Checkpoint需要挂起等待。
// 最多同时进行3个Checkpoint
env.getCheckpointConfig.setMaxConcurrentCheckpoints(3)
如果这个参数大于1,将与前面提到的最短间隔相冲突。
Checkpoint的初衷是用来进行故障恢复,如果作业是因为异常而失败,Flink会保存远程存储上的数据;如果开发者自己取消了作业,远程存储上的数据都会被删除。如果开发者希望通过Checkpoint数据进行调试,自己取消了作业,同时希望将远程数据保存下来,需要设置为:
// 作业取消后仍然保存Checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
RETAIN_ON_CANCELLATION模式下,用户需要自己手动删除远程存储上的Checkpoint数据。
默认情况下,如果Checkpoint过程失败,会导致整个应用重启,我们可以关闭这个功能,这样Checkpoint失败不影响作业的运行。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
反压调优
我们在 Flink重点原理与机制 | 网络流控及反压机制一文中介绍过Flink中的反压机制和现象。
Flink1.5之前是基于TCP流控+bounded buffer实现反压。在Flink 1.5之后实现了自己托管的credit-based流控机制,在应用层模拟TCP的流控机制。
反压的定位
当你的任务出现反压时,如果你的上游是类似 Kafka 的消息系统,很明显的表现就是消费速度变慢,Kafka 消息出现堆积。
如果你的业务对数据延迟要求并不高,那么反压其实并没有很大的影响。但是对于规模很大的集群中的大作业,反压会造成严重的“并发症”。首先任务状态会变得很大,因为数据大规模堆积在系统中,这些暂时不被处理的数据同样会被放到“状态”中。另外,Flink 会因为数据堆积和处理速度变慢导致 checkpoint 超时,而 checkpoint 是 Flink 保证数据一致性的关键所在,最终会导致数据的不一致发生。
那么我们应该如何发现任务是否出现反压了呢?
Flink Web UI
Flink 的后台页面是我们发现反压问题的第一选择。Flink 的后台页面可以直观、清晰地看到当前作业的运行状态。
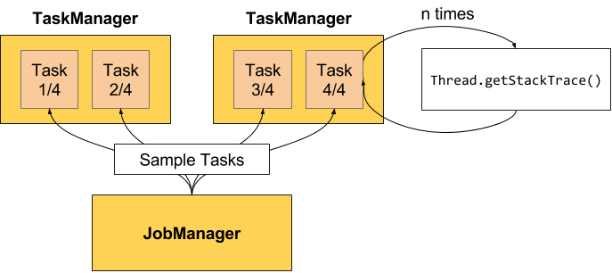
如上图所示,是 Flink 官网给出的计算反压状态的案例。需要注意的是,只有用户在访问点击某一个作业时,才会触发反压状态的计算。在默认的设置下,Flink 的 TaskManager 会每隔 50 ms 触发一次反压状态监测,共监测 100 次,并将计算结果反馈给 JobManager,最后由 JobManager 进行计算反压的比例,然后进行展示。
这个比例展示逻辑如下:
- OK: 0 <= Ratio <= 0.10,正常;
- LOW: 0.10 < Ratio <= 0.5,一般;
- HIGH: 0.5 < Ratio <= 1,严重。
官网同样给出了不同反压状态下,Flink Web UI 中任务运行的状态,如下图所示:
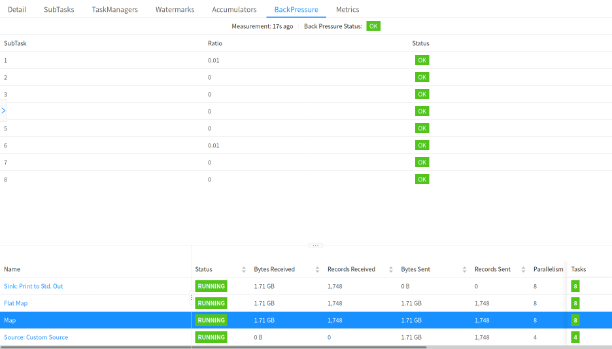
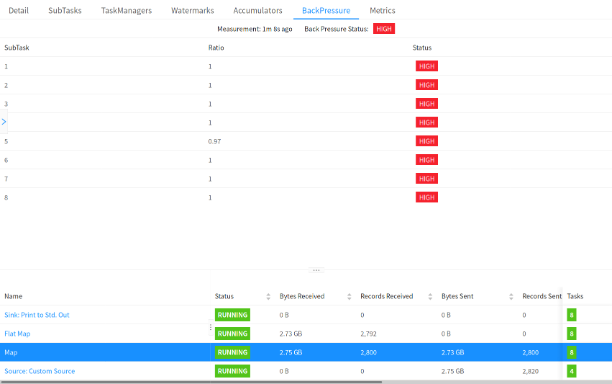
Flink Metrics
如果你想对 Flink 做更为详细的监控的话,Flink 本身提供了大量的 REST API 来获取任务的各种状态。
Flink 提供的所有系统监控指标你都点击这里找到: https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/metrics/
随着版本的持续变更,截止 1.14.0 版本,Flink 提供的监控指标中与反压最为密切的如下表所示:
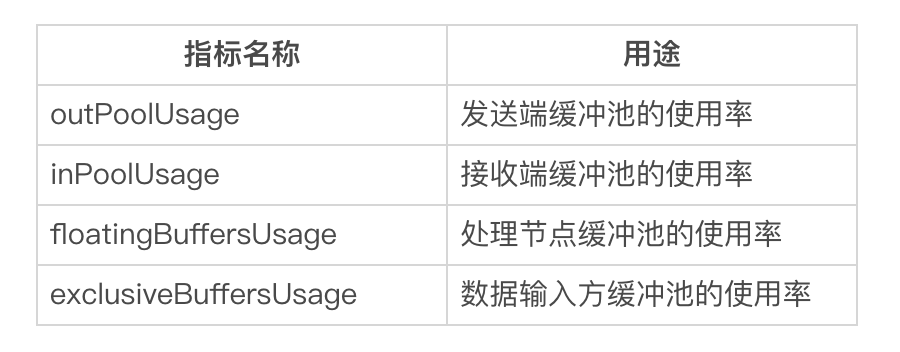
我们逐个介绍一下这四个指标。
- outPoolUsage
这个指标代表的是当前 Task 的数据发送速率,当一个 Task 的 outPoolUsage 很高,则代表着数据发送速度很快。但是当一个 Task 的 outPoolUsage 很低,那么就需要特别注意,有可能是下游的处理速度很低导致的,也有可能当前节点就是反压节点,导致数据处理速度很慢。
- inPoolUsage
inPoolUsage 表示当前 Task 的数据接收速率,通常会和 outPoolUsage 配合使用;如果一个节点的 inPoolUsage 很高而 outPoolUsage 很低,则这个节点很有可能就是反压节点。
- floatingBuffersUsage 和 exclusiveBuffersUsage
floatingBuffersUsage 表示处理节点缓冲池的使用率;exclusiveBuffersUsage 表示数据输入通道缓冲池的使用率。
反压问题处理
我们已经知道反压产生的原因和监控的方法,当线上任务出现反压时,需要如何处理呢?
主要通过以下几个方面进行定位和处理:
- 数据倾斜
- GC
- 代码本身
数据倾斜
数据倾斜问题是我们生产环境中出现频率最多的影响任务运行的因素,可以在 Flink 的后台管理页面看到每个 Task 处理数据的大小。当数据倾斜出现时,通常是简单地使用类似 KeyBy 等分组聚合函数导致的,需要用户将热点 Key 进行预处理,降低或者消除热点 Key 的影响。
GC
垃圾回收问题也是造成反压的因素之一。不合理的设置 TaskManager 的垃圾回收参数会导致严重的 GC 问题,我们可以通过 -XX:+PrintGCDetails 参数查看 GC 的日志。
代码本身
开发者错误地使用 Flink 算子,没有深入了解算子的实现机制导致性能问题。我们可以通过查看运行机器节点的 CPU 和内存情况定位问题。
内存调优
我们在 Flink重点难点:内存模型与内存结构这篇文章中详细讲解了Flink的内存模型。
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)。
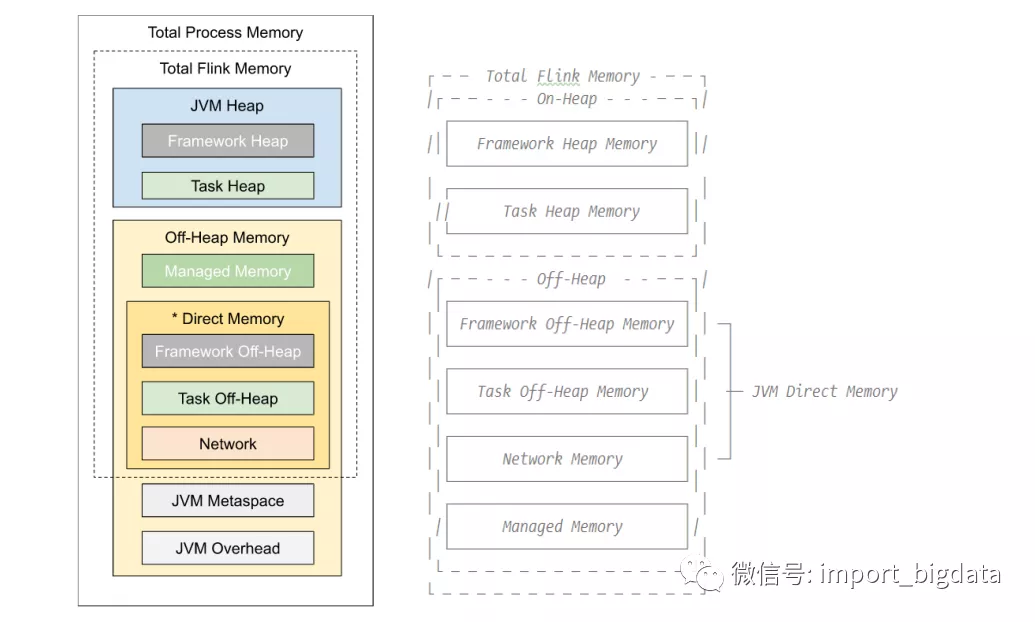
配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:

Flink有三种部署方式(这里不谈Flink on k8s),一种为本地模式,一种为standalone模式,还有一种为yarn或者mesos模式,这三种模式中,用户必须要选择一种进行配置(本地模式除外),否则flink将无法启动,这意味着,用户需要从以下的无默认值的配置参数中选择一个给出明确的配置。
不建议同时设置进程总内存和 Flink 总内存。这可能会造成内存配置冲突,从而导致部署失败。额外配置其他内存部分时,同样需要注意可能产生的配置冲突
配置TaskManager内存
Flink 的 TaskManager 负责执行用户代码。根据实际需求为 TaskManager 配置内存将有助于减少 Flink 的资源占用,增强作业运行的稳定性。
本篇内存配置文档仅针对 TaskManager与JobManager相比,TaskManager 具有相似但更加复杂的内存模型。
配置总内存
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。其中,Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)、托管内存(Managed Memory)以及其他直接内存(Direct Memory)或本地内存(Native Memory)。
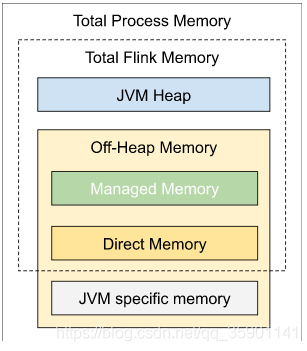
如果你是在本地运行 Flink(例如在 IDE 中)而非创建一个集群,那么本文介绍的配置并非所有都是适用的,详情请参考本地执行
其他情况下,配置 Flink 内存最简单的方法就是配置总内存。此外,Flink 也支持更细粒度的内存配置,比如说配置堆内存和托管内存
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。
配置堆内存和托管内存
如配置总内存中所述,另一种配置 Flink 内存的方式是同时设置任务堆内存和托管内存, 通过这种方式,用户可以更好地掌控用于 Flink 任务的 JVM 堆内存及 Flink 的托管内存的大小。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。关于各内存部分的更多细节,请参考后续的内存详解。
注意:如果已经明确设置了任务堆内存和托管内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
任务(算子)堆内存
如果希望确保指定大小的 JVM 堆内存给用户代码使用,可以明确指定任务堆内存(taskmanager.memory.task.heap.size )指定的内存将被包含在总的 JVM 堆空间中,专门用于 Flink 算子及用户代码的执行。
托管内存
托管内存是由 Flink 负责分配和管理的本地(堆外)内存。以下场景需要使用托管内存:
- 流处理作业中用于 RocksDB State Backend。
- 批处理作业中用于排序、哈希表及缓存中间结果。
- 流处理和批处理作业中用于「在Python进程中执行用户自定义函数」。
可以通过以下两种范式指定托管内存的大小:
- 通过 taskmanager.memory.managed.size 明确指定其大小。
- 通过 taskmanager.memory.managed.fraction 指定在Flink 总内存中的占比。
当同时指定二者时,会优先采用指定的大小(Size)。若二者均未指定,会根据默认占比进行计算。
消费者权重
对于包含不同种类的托管内存消费者的作业,可以进一步控制托管内存如何在消费者之间分配。通过taskmanager.memory.managed.consumer-weights可以为每一种类型的消费者指定一个权重,Flink 会按照权重的比例进行内存分配。目前支持的消费者类型包括:
- DATAPROC:用于流处理中的 RocksDB State Backend 和批处理中的内置算法。
- PYTHON:用户 Python 进程。
例如,一个流处理作业同时使用到了 RocksDB State Backend 和 Python UDF,消费者权重设置为 DATAPROC:70,PYTHON:30,那么 Flink 会将 70% 的托管内存用于 RocksDB State Backend,30% 留给 Python 进程。
只有作业中包含某种类型的消费者时,Flink 才会为该类型分配托管内存。例如,一个流处理作业使用 Heap State Backend 和 Python UDF,消费者权重设置为 DATAPROC:70,PYTHON:30,那么 Flink 会将全部托管内存用于 Python 进程,因为 Heap State Backend 不使用托管内存。
提示对于未出现在消费者权重中的类型,Flink将不会为其分配托管内存。如果缺失的类型是作业运行所必须的,则会引发内存分配失败。默认情况下,消费者权重中包含了所有可能的消费者类型。上述问题仅可能出现在用户显式地配置了消费者权重的情况下。
配置堆外内存(直接内存或本地内存)
你也可以调整框架堆外内存(Framework Off-heap Memory)。这是一个进阶配置,建议仅在确定 Flink 框架需要更多的内存时调整该配置。
Flink 将框架堆外内存和任务堆外内存都计算在 JVM 的直接内存限制中。
内存详解
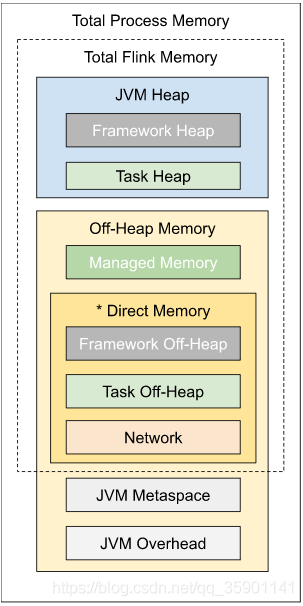
TaskManager内存也包括堆内存和堆外内存。下表中列出了 Flink TaskManager内存模型的所有组成部分,以及影响其大小的相关配置参数。
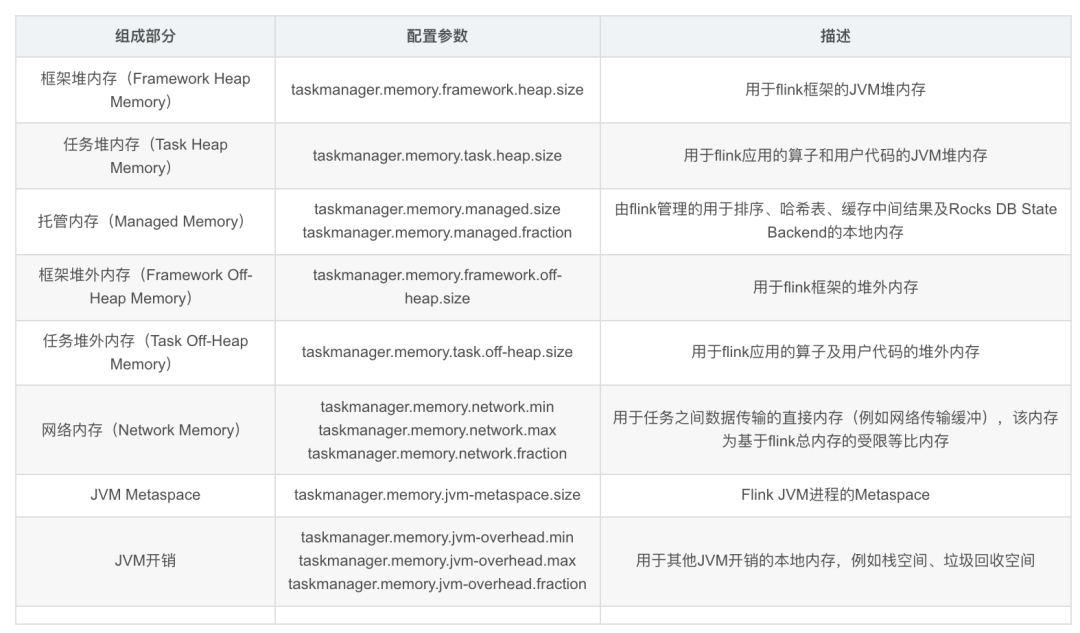
我们可以看到,有些内存部分的大小可以直接通过一个配置参数进行设置,有些则需要根据多个参数进行调整。
框架内存
通常情况下,不建议对框架堆内存和框架堆外内存进行调整。除非你非常肯定 Flink 的内部数据结构及操作需要更多的内存。这可能与具体的部署环境及作业结构有关,例如非常高的并发度。此外,Flink 的部分依赖(例如 Hadoop)在某些特定的情况下也可能会需要更多的直接内存或本地内存。
提示:不管是堆内存还是堆外内存,Flink 中的框架内存和任务内存之间目前是没有隔离的。对框架和任务内存的区分,主要是为了在后续版本中做进一步优化。
配置JobManager内存
配置 JobManager 内存最简单的方法就是进程的配置总内存,本地模式下不需要为 JobManager 进行内存配置,配置参数将不会生效。
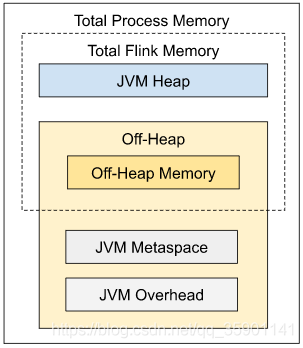
如上图所示,下表中列出了 Flink JobManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。

配置JVM堆内存
如配置总内存中所述,配置 JobManager 内存的方式是明确指定 JVM 堆内存的大小(jobmanager.memory.heap.size)。通过这种方式,用户可以更好地掌控用于以下用途的 JVM 堆内存大小。
- Flink 框架
- 在作业提交时(例如一些特殊的批处理 Source)及 Checkpoint 完成的回调函数中执行的用户代码
Flink 需要多少 JVM 堆内存,很大程度上取决于运行的作业数量、作业的结构及上述用户代码的需求。
提示:如果已经明确设置了 JVM 堆内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
在启动 JobManager 进程时,Flink 启动脚本及客户端通过设置 JVM 参数 -Xms 和 -Xmx 来管理 JVM 堆空间的大小。
配置堆外内存
堆外内存包括 JVM 直接内存 和 本地内存。可以通过配置参数 jobmanager.memory.enable-jvm-direct-memory-limit 设置是否启用 JVM 直接内存限制。如果该配置项设置为 true,Flink 会根据配置的堆外内存大小设置 JVM 参数 -XX:MaxDirectMemorySize。
可以通过配置参数jobmanager.memory.off-heap.size设置堆外内存的大小。如果遇到 JobManager 进程抛出 "OutOfMemoryError: Direct buffer memory"的异常,可以尝试调大这项配置。
以下情况可能用到堆外内存:
- Flink 框架依赖(例如 Akka 的网络通信)
- 在作业提交时(例如一些特殊的批处理 Source)及 Checkpoint 完成的回调函数中执行的用户代码
提示:如果同时配置了 Flink 总内存和 JVM 堆内存,且没有配置堆外内存,那么堆外内存的大小将会是 Flink 总内存减去JVM 堆内存。这种情况下,堆外内存的默认大小将不会生效。
如果你是在本地运行 Flink(例如在 IDE 中)而非创建一个集群,那么 JobManager 的内存配置将不会生效。
内存调优
独立部署模式(Standalone Deployment)下的内存配置
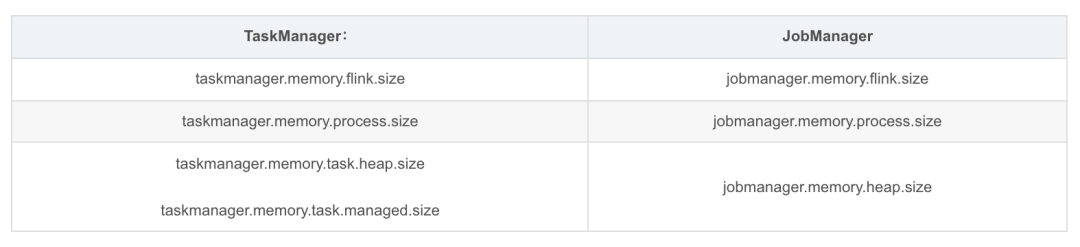
独立部署模式下,我们通常更关注 Flink 应用本身使用的内存大小。建议配置 Flink 总内存(taskmanager.memory.flink.size 或者 jobmanager.memory.flink.size)或其组成部分。此外,如果出现 Metaspace 不足的问题,可以调整 JVM Metaspace 的大小。
这种情况下通常无需配置进程总内存,因为不管是 Flink 还是部署环境都不会对 JVM 开销 进行限制,它只与机器的物理资源相关。
容器(Container)的内存配置
在容器化部署模式(Containerized Deployment)下(Kubernetes、Yarn 或 Mesos),建议配置进程总内存(taskmanager.memory.process.size或者jobmanager.memory.process.size)。该配置参数用于指定分配给 Flink JVM 进程的总内存,也就是需要申请的容器大小。
提示:如果配置了 Flink 总内存,Flink 会自动加上 JVM 相关的内存部分,根据推算出的进程总内存大小申请容器。
注意:如果 Flink 或者用户代码分配超过容器大小的非托管的堆外(本地)内存,部署环境可能会杀掉超用内存的容器,造成作业执行失败。
- State Backend 的内存配置
执行无状态作业或者使用 Heap State Backend(MemoryStateBackend 或 FsStateBackend)时,建议将托管内存设置为 0。这样能够最大化分配给 JVM 上用户代码的内存。
- RocksDB State Backend
RocksDBStateBackend使用本地内存。默认情况下,RocksDB 会限制其内存用量不超过用户配置的托管内存。因此,使用这种方式存储状态时,配置足够多的托管内存是十分重要的。如果你关闭了 RocksDB 的内存控制,那么在容器化部署模式下如果 RocksDB 分配的内存超出了申请容器的大小(进程总内存),可能会造成 TaskExecutor 被部署环境杀掉。请同时参考如何调整 RocksDB 内存以及 state.backend.rocksdb.memory.managed。
- SortMerge数据Shuffle内存配置
对于SortMerge数据Shuffle,每个ResultPartition需要的网络缓冲区(Buffer)数目是由taskmanager.network.sort-shuffle.min-buffers这个配置决定的。它的 默认值是64,是比较小的。虽然64个网络Buffer已经可以支持任意规模的并发,但性能可能不是最好的。对于大并发的作业,通 过增大这个配置值,可以提高落盘数据的压缩率并且减少网络小包的数量,从而有利于提高Shuffle性能。为了增大这个配置值, 你可能需要通过调整taskmanager.memory.network.fraction,taskmanager.memory.network.min和taskmanager.memory.network.max这三个参数来增大总的网络内存大小从而避免出现insufficient number of network buffers错误。
除了网络内存,SortMerge数据Shuffle还需要使用一些JVM Direct Memory来进行Shuffle数据的写出与读取。所以,为了使 用SortMerge数据Shuffle你可能还需要通过增大这个配置值taskmanager.memory.task.off-heap.size来为其来预留一些JVM Direct Memory。如果在你开启 SortMerge数据Shuffle之后出现了Direct Memory OOM的错误,你只需要继续加大上面的配置值来预留更多的Direct Memory 直到不再发生Direct Memory OOM的错误为止。
常见问题
IllegalConfigurationException
如果遇到从 TaskExecutorProcessUtils 或 JobManagerProcessUtils 抛出的 IllegalConfigurationException 异常,这通常说明您的配置参数中存在无效值(例如内存大小为负数、占比大于 1 等)或者配置冲突。请根据异常信息,确认出错的内存部分的相关文档及配置信息
OutOfMemoryError: Java heap space
该异常说明 JVM 的堆空间过小。可以通过增大总内存、TaskManager 的任务堆内存、JobManager的JVM堆内存等方法来增大JVM堆空间。
提示:也可以增大 TaskManager 的框架堆内存。这是一个进阶配置,只有在确认是 Flink 框架自身需要更多内存时才应该去调整。
OutOfMemoryError: Direct buffer memory
该异常通常说明 JVM 的直接内存限制过小,或者存在直接内存泄漏(Direct Memory Leak)。请确认用户代码及外部依赖中是否使用了 JVM 直接内存,以及如果使用了直接内存,是否配置了足够的内存空间。可以通过调整堆外内存来增大直接内存限制。
OutOfMemoryError: Metaspace
该异常说明 JVM Metaspace 限制过小。可以尝试调整 TaskManager、JobManager 的 JVM Metaspace。
IOException: Insufficient number of network buffers
该异常仅与 TaskManager 相关。
该异常通常说明网络内存过小。可以通过调整以下配置参数增大网络内存:
- taskmanager.memory.network.min
- taskmanager.memory.network.max
- taskmanager.memory.network.fraction
容器(Container)内存超用
如果 Flink 容器尝试分配超过其申请大小的内存(Yarn、Mesos 或 Kubernetes),这通常说明 Flink 没有预留出足够的本地内存。可以通过外部监控系统或者容器被部署环境杀掉时的错误信息判断是否存在容器内存超用。
对于 JobManager 进程,你还可以尝试启用 JVM 直接内存限制(jobmanager.memory.enable-jvm-direct-memory-limit),以排除 JVM 直接内存泄漏的可能性。
如果使用了 RocksDBStateBackend 且没有开启内存控制,也可以尝试增大 TaskManager 的托管内存。
对于 JobManager 进程,你还可以尝试启用 JVM 直接内存限制(jobmanager.memory.enable-jvm-direct-memory-limit),以排除 JVM 直接内存泄漏的可能性。
如果使用了 RocksDBStateBackend 且没有开启内存控制,也可以尝试增大 TaskManager 的托管内存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号