CenterMask: Single Shot Instance Segmentation with Point Representation
论文:CenterMask: Single Shot Instance Segmentation with Point Representation
0.简介
惯例,有请作者自己介绍——摘要:
- 将实例分割分为两个子任务:局部形状预测——区分实例即使重叠在一起;全局显著性生成——对整个图像进行pixel-to-pixel分割。
- 局部信息取自物体中心点(center points)的表示。(请见我在第一节中补充的 CenterNet部分)
- 在COCO上34.5maskAP,12fps。
作者认为单阶段实体分割现在有两个主要挑战:
- 如何区分实体,尤其是同类别,重叠的情况。
- 如何保留像素级的局部位置信息。双阶段和单阶段方法都面临这一像素对齐问题,即特征结果转换为原始物体大小,或利用固定个数的点对轮廓进行描述(如PolarMask?),无法保留原始图像的空间信息。
作者也将目前单阶段实体分割模型分为两类:
- 基于全局图像的方法。一般先生成全局特征图,然后特征组合生成最终Mask。优点是能较好保留位置信息,实现像素级的特征对齐(pixel-to-pixel alignment);缺点是难以解决重叠遮挡问题。如YOLACT。
- 基于局部图像的方法。优点是利于解决重叠遮挡问题;但分割精度不足,即不能较好保留位置信息。
而CenterMask同时包含一个全局显著图生成分支和一个局部形状预测分支。分割既精细准确又能区分不同实例。
1.CenterMask结构
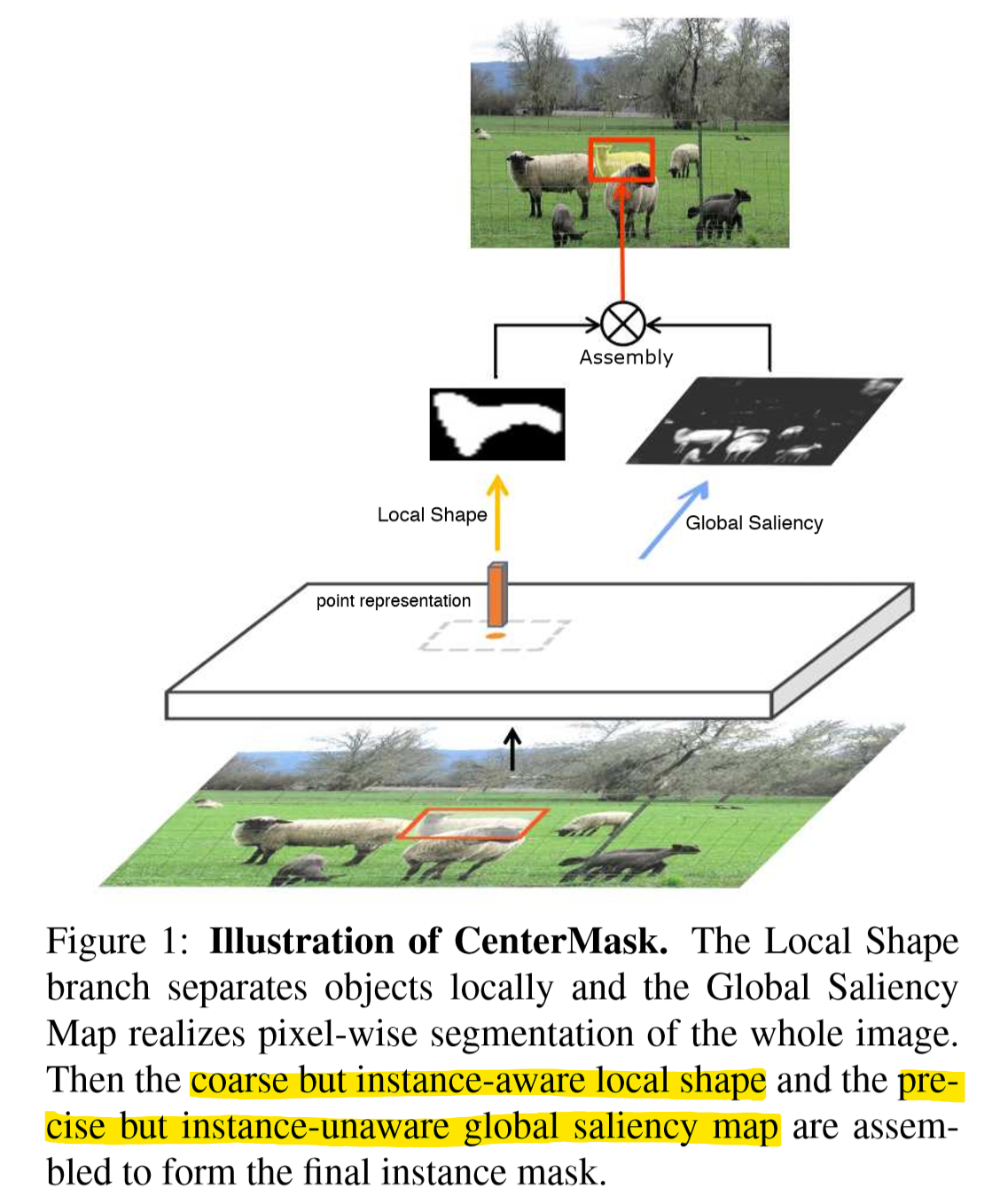
CenterMask模型的主要思想就是,把实例分割分为两个子任务:一个负责预测粗糙但是实例敏感的局部形状,另一个负责预测精确但是实例不敏感的全局显著图。
另外一个显著特点是,CenterMask基于CenterNet的工作,用center point建模物体,是anchor-free的。这就是上图所示的point representation。没有看过CenterNet的话学习CenterMask可能从始至终都会有很多疑惑,所以我们先来看一下另一篇工作:Objects as Points (CenterNet)
CenterNet:Objects as Points
We model an object as a single point — the center point of its bounding box.
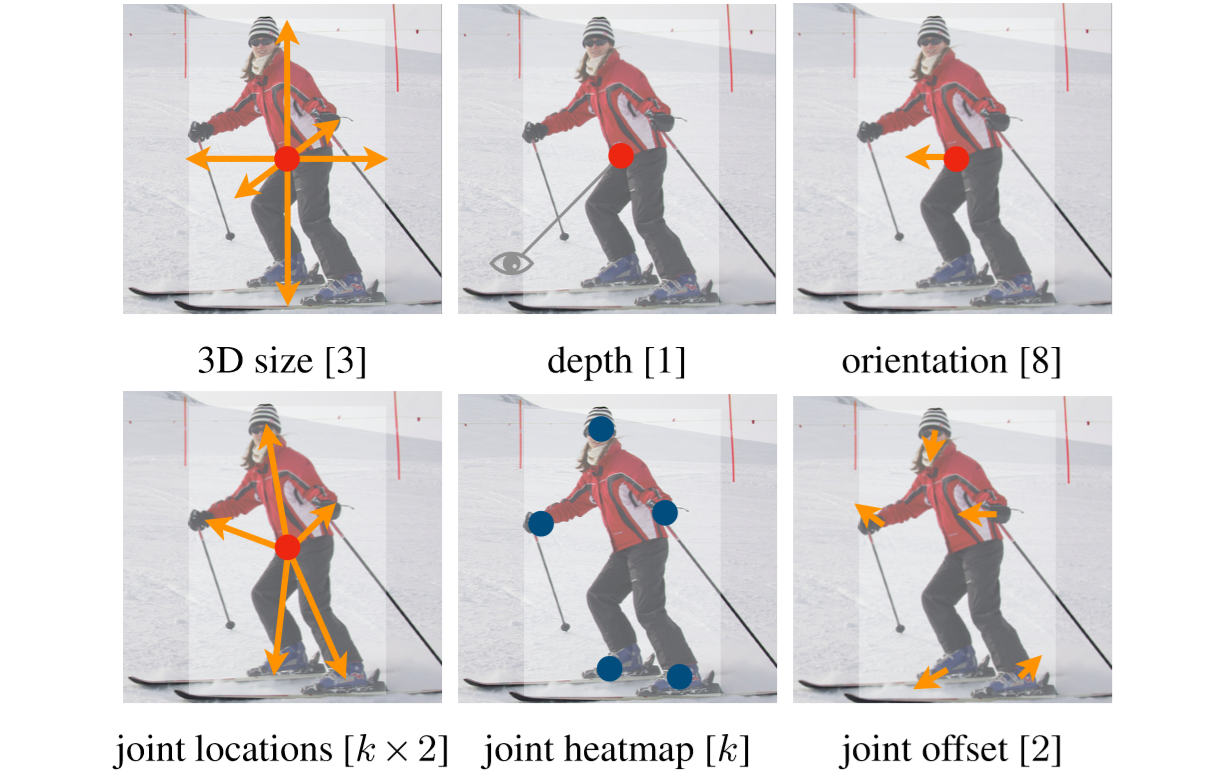
正如论文标题及原文摘要的这句话,CenterNet的作者将每个物体建模为一个点——bounding box的中心点(center point),物体的其他属性通过回归来预测,预测哪些属性由特定任务决定,如尺寸、3D位置、方向甚至姿态等。
具体算法流程为:
-
输入图像,主干网络提取特征,得到特征图。
-
后接三个平行Head网络,分别生成生成:
-
HeatMap。即用来center points的keypoint heatmap;这一分支也负责了分类,输出中一个类别对应一个channel。
-
Offset。调整center points的位置,以恢复特征图与原图之间不对齐问题造成的偏差( to recover the discretization error caused by the output stride. )
-
Size。即预测center point代表物体的大小。
-
-
通过HeatMap找peak,其反映的就是center points(这里的peak定义为局部最大,找的方法就是某点比8邻域都大的,通过3×3的maxpooling实现,类似于NMS。这就是作者提到的一个优点——CenterNet无需NMS)。Offset对center point位置进行调整,然后size在此point location上显示物体大小。

对于其他的任务,可以设计添加不同的分支:
CenterMask
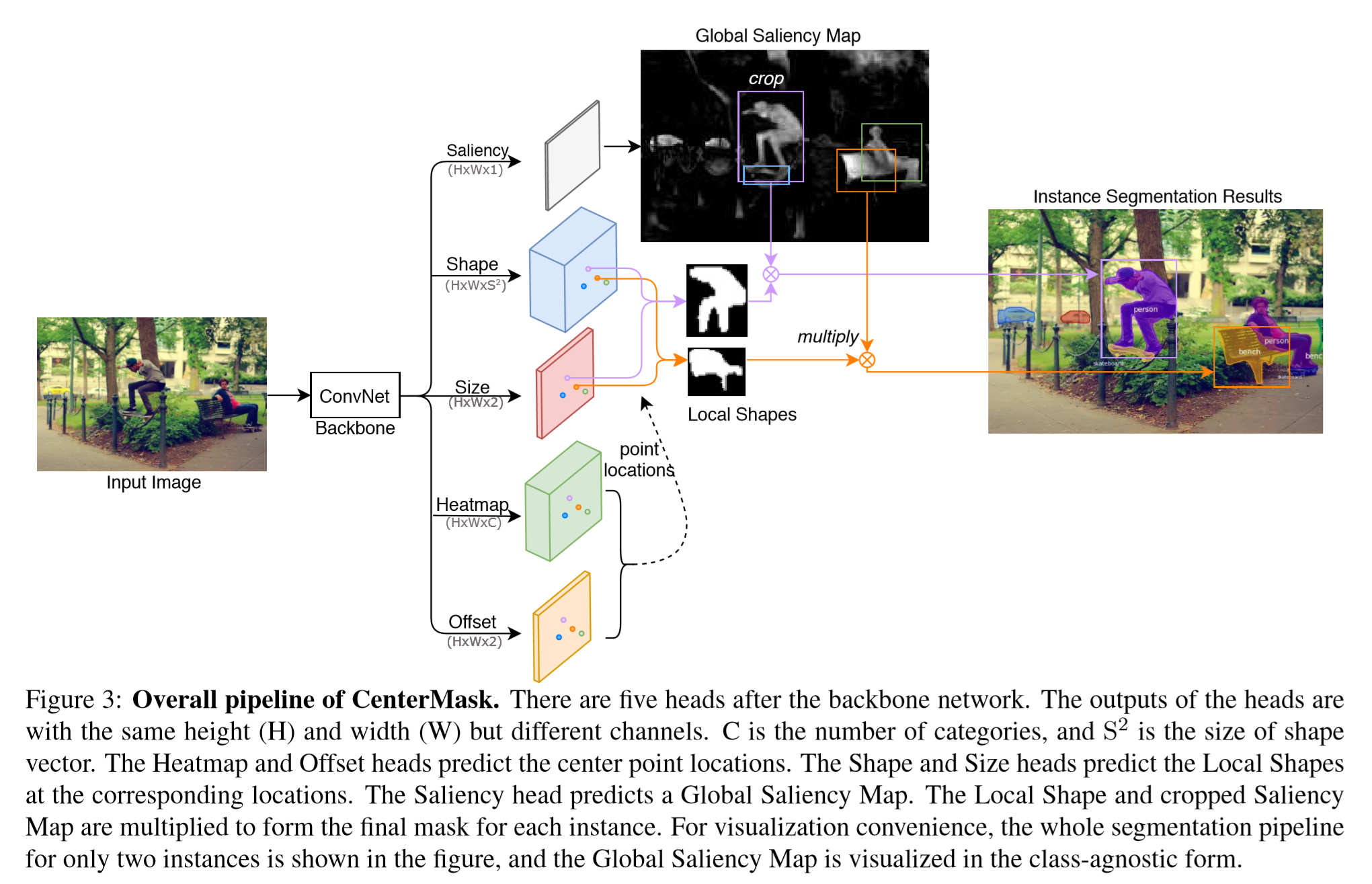
如上图所示,下面的两个分支,我们在CenterNet中已经简单说明,详情可学习CenterNet的原文了解,也是一项很好的工作,值得一学。下面我们还是将镜头拉回这次的主角,负责预测实例mask的上面的分支(其实size分支和CenterNet中的size基本一样的,只不过这里也同时和shape分支合作预测local shape)。
先说CenterMask的整体流程,图像输入到Hourglass network中提取特征,得到center points之后(每一个center point就是一个实例对象),shape和size分支预测出Local shapes,同时saliency分支生成全局显著图,然后这两个结果做Hadamard矩阵乘,得到最后结果。下面详细展开:
2.Local Shape Prediction
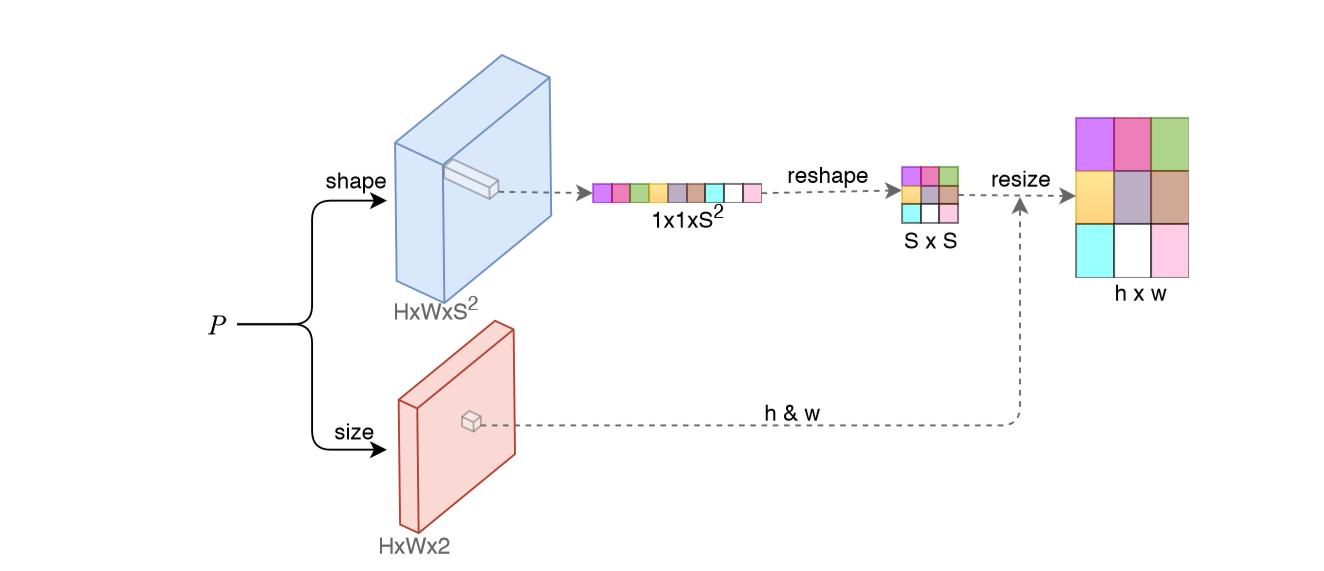
P为主干网络提取出的特征图,H×W为shape和size分支生成特征图的大小,shape分支通道为\(S^2\),\(F_{shape}\in \mathbb{R}^{H×W×S^2}\),size分支通道为2(即长宽h&w)。对于一个在feature map的center ponit \((x,y)\),它的形状被提取在\(F_{shape}(x,y)\),向量尺寸为\(1×1×S^2\),然后reshape为S×S,再结合size的输出h&w,resize为h×w,至此就得到了代表着一个实例对象的center ponit对应的局部形状结果。这一结果因为是由每个center point来的,所以能够很好区分即使同类重叠的实例对象,但由于是尺寸固定的形状向量\((s×s)\)只能预测出比较粗糙的mask,所以还需要下面的Global Saliency Generation来提升分割的精度。
3.Global Saliency Generation
这一分支作为一种校准机制来调整local shape的Mask结果。将生成一张全局显著图,这张图的目的是表示每一像素的显著性,也就是说这个像素是否属于一个物体的区域。
是一个FCN网络来对每个像素分类,但与标准语义分割的FCN不同,最后不适用softmax,而是对对每一类使用sigmoid进行二分类,避免类间竞争。(与MaskRCNN一样)
另外,有两个模式:
- 类别不可知(class-agnostic),生成H×W×1的二值map。
- 类别明确(class-specific),生成H×W×C的二值map,每一通道都是一个类别对应的map。
4.Mask Assembly
最后对local shape和global saliency进行整合得到最后结果,local shape \(L_{k}\in \mathbb{R}^{h×w}\),把global saliecny也切割为一个个的\(G_{k}\in \mathbb{R}^{h×w}\),然后分别用sigmoid整合到(0,1)的区间,最后两者做Hadamard乘积(就是两矩阵对应元素分别相乘):
我们看下图来直观理解,only local shape、only global saliency 以及 两者结合的CenterMask效果,两者的特点还是很明显、很符合本文理论论述的:

5.Loss Fuction
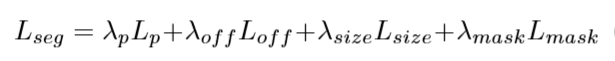
整体LossFunction由四部分构成,其中最后一部分\(L_{mask}\)是实例分割mask的,我们先看这部分。
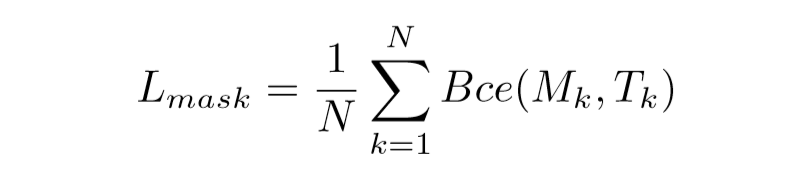
需要注意的是,Mask由local shape和global saliency两个分支组装得来,但实际训练时并没有为这两个分支网络设置各自单独的loss,而是直接对整个mask结果做惩罚。N是实例的个数,Bce表示对于像素的二分类交叉熵。
其余三项损失并不是本文提出的,而是直接沿用了CenterNet的,在那篇文章和文本都有介绍,下面我们来一项一项过一下:
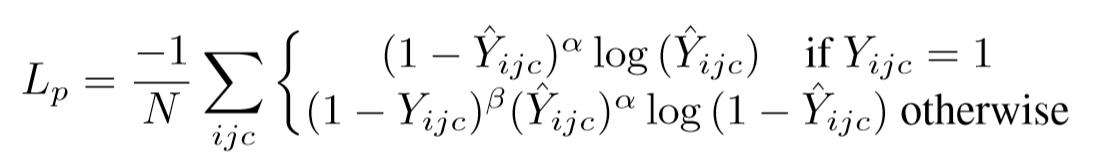
\(L_p\)为预测center points(heat map)的一个focal loss,\(Y\)是heatmap的ground truth,\(\hat{Y}_{ijc}\)是在预测出的heatmap中位置(i,j)对于类别c的得分。\(\alpha\) 和 $\beta \(的是focal loss的超参,应是延用CenterNet的数值(\)\alpha=2, \beta=4$)。
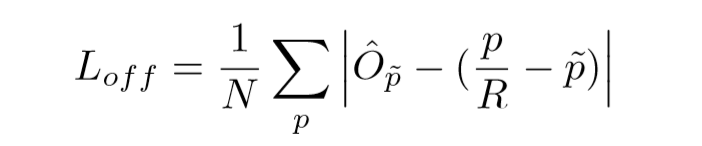
offset的loss采用L1的形式。\(\hat{O}\)是预测出的偏移offset;p表示ground truth的center point;R是output stride,比如原图像是400×400,而分割是在50×50的特征图上做的,则output stride就是8,低分辨率的\(\tilde{p}=\lfloor \frac{P}{R} \rfloor\),这其中的还原取整操作会带来误差,所以需要offset分支产生偏移来矫正。
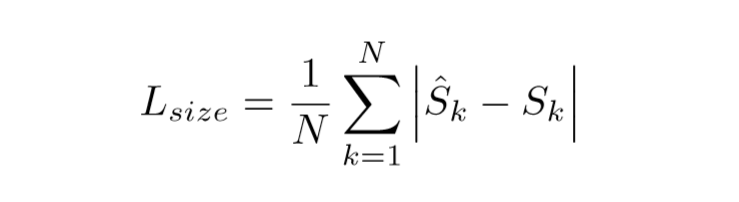
这一项就非常简单了,分别表示预测出的size和ground truth的size(h,w)。
最后,这四项参数线性组合时的权重分别为1,1,0.1,1。使用Adam迭代更新。
参考及引图:
https://arxiv.org/pdf/1904.07850.pdf
https://tech.meituan.com/2020/05/21/cvpr2020-centermask.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号