一次百万请求mq堆积的生产排查
问题描述:奖励发放服务,每日请求350万左右,mq10点堆积 38万,11点堆积57万,影响线上奖励发放。
服务器基本信息:服务器5个节点,节点配置4核 8G
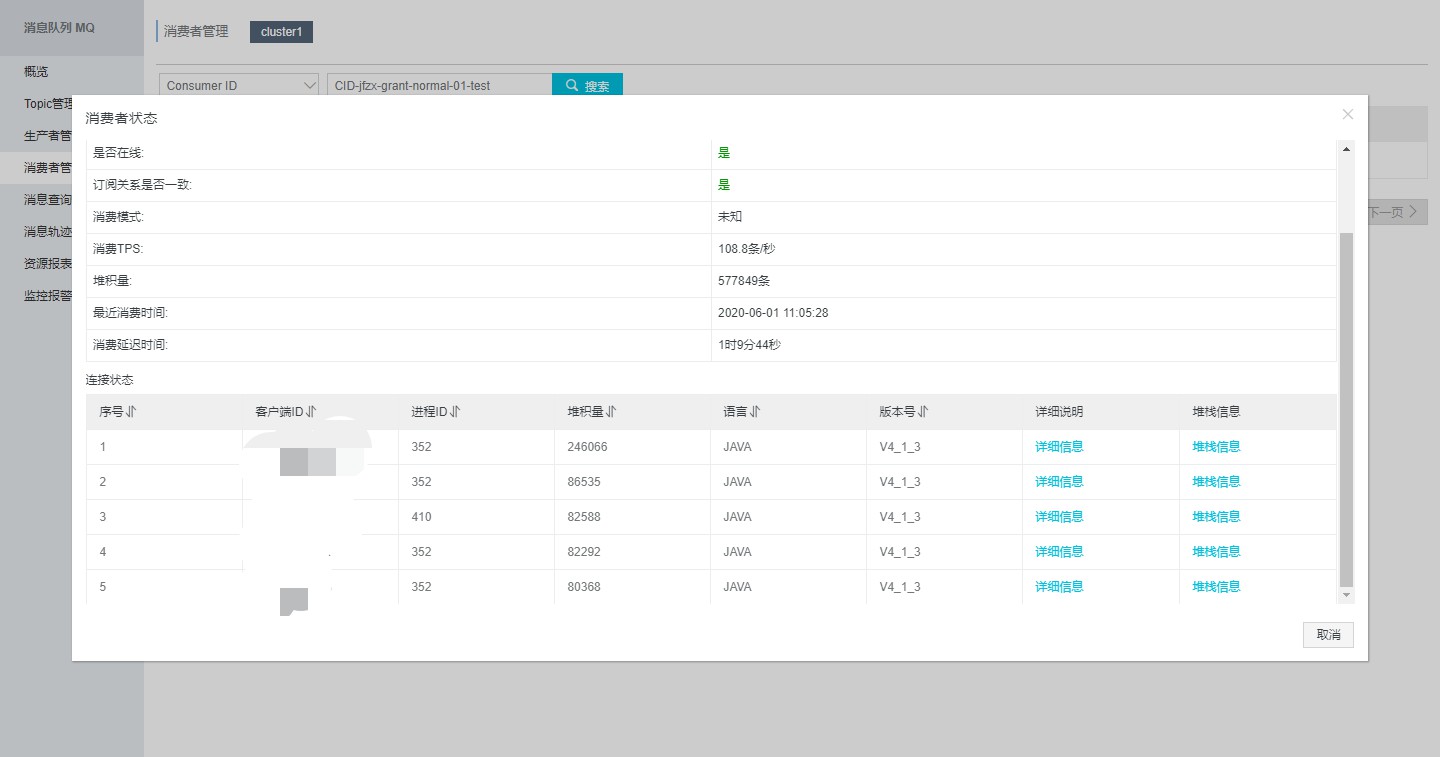
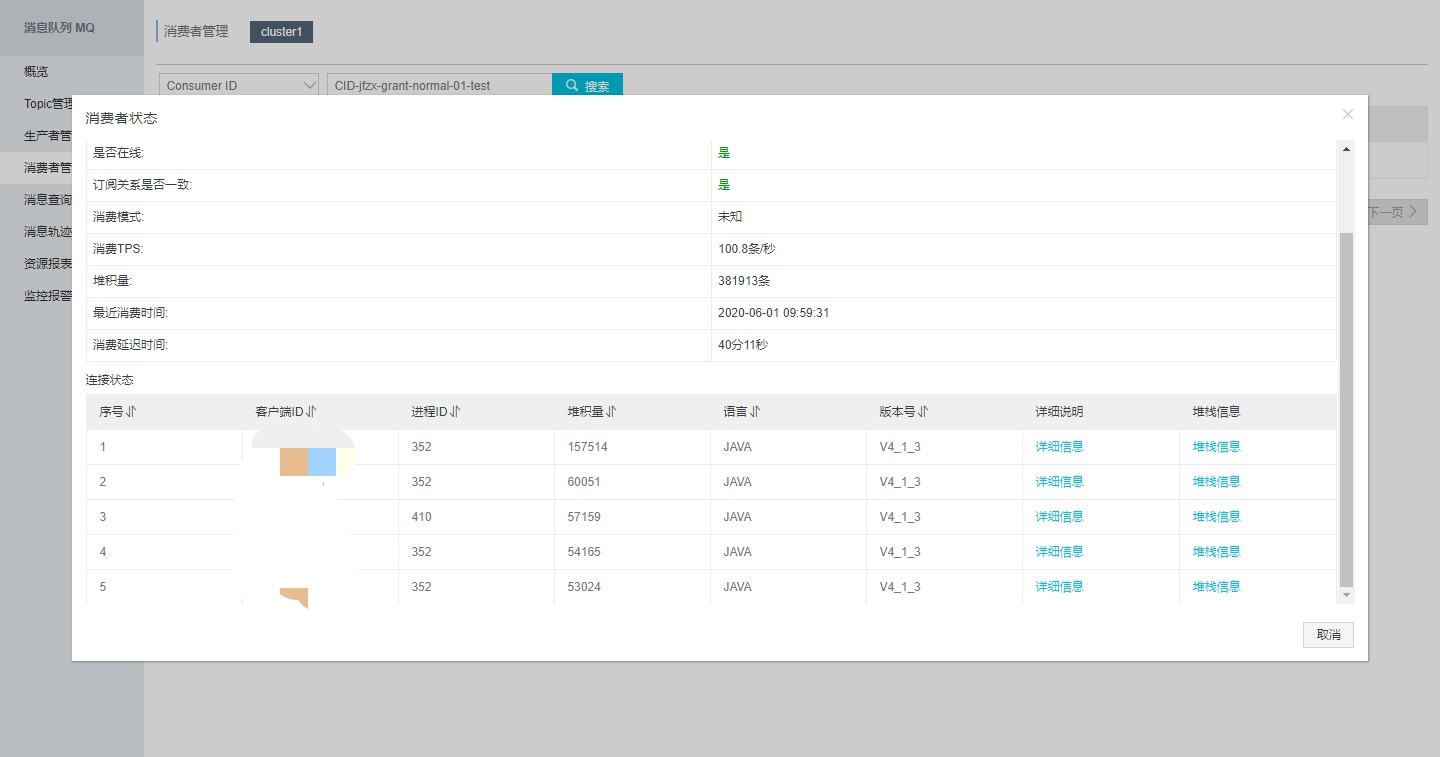
根据mq堆积情况初步判断是下游系统的消费能力跟不上了,紧急给下游系统进行了扩容。但是问题没有得到解决。依然有堆积。开始分析当前派发服务的配置和jvm。
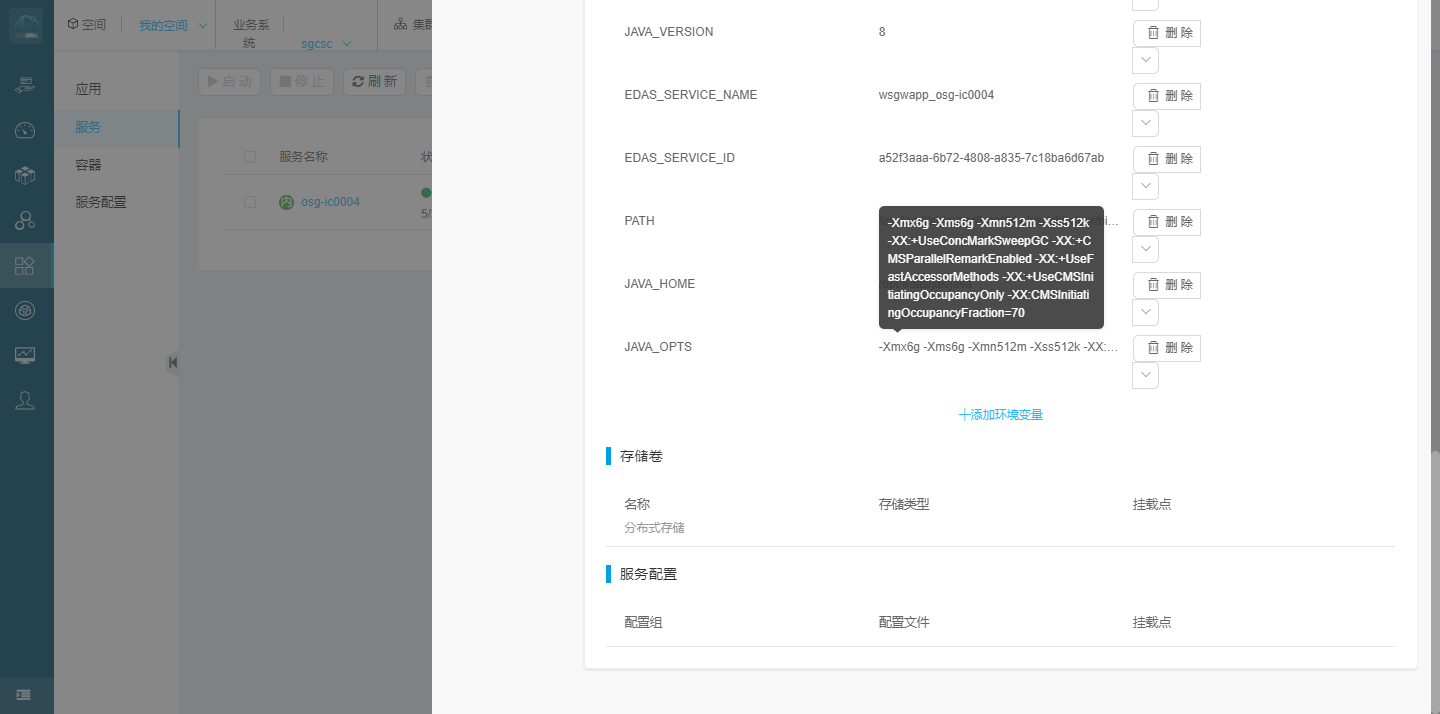
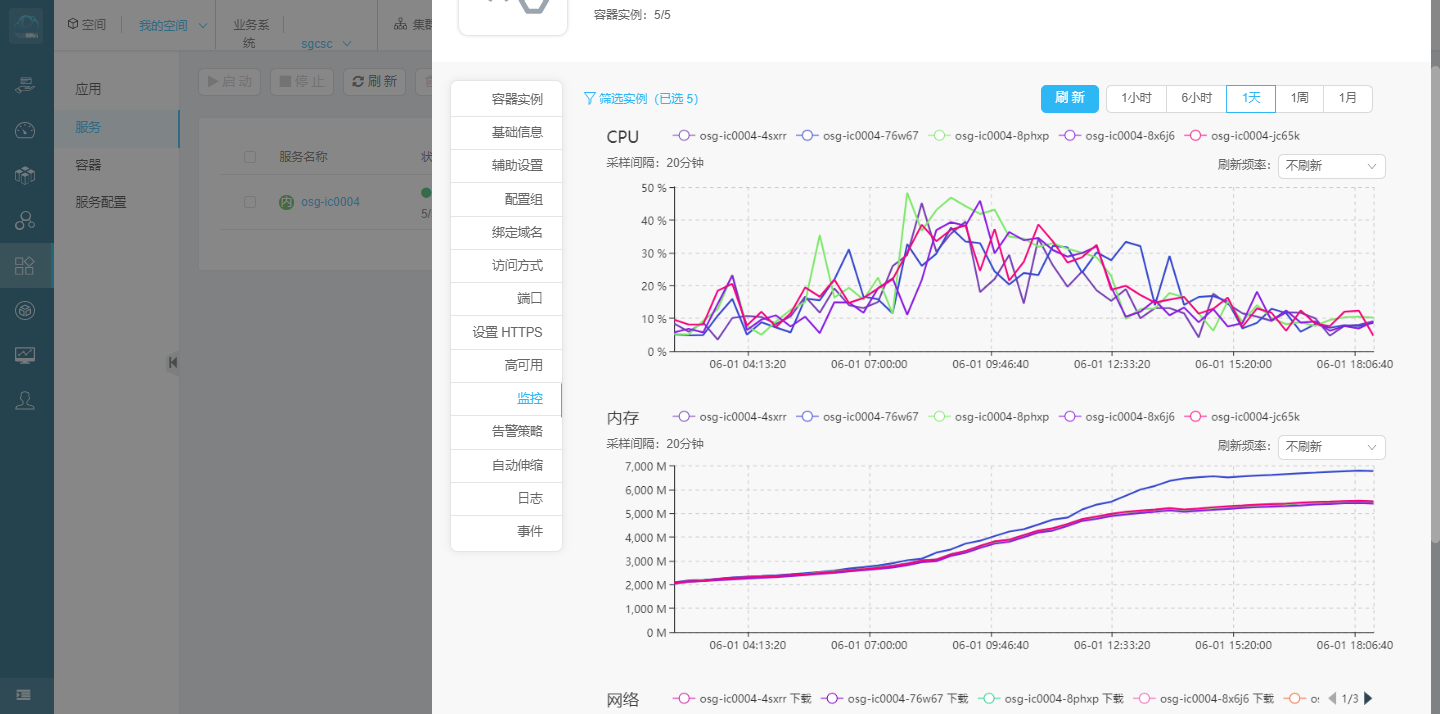
通过jvm参数分析,发现cpu才到50%左右 内存使用已经接近7G 将近90%。查看gc配置参数,分析后决定服务节点扩容,将原来 5个节点扩容为10个节点。
-----再次补充,节点扩容后6月2号依然出现了消息堆积。没办法,硬着头皮继续分析。还是怀疑下游系统的业务处理能力,因为报错就在哪里,time out 超时,使用的http请求工具类是我们自己封装的。连接超时和数据响应超时都设置的5秒。
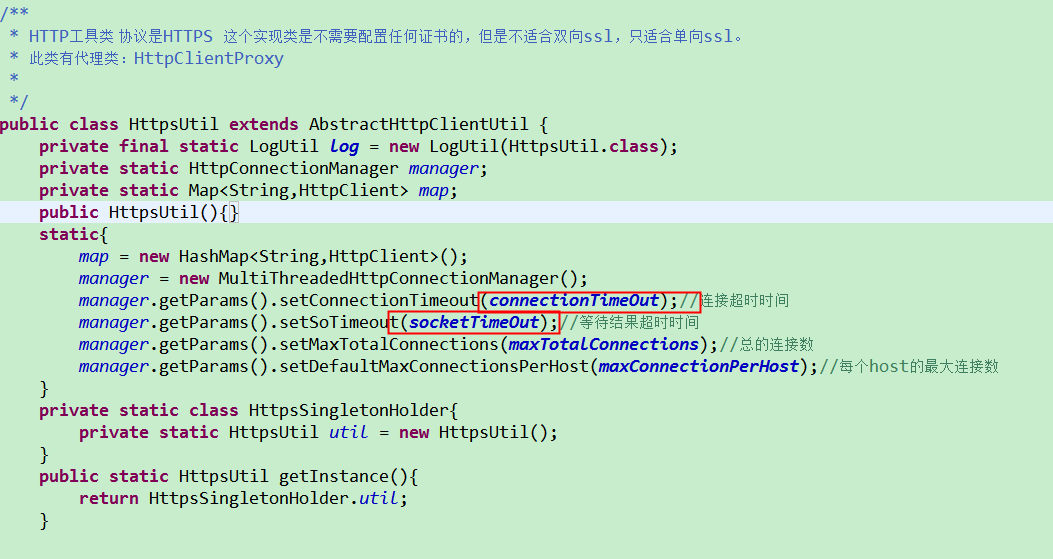
开始排查整个链路的请求, 活动--专线--负载--ng--uep--ac。分析了 5分钟的数据量。
2020-06-01 10:00:25.191----2020-06-01 10:05:25.184
请求次数:4756次
超时:91次
2020-06-01 10:00:25.191----2020-06-01 10:05:25.184
请求次数:4693次
超时:93次
2020-06-01 10:00:25.191----2020-06-01 10:05:25.184
请求次数:4730次
超时:100次
2020-06-01 10:00:25.191----2020-06-01 10:05:25.184
请求次数:3949次
超时:1次
2020-06-01 10:00:25.191----2020-06-01 10:05:25.184
请求次数:4315次
超时:93次
但是由于ng没有日志监控 无法确定具体的访问量,没能查到具体原因。
-----------------------------------------------------------------我是服务突然恢复的分割线--------------------------------------------------------------------
6月3号 上午持续监控mq 发现8点到10点,mq很健康没有堆积。一群人都在想?what?谁做了什么?怎么就好了?我们什么也没干呀。
然后老大就来了波神操作 取了2号和3号,全时段的请求量数据分析。
就是下面这两个
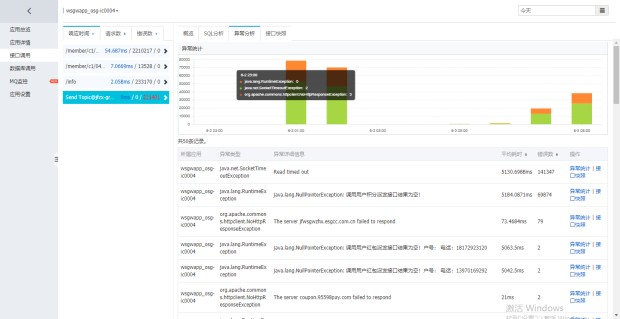
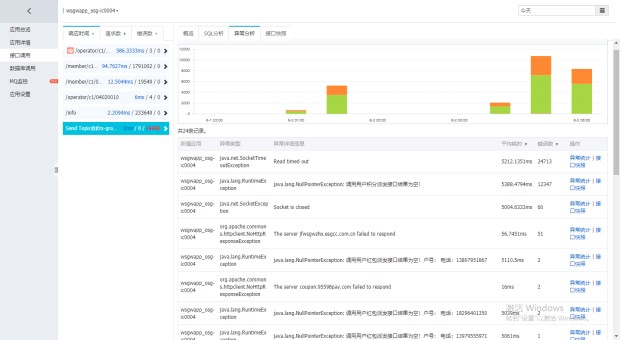
仔细对比了,我自闭了,这呢嘛完全是上游系统给我疯狂请求造成的呀。3号的请求高峰提前了,所以没有消息堆积。
罪魁祸首是我上游的风控系统没有控制住,造成了盗刷数据并发请求,服务处理不过来了,产生了堆积。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
6月9号补充,问题并没有得到好的解决,这几天继续分析追踪每个环节,逐个优化,首先要解决的就是大量并发请求的情况下,下游系统超时情况,排查到请求接收的入口,把uep调用ac的负载均衡由ng改为了F5。
现在mq的消费能力TPS峰值是177条/s 也就是177*60*60 = 637200 /小时 消费能力有待提升,初步目标是每秒 277条,达到每小时百万消息处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号