Redis 相关知识点(持续更新)
一、什么是NoSQL
要介绍Redis前必须要先介绍下NoSQL,这两者间密不可分。什么是NoSQL?
NoSQL即(not only SQL)不仅仅是SQL,泛指非关系数据库/技术。非关系数据库在高并发的场景下有巨大优势,这点MySQL等关系型数据库是无法相比的。另外NoSQL在数据分析数据挖掘也更胜一筹。Redis和MongoDB是当前较流行的NoSQL。
二、Redis和MySQL的区别
两者间外在的区别主要体现在性能的差别:Redis的单位时间内的读/写速度往往是MySQL几倍到十几倍。
之所以两者有这么大性能差异主要因为两方面:
- MySQL数据持久化时面向硬盘,而Redis面向内存,所以读写更快
- MySQL存储和查询都更加复杂,要考虑索引、范式等,Redis存储和查询都更加简单,且Redis是单线程的非阻塞IO(IO多路复用)处理那么多的并发客户端连接多路复用IO,单线程避免了线程切换的开销,而多路复用IO避免了IO等待的开销。
Redis确实有很多优点,但是目前不能完全替代Mysql等关系型数据库,因为Redis也有很多的缺点,比如存储在内存上如果掉电就会丢失,内存相较硬盘代价高昂,虽然有事务但确实只能覆盖简单场景等,现实中往往是MySQL和Redis结合使用。
举个例子:在整点秒杀商品时,大量请求到来时,Mysql要在短时间内执行大量的SQL,很容易造成数据库“罢工”,这样的场景一般会考虑异步写入数据库,而在高速读写时使用Redis来抵挡这些大量请求,在满足一定的条件时,触发这些缓存在Redis中的数据写入数据库。
也就是请求到达时都是在redis中进行写,没有进行数据库的写操作,由于redis的高性能这样保证快速响应。当请求不在那么多时,或者业务已经结束时(比如商品秒杀完了,红包抢完了),将Redis缓存的数据写入数据库进行持久化。
同理,在读取的时候也可以优先读取Redis缓存,在Redis读取失败是再从MySQL等数据读取,如下:

三、什么场景下考虑使用Redis?
上面说了Redis往往和MySQL结合使用,那么到底什么时候考虑使用Redis?主要从下面3个方面考虑:
- 要操作的数据命中率(是否经常使用)高不高,如果命中率低没必要使用Redis;
- 读写谁更多?若写操作多于读操作,也没有必要使用Redis;
- 数据大小如何?若较大会给内存带来很大压力,也没必要使用Redis
四、Redis支持的6种数据类型
可以参考 Redis底层数据结构 。
五、Spring中集成Redis
添加依赖
<!-- Redis依赖 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.1</version>
</dependency>做个简单的性能测试:
public void performance() {
Jedis jedis = new Jedis("localhost", 6379);
int i = 0;
long start = System.currentTimeMillis();
while (true) {
long end = System.currentTimeMillis();
if (end - start >= 1000) {
break;
}
i++;
jedis.set("key" + i, "value" +i);
}
System.out.println("redis每秒写入" + i + "次");
}结果:redis每秒写入19023次。这里是自测结果,是串行执行,是一条条执行的,若采用流水线技术则会高得多。
六、获取Redis连接的两种方式 及 两种操作方式
获取Redis连接有两种方式:
- 通过jedisPool
- 通过JedisConnectionFactory连接工厂
两种方式也分别对应两种操作方式:
-
Jedis
-
RedisTemplate
七、Redis的事务
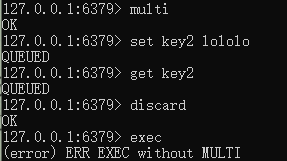
在Redis 开启事务是 multi 命令,而执行事务是 exec 命令。multi 和 exec 命令之间的 Redis 令将采取进入队列的形式,直至exec 命令的出现,才会 次性发送队列里的命令 去执行,而在执行这些命令的时候其他客户端就不能再插入任何命令了,这就是 Redis 事务机制。

八、发布订阅
这里涉及到一个模式:观察者模式,可以参考:观察者模式Observer -- 深入理解_沙滩的流沙520的博客-CSDN博客

这个过程可以使用redis客户端模拟一下:

8.1 监听类
public class Demo1 implements MessageListener {
@Override
public void onMessage(Message message, byte[] pattern) {
// 获取消息
byte[] body= message . getBody() ;
// 获取 channel
byte[] channel = message . getChannel();
}
}这里你肯定想知道Message类有啥,它实际是个接口,源码如下:


8.2 怎么发布?
public void publishMessage(){
String channel = "chat";
redisTemplate.convertAndSend(channel, "Hello");
}九、Redis 内存回收策略

-
olatil -lru: 采用最近使用最少的淘汰策略, 只淘汰那些超时(仅仅是超时的)的键值对
-
allkey-lru: 采用淘汰最少使用的策略, 将对所有的(不仅仅是超时的)键值对采用最近使用最少的淘汰策略
-
olatil-random :采用随机淘汰策略删除超时的(仅仅是超时的)键值对
-
allkeys- random : 采用随机、淘汰策略删除所有的(不仅仅是超时的)键值对,这个策 略不常用
-
volatile-ttl: 采用删除存活时间最短的键值对策略
-
noeviction: 根本就不淘汰任何键值对 当内存己满时 如果做读操作,例如 get 它将正常工作,而做写操作,它将返回错误 也就是说 Redis 采用这个策略内存达最大时, 它就只能读而不能写了。
-
volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
-
volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
-
allkeys-lfu:从所有键中驱逐使用频率最少的键
十、Redis的持久化机制
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。但Redis为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。先看下Redis的持久化流程。
10.1 Redis持久化流程
-
客户端向服务端发送写操作(数据在客户端的内存中)。
-
数据库服务端接收到写请求的数据(数据在服务端的内存中)。
-
服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
-
操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
-
磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
10.2 RDB机制
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。而在Redis服务器启动时,会重新加载dump.rdb文件的数据到内存当中恢复数据。
开启RDB持久化方式很简单,客户端可以通过向Redis服务器发送save或bgsave命令让服务器生成rdb文件,或者通过服务器配置文件指定触发RDB条件。
10.2.1 save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,即不能响应其他客户端的请求,直到RDB过程完成为止。

10.2.2 bgsave触发方式
与save命令不同,bgsave命令是一个异步操作。Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。

当客户端发服务发出bgsave命令时,Redis服务器主进程会forks一个子进程来数据同步问题,在将数据保存到rdb文件之后,子进程会退出。
所以,与save命令相比,Redis服务器在处理bgsave采用子线程进行IO写入,而主进程仍然可以接收其他请求,但forks子进程是同步的,所以forks子进程时,一样不能接收其他请求,这意味着,如果forks一个子进程花费的时间太久(一般是很快的),bgsave命令仍然有阻塞其他客户的请求的情况发生。
10.2.3 自动触发(通过服务器配置文件指定触发RDB条件)
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000。
②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤dbfilename :设置快照的文件名,默认是 dump.rdb
⑥dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
这种通过服务器配置文件触发RDB的方式,与bgsave命令类似,达到触发条件时,会forks一个子进程进行数据同步,不过最好不要通过这方式来触发RDB持久化,因为设置触发的时间太短,则容易频繁写入rdb文件,影响服务器性能,时间设置太长则会造成数据丢失。
RDB 的优势和劣势:
①、优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
10.3 AOF机制
全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的“写”命令都通过write函数追加到文件中。通俗的理解就是日志记录。每当有一个写命令过来时,就直接保存在我们的AOF文件中。如果 appendonly 配置为 no ,则不启用 AOF 方式进行备份。
10.3.1 AOF原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。

重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
AOF也有三种触发机制
(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)不同no:从不同步

10.3.2 AOF优缺点
优点:
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
缺点:
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
10.4 RDB和AOF到底该如何选择
选择的话,两者加一起才更好。因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用。有一张图可供总结:

十一、Redis 部署架构
11.1 单机版

11.2 主从复制

Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。只要主从服务器之间网络连接正常,主从服务器两者会具有相同数据,主服务器就会一直将发生在自己身上的数据更新同步给从服务器,从而一直保证主从服务器的数据相同。
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交给从库
11.3 哨兵

- 通过发送命令,让Redis务器返回监测其运行状态,包括主服务器和从服务器。
-
当哨兵监测到 master 宕机, 会自动在slave中选举新的master,将这个被选举的slave 切换成 master ,然后通过发布订阅模式通知到其他的从服务器,修改配置文件,让它们切换主机
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
问题:主从模式,切换需要时间丢数据,没有解决 master 写的压力。
11.4 集群(proxy型)

特点:
2、支持失败节点自动删除
3、后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
问题:
11.5 集群(直连型)_ Redis Cluster主从模式

特点:
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
问题:
1、资源隔离性较差,容易出现相互影响的情况。
2、数据通过异步复制,不保证数据的强一致性
Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
上面那个例子里, 集群有ABC三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也可以继续正确工作。
B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
redis主从复制,主从同步过程:
(1)从节点执行slaveofmasterIP,保存主节点信息
(2)从节点中的定时任务发现主节点信息,建立和主节点的socket连接
(3)从节点发送Ping信号,主节点返回Pong,两边能互相通信
(4)连接建立后,主节点将所有数据发送给从节点(数据同步)
(5)主节点把当前的数据同步给从节点后,便完成了复制的建立过程。接下来,主节点就会持续的把写命令发送给从节点,保证主从数据一致性。
主从刚刚连接的时候,进行全量同步(RDB);全同步结束后,进行增量同步(AOF)。
默认采用异步复制。
十二、如何用Redis实现分布式锁?
在实现分布式锁之前,我们先考虑如何实现,以及都要实现锁的哪些功能。
- 分布式特性(部署在多个机器上的实例都能够访问这把锁)
- 排他性(同一时间只能有一个线程持有锁)
- 超时自动释放的特性(持有锁的线程需要给定一定的持有锁的最大时间,防止线程死掉无法释放锁而造成死锁)
基于以上列出的分布式锁需要拥有的基本特性,我们思考一下使用Redis该如何实现?
- 第一个分布式的特性Redis已经支持,多个实例连同一个Redis即可
- 第二个排他性,也就是要实现一个独占锁,可以使用Redis的 setnx 命令实现
- 第三个超时自动释放特性,Redis可以针对某个key设置过期时间
- 执行完毕释放分布式锁
Redis Setnx 命令:在指定的 key 不存在时,为 key 设置指定的值。设置成功,返回1, 设置失败,返回0
@RequestMapping("/stock_redis_lock")
public String stock_redis_lock(){
//底层使用setnx命令
Boolean aTrue = stringRedisTemplate.opsForValue().setIfAbsent(lock_key, "true");
stringRedisTemplate.expire(lock_key,10, TimeUnit.SECONDS);//设置过期时间10秒
if (!aTrue) {//设置失败则表示没有拿到分布式锁
return "error";//这里可以给用户一个友好的提示
}
//获取当前库存
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get(key));
if(stock>0){
int afterStock = stock-1;
stringRedisTemplate.opsForValue().set(key,afterStock+"");
System.out.println("扣减库存成功,剩余库存"+afterStock);
}else {
System.out.println("扣减库存失败");
}
stringRedisTemplate.delete(lock_key);//执行完毕释放分布式锁
return "ok";
}上面实现分布式锁的代码已经是一个较为成熟的分布式锁的实现了,对大多数软件公司来说都已经满足需求了。但是上面代码还是有优化的空间,例如:
- 上面的代码我们是没有考虑异常情况的,实际情况下代码没有这么简单,可能还会有别的很多复杂的操作,都有可能会出现异常,所以我们释放锁的代码需要放在finally块里来保证即使是代码抛异常了释放锁的代码他依然会被执行。
- 上面我们的分布式锁的代码的获取和设置过期时间的代码是两步操作第4行和第5行,即非原子操作,就有可能刚执行了第4行还没来得及执行第5行这台机器挂了,那么这个锁就没有设置超时时间,其他线程就一直无法获取,除非人工干预,所以这是一步优化的地方,Redis也提供了原子操作,那就是SET key value EX seconds NX
SET key value [EX seconds] [PX milliseconds] [NX|XX] 将字符串值 value 关联到 key
- EX second :设置键的过期时间为 second 秒。SET key value EX second 效果等同于 SETEX key second value
- PX millisecond :设置键的过期时间为 millisecond 毫秒。SET key value PX millisecond 效果等同于 PSETEX key millisecond value
-
NX :只在键不存在时,才对键进行设置操作。SET key value NX 效果等同于 SETNX key value
-
XX :只在键已经存在时,才对键进行设置操作
SpringBoot的StringRedisTemplate也有对应的方法实现,如下代码:
@RequestMapping("/stock_redis_lock")
public String stock_redis_lock() {try {
//原子的设置key及超时时间
Boolean aTrue = stringRedisTemplate.opsForValue().setIfAbsent(lock_key, "true", 30, TimeUnit.SECONDS);
if (!aTrue) {
return "error";
}
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get(key));
if (stock > 0) {
int afterStock = stock - 1;
stringRedisTemplate.opsForValue().set(key, afterStock + "");
System.out.println("扣减库存成功,剩余库存" + afterStock);
} else {
System.out.println("扣减库存失败");
}
} catch (NumberFormatException e) {
e.printStackTrace();
} finally {
//释放锁
stringRedisTemplate.delete(lock_key);
}
return "ok";
}这样实现是否就完美了呢?对于并发量要求不高或者非大并发的场景的话这样实现已经可以了。
但是对于抢购 ,秒杀这样的场景,当流量很大,这时候服务器网卡、磁盘IO、CPU负载都可能会达到极限,那么服务器对于一个请求的的响应时间势必变得比正常情况下慢很多,那么假设就刚才设置的锁的超时时间为10秒,如果某一个线程拿到锁之后因为某些原因没能在10秒内执行完毕锁就失效了,这时候其他线程就会抢占到分布式锁去执行业务逻辑,然后之前的线程执行完了,会去执行 finally 里的释放锁的代码就会把正在占有分布式锁的线程的锁给释放掉,实际上刚刚正在占有锁的线程还没执行完,那么其他线程就又有机会获得锁了...这样整个分布式锁就失效了,将会产生意想不到的后果。
所以这个问题总结一下,就是因为锁的过期时间设置的不合适或因为某些原因导致代码执行时间大于锁过期时间而导致并发问题以及锁被别的线程释放,以至于分布式锁混乱。在简单的说就是两个问题:
- 自己的锁被别人释放
- 锁超时无法续时间
第一个问题很好解决,在设置分布式锁时,在当前线程中生产一个UUID,将value设置为这个唯一值,然后在finally块里判断当前锁的value和自己设置的一样时再去执行delete,每个线程的uuid不一样,那么只会释放自己的。如下:
String uuid = UUID.randomUUID().toString();
try {
//原子的设置key及超时时间,锁唯一值
Boolean aTrue = stringRedisTemplate.opsForValue().setIfAbsent(lock_key,uuid,30,TimeUnit.SECONDS);
//...
} finally {
//是自己设置的锁再执行delete
if(uuid.equals(stringRedisTemplate.opsForValue().get(lock_key))){
stringRedisTemplate.delete(lock_key);//避免死锁
}
}还有没有问题呢?有!在finally块里判断锁是否是自己设置的,是的话再删除锁,这两步操作也不是原子的,假设刚判断完为true服务就挂了,那么删除锁的代码不会执行,就会造成死锁,即使是设置了过期时间,在没过期这段时间也会死锁。
所以这里也是一个注意的点,要保证原子操作的话,Redis提供了执行Lua脚本的功能来保证操作的原子性,具体怎么使用不再展开。
第二个问题怎么解决?
锁的超时时间就很关键了,不能太大也不能太小,这就需要评估业务代码的执行时间,比如设置个10秒,20秒。即使是你的锁设置了合适的超时时间,也避免不了可能会发生上述分析的因为某些原因代码没在正常评估的时间内执行完毕,所以这时候的解决方案就是给锁续超时时间。
大致思路就是:业务线程单独起一个分线程,每个业务线程配一个分线程,定时去监听业务线程设置的分布式锁是否还存在,存在就说明业务线程还没执行完,那么就延长锁的超时时间,若锁已不存在则业务线程执行完毕,然后就结束自己。
“锁续命”又叫“看门狗”,这套逻辑属实有点复杂啊,要考虑的问题太多了,稍不注意就会有bug。不要看上面实现分布式锁的代码没有几行,就认为实现起来很简单,如果说自己去实现的时候没有实际高并发的经验,肯定也会踩很多坑,例如上面已经说过的两个非原子的操作:
- 锁的设置和过期时间的设置是非原子操作的,就可能会导致死锁。
- 还有上面遗留的一个,在finally块里判断锁是否是自己设置的,是的话再删除锁,这两步操作也不是原子的,假设刚判断完为true服务就挂了,那么删除锁的代码不会执行,就会造成死锁,即使是设置了过期时间,在没过期这段时间也会死锁。所以这里也是一个注意的点,要保证原子操作的话,Redis提供了执行Lua脚本的功能来保证操作的原子性,具体怎么使用不再展开。
Redis提供了执行Lua脚本的功能来保证操作的原子性。所以,“锁续命”的这套逻辑实现起来还是有点复杂的,好在市面上已经有现成的开源框架帮我们实现了,那就是Redisson。
Redisson分布式锁的实现原理
- 首先Redisson会尝试进行加锁,加锁的原理也是使用类似Redis的setnx命令原子的加锁,加锁成功的话其内部会开启一个子线程
- 子线程主要负责监听,其实就是一个定时器,定时监听主线程是否还持有锁,持有则将锁的时间延时,否则结束线程
- 如果加锁失败则自旋不断尝试加锁
- 执行完代码主线程主动释放锁
那我们看一下使用后Redisson后的代码是什么样的。
①. 首先在pom.xml文件添加Redisson的maven坐标
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.5</version>
</dependency>②. 我们要拿到Redisson的这个对象,如下配置Bean
@SpringBootApplication
public class RedisLockApplication {
public static void main(String[] args) {
SpringApplication.run(RedisLockApplication.class, args);
}
@Bean
public Redisson redisson(){
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379")
.setDatabase(0);
return (Redisson) Redisson.create(config);
}
}③. 然后我们获取Redisson的实例,使用其API进行加锁释放锁操作
//假设库存编号是00001
private String key = "stock:00001";
private String lock_key = "lock_key:00001";
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 使用Redisson实现分布式锁
* @return
*/
@RequestMapping("/stock_redisson_lock")
public String stock_redisson_lock() {
RLock redissonLock = redisson.getLock(lock_key);
try {
redissonLock.lock();
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get(key));
if (stock > 0) {
int afterStock = stock - 1;
stringRedisTemplate.opsForValue().set(key, afterStock + "");
System.out.println("扣减库存成功,剩余库存" + afterStock);
} else {
System.out.println("扣减库存失败");
}
} catch (NumberFormatException e) {
e.printStackTrace();
} finally {
redissonLock.unlock();
}
return "ok";
}这个Redisson的分布式锁提供的API是不是非常的简单?
RLock redissonLock = redisson.getLock(lock_key);默认返回的是RedissonLock的对象,该对象实现了RLock接口,而RLock接口继承了JDK并发编程报包里的Lock接口

在使用Redisson加锁时,它也提供了很多API:

现在我们选择使用的是最简单的无参lock方法,简单的点进去跟一下看看他的源码:

我们可以看到其底层使用了Lua脚本来保证原子性,使用Redis的hash结构实现的加锁,以及可重入锁。
他实现的分布式锁是支持可重入的,也支持可等待,即尝试等待一定时间,没拿到锁就返回false。上述代码中的redissonLock.lock();是一直等待,内部自旋尝试加锁。
小结:
自己实现的redis分布式锁的话,需要特别注意四点:
- 原子加锁
- 设置锁超时时间
- 谁加的锁谁释放,且释放时的原子操作
- 锁续命问题。
如果使用现成的分布式锁框架Redisson,就需要熟悉一下其常用的API以及实现原理,或者选择其他开源的分布式锁框架,充分考察,选择适合自己业务需求的即可。
十三、redisCluster集群扩容与收缩
扩容
redis集群扩容那就是增加redis的主从节点,并且将cluster中的槽均分,提高redis的伸缩性,与redis集群的整体的容量。
redis集群扩容步骤:
(1)创建一对新的主从节点
(2)在某一个节点上做meet操作,使得整个集群的redis节点都认识这两个节点
(3)设置新增节点之间的主从关系
(4)使用redis-trib.rb reshard ip:port 来均分槽 (执行此命令之后根据提示向后执行)
以上四步就完成了集群的扩容。具体的,可以通过ruby工具 或 自带命令 来完成。
方式一:ruby工具
1、创建新的节点
mkdir -p /opt/redis_{6390,6391}/{conf,logs,pid}
mkdir -p /data/redis_{6390,6391}
cd /opt/
cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf
redis-server /opt/redis_6390/conf/redis_6390.conf
redis-server /opt/redis_6391/conf/redis_6391.conf
ps -ef|grep redis2、将新的主节点加入集群
redis-trib.rb add-node 10.0.0.51:6390 10.0.0.51:6380
# 将新的节点添加到6380所在集群3、转移slot(重新分片)
redis-trib.rb reshard 10.0.0.51:63804、将从节点加入集群
redis-trib.rb add-node --slave --master-id 881a713dcd1569a2426a69038f76e9718884e227 10.0.0.516391 10.0.0.51:6380
# 添加从节点 主节点id 方式二:利用自带命令
1、创建新的节点
mkdir -p /opt/redis_{6390,6391}/{conf,logs,pid}
mkdir -p /data/redis_{6390,6391}
cd /opt/
cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf
redis-server /opt/redis_6390/conf/redis_6390.conf
redis-server /opt/redis_6391/conf/redis_6391.conf
ps -ef|grep redis2、将新添加的节点加入到集群
redis-cli -c -h 10.0.0.51 -p 6380 cluster meet 10.0.0.51 6390
redis-cli -c -h 10.0.0.51 -p 6380 cluster meet 10.0.0.51 6391
redis-cli -c -h 10.0.0.51 -p 6380 cluster nodes3、扩容(重新分配槽位)
redis-cli --cluster reshard 10.0.0.51:6380
4、手动添加复制关系(主从关系)
缩容
redis缩容步骤:
(1)迁移下线master上的槽 使用redis-trib.rb reshard命令
(2)让其他节点忘记该节点,先忘记从节点,再忘记master节点 使用redis-trib del-node命令
忘记节点需要每个节点都去执行忘记命令,但是redis-trib del-node帮助我们完成了全部的遍历工作


比如有12个槽数 删除节点前有四个master 平均分配槽数是3。现在删除一个master节点,需要把一个槽分别给还存在的节点。计算方法为: 要删除的节点槽数 / 还存在的节点数量
十四、Redis分区
将数据拆分到多个Redis实例中,每个(部分)实例仅包含所有key的一个子集。
好处:
- 1、性能的提升,单机Redis的网络I/O能力和计算资源是有限的,将请求分散到多台机器,充分利用多台机器的计算能力可网络带宽,有助于提高Redis总体的服务能力。
- 2、存储的横向扩展,即使Redis的服务能力能够满足应用需求,但是随着存储数据的增加,单台机器受限于机器本身的存储容量,将数据分散到多台机器上存储使得Redis服务可以横向扩展。
总的来说,分区使得我们本来受限于单台计算机硬件资源的问题不再是问题,存储不够?计算资源不够?带宽不够?我们都可以通过增加机器来解决这些问题。
坏处:
- 1、多键操作是不被支持的,比如我们将要批量操作的键被映射到了不同的Redis实例中。
- 2、多键的Redis事务是不被支持的。
- 3、分区的最小粒度是键,因此我们不能将关联到一个键的很大的数据集映射到不同的实例。
- 4、当应用分区的时候,数据的处理是非常复杂的,比如我们需要处理多个rdb/aof文件,将分布在不同实例的文件聚集到一起备份。
- 5、添加和删除机器是很复杂的,例如Redis集群支持几乎运行时透明的因为增加或减少机器而需要做的rebalancing,然而像客户端和代理分区这种方式是不支持这种功能的。
实现方式
实现方式-1、客户端实现
即key在redis客户端就决定了要被存储在那台Redis实例中。

实现方式-2、代理实现
代理实现即客户端将请求发往代理服务器,代理服务器实现了Redis协议,因此代理服务器可以代理客户端和Redis服务器通信。代理服务器通过配置的分区schema来将客户端的请求转发到正确的Redis实例中,同时将反馈消息返回给客户端。

实现方式-3、查询路由
查询路由是Redis Cluster实现的一种Redis分区方式。

补充 - 1:redis的通信协议
redis的通信协议是Redis Serialization Protocol,简称RESP,有如下特性:
- 是二进制安全的
- 使用TCP
- 基于请求-响应的模式
需注意的是:RESP是redis客户端和服务端通信的协议,节点交互不使用这个协议。
补充 - 2:什么是缓存穿透?什么是缓存雪崩?何如避免?Redis 的热 key 问题怎么解决?
1、缓存穿透:
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
如何避免?
- 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
- 对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
2、缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
产生雪崩的原因之一,比如马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
如何避免?
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
- 不同的key,缓存失效时间加入随机因子,尽量让失效时间点均匀分布,设置不同的过期时间。
3、热 key 问题
热 key 就是说,在某一时刻,有非常多的请求访问某个 key,流量过大,导致该 redi 服务器宕机

解决方案:
- 可以将结果缓存到本地内存中
- 将热 key 分散到不同的服务器中
- 设置永不过期
补充 - 3:热点数据 和 冷数据 是什么
热数据:是需要被计算节点频繁访问的在线类数据。
冷数据:是对于离线类不经常访问的数据,比如企业备份数据、业务与操作日志数据、话单与统计数据。
热数据就近计算,冷数据集中存储。热数据因为访问频次需求大,效率要求高,所以就近计算和部署;冷数据访问频次低,效率要求慢,可以做集中化部署,而基于大规模存储池里,可以对数据进行压缩、去重等降低成本的方法。
从数据分析的层面来看,不仅有冷热两种数据,还有温数据。而提出这个概念的是个灯,个灯是这么介绍的:
- 冷数据——性别、兴趣、常住地、职业、年龄等数据画像,表征“这是什么样的人”;
- 温数据——近期活跃应用、近期去过的地方等具有一定时效性的行为数据,表征“最近对什么感兴趣”;
- 热数据——当前地点、打开的应用等场景化明显的、稍纵即逝的营销机会,表征“正在哪里干什么”
为了处理冷热数据识别与交换,阿里云自主研发了Redis混合存储产品,是的完全兼容Redis协议和特性的混合存储产品。通过将部分冷数据存储到磁盘,在保证绝大部分访问性能不下降的基础上,大大降低了用户成本并突破了内存对Redis单实例数据量的限制。
Redis混合存储实例将所有的Key都认为是热数据,以少量的内存为代价保证所有Key的访问请求的性能是高效且一致的。而对于Value部分,在内存不足的情况下,实例本身会根据最近访问时间,访问频度,Value大小等维度选取出部分value作为冷数据后台异步存储到磁盘上直到内存小于制定阈值为止。
在Redis混合存储实例中,我们将所有的Key都认为是热数据保存在内存中是出于以下两点考虑:
1、Key的访问频度比Value要高很多。
作为KV数据库,通常的访问请求都需要先查找Key确认Key是否存在,而要确认一个key不存在,就需要以某种形式检查所有Key的集合。在内存中保留所有Key,可以保证key的查找速度与纯内存版完全一致。
2、Key的大小占比很低。
即使是普通字符串类型,通常的业务模型里面Value比Key要大几倍。而对于Set,List,Hash等集合对象,所有成员加起来组成的Value更是比Key大了好几个数量级。
因此,Redis混合存储实例的适用场景主要有以下两种:
- 数据访问不均匀,存在热点数据;
- 内存不足以放下所有数据,且Value较大(相对于Key而言)
冷热数据识别:
当内存不足时的情况下,实例会按照最近访问时间,访问频度,value大小等维度计算出value的权重,将权重最低的value存储到磁盘上并从内存中删除。
补充 - 4:为什么Redis是单线程的,优势
Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
具体的原因:
1)不需要各种锁的性能消耗
在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2)CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
Redis单线程的优劣势
1.单进程单线程优势
- 代码更清晰,处理逻辑更简单
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 不存在多进程或者多线程导致的切换而消耗CPU
2.单进程单线程弊端
- 无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善;
以上也是Redis能够支持高并发的原因。
补充 - 5:如何解决redis的并发竞争key问题?
这个问题大致就是,同时有多个子系统去set一个key。
方案:
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下:
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。
补充 - 6:如何保证Redis与数据库的数据一致性?
一般来说,只要你用到了缓存,不管是Redis还是memcache,就可能会涉及到数据库缓存与数据的一致性问题。
首先考虑清楚一点:那就是到底是更新DB还是更新缓存更合适?这个很关键,目前来讲更新缓存是一件赔本买卖,原因是:
- 大多数情况下,redis缓存中的数据并不是完全copy db中的数据,而是将db中多张表的数据进行了重新计算,筛选后更新到redis。如果在db某一张表的数据发生了变化的情况下,需要同步重新计算redis中的值,成本过高。
- 缓存更新后的新值,无法保证一定会有读请求命中,如果一直没有请求命中该部分冷数据,其实是产生了一定的资源浪费(计算成本+存储成本)。
所以首先的出的结论就是:最好不要更新缓存,因为代价高昂,能删除则删除。
那么删除缓存和更新DB谁先谁后呢?首先想到的可能就是:
- 更新的时候,先更新数据库,然后再删除缓存;
- 读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应。
但这样会有一个问题:若先更新了数据库,删除缓存的时候失败了怎么办?那么数据库中是新数据,缓存中是老数据,数据出现就出现了不一致。那么先删除缓存,后更新数据库呢,因为即使后面更新数据库失败了,缓存是空的,读的时候会从数据库中重新拉,虽然都是旧数据,但数据是一致的,即:
- 更新的时候,先删除缓存,然后再更新数据库。
- 读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应。
到这里是不是问题就得到了彻底的解决了呢?其实并没有,在高并发的场景下,会出现这样的情况:数据发生了变更,先删除了缓存,然后去修改数据库。此时还没来得及修改,一个请求过来了,去读缓存,发现缓存空了,去读数据库,读到了准备修改前的旧数据,并且把旧数据放到了缓存。随后,数据变更程序完成了数据库的修改。那么现在数据又不一致了。
所以有了下面几种方案:
(1)串行队列方案:
可以先把“修改DB”的操作放到一个JVM队列,后面读请求过来之后,“更新缓存”的操作也放进同一个JVM队列,每个队列,对于一个作业线程,按照队列的顺序,依次执行相关操作。也就是通过队列使得“修改DB”一定是在“更新缓存”之前。当然这个方案还可以优化:
- 读请求过多的时候,队列里面会有多个“更新缓存”操作串在一起,其实是没有意义的,往队列里面塞数据的时候可以先判断一下,有的话就不用再塞进去
- 遇到更新DB比较频繁的业务场景时,可能会导致读请求长时间阻塞,这个时候可以通过扩机器增加吞吐量,或者可以先返回一个旧的值。
(2)延时双删策略:
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。伪代码:
public void write( String key, Object data )
{
redis.delKey( key );
db.updateData( data );
Thread.sleep( );
redis.delKey( key );
}步骤:
- 先删除缓存
- 再写数据库
- 休眠500毫秒
- 再次删除缓存
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
实际过程:
- A请求进行写操作,先淘汰缓存
- B请求进行读操作,由于A请求已将缓存淘汰,B请求没有在redis中发现所需数据,因此从数据库中读取数据,并更新缓存到redis中。注意,此时redis中被更新的依然是老数据,A请求的数据库更新操作尚未完成。假设该步骤耗时N秒
- A请求进行数据库更新操作。
- 由于此时redis中写入了老数据,因此A请求在休眠M秒后(M略大于N),再次对redis进行淘汰缓存操作
- 该方案虽然解决了数据不一致的问题,但是由于请求A在更新完数据库之后,需要休眠M秒再次淘汰缓存,一定程度上影响了数据更新操作的吞吐量。可以尝试将等待M秒更新redis的操作放到另一个单独的线程(比如消息队列 + 重试机制)。可以有效缓解吞吐量降低的问题。
(3)异步更新缓存(基于订阅binlog的同步机制)
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis。
流程:
- 更新数据库数据;
- 数据库会将操作信息写入binlog日志当中;
- 订阅程序提取出所需要的数据以及key;
- 另起一段非业务代码,获得该信息;
- 尝试删除缓存操作,发现删除失败;
- 将这些信息发送至消息队列;
- 重新从消息队列中获得该数据,重试操作;
一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。上述的订阅binlog程序在mysql中有现成的中间件叫canal(阿里的一款开源框架)通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果,可以完成订阅binlog日志的功能,也可以使用定时任务等去控制删除失败重试次数、时间、频率。
总结:
一般来说,若不是系统需要严格要求缓存和数据库必须一致的话,缓存可以允许稍微的跟数据库偶尔有不一致的情况,上面的更新DB和更新缓存的串行话可以防止不一致的产生,但是串行后系统的吞吐量就会大幅降低,需要比正常情况下多几倍的机器去支持。
补充 - 7:redis为什么这么快?
官方数据 redis 可以做到每秒近10w的并发,这么快的原因主要总结为以下几点:
- 1:完全基于内存操作
- 2:使用单线程模型来处理客户端的请求,避免了上下文的切换
- 3:IO 多路复用机制
- 4:自身使用 C 语言编写,有很多优化机制,比如动态字符串 sds
补充 - 8:听说 redis 6.0之后又使用了多线程,不会有线程安全的问题吗?
不会
其实 redis 还是使用单线程模型来处理客户端的请求,只是使用多线程来处理数据的读写和协议解析,执行命令还是使用单线程,所以是不会有线程安全的问题。
之所以加入了多线程因为 redis 的性能瓶颈在于网络IO而非CPU,使用多线程能提升IO读写的效率,从而整体提高redis的性能。
补充 - 9:cluster集群模式是怎么存放数据的?
一个cluster集群中总共有16384个节点,集群会将这16384个节点平均分配给每个节点,当然,我这里的节点指的是每个主节点,就如同下图:

补充 - 10:cluster的故障恢复是怎么做的?
判断故障的逻辑其实与哨兵模式有点类似,在集群中,每个节点都会定期的向其他节点发送ping命令,通过有没有收到回复来判断其他节点是否已经下线。
如果长时间没有回复,那么发起ping命令的节点就会认为目标节点疑似下线,也可以和哨兵一样称作主观下线,当然也需要集群中一定数量的节点都认为该节点下线才可以,我们来说说具体过程:

- 当A节点发现目标节点疑似下线,就会向集群中的其他节点散播消息,其他节点就会向目标节点发送命令,判断目标节点是否下线
- 如果集群中半数以上的节点都认为目标节点下线,就会对目标节点标记为下线,从而告诉其他节点,让目标节点在整个集群中都下线
补充 - 11:主从同步原理是怎样的?
- 1.当一个从数据库启动时,它会向主数据库发送一个SYNC命令,master收到后,在后台保存快照,也就是我们说的RDB持久化,当然保存快照是需要消耗时间的,并且redis是单线程的,在保存快照期间redis受到的命令会缓存起来
- 2.快照完成后会将缓存的命令以及快照一起打包发给slave节点,从而保证主从数据库的一致性。
- 3.从数据库接受到快照以及缓存的命令后会将这部分数据写入到硬盘上的临时文件当中,写入完成后会用这份文件去替换掉RDB快照文件,当然,这个操作是不会阻塞的,可以继续接受命令执行,具体原因其实就是fork了一个子进程,用子进程去完成了这些功能。
因为不会阻塞,所以,这部分初始化完成后,当主数据库执行了改变数据的命令后,会异步地给slave,这也就是我们说的复制同步阶段,这个阶段会贯穿在整个主从同步的过程中,直到主从同步结束后,复制同步才会终止。
补充 - 12:无硬盘复制是什么?
主从之间是通过RDB快照来交互的,虽然看来逻辑很简单,但是还是会存在一些问题,但是会存在着一些问题。
- 1.master禁用了RDB快照时,发生了主从同步(复制初始化)操作,也会生成RDB快照,但是之后如果master发成了重启,就会用RDB快照去恢复数据,这份数据可能已经很久了,中间就会丢失数据
- 2.在这种一主多从的结构中,master每次和slave同步数据都要进行一次快照,从而在硬盘中生成RDB文件,会影响性能
为了解决这种问题,redis在后续的更新中也加入了无硬盘复制功能,也就是说直接通过网络发送给slave,避免了和硬盘交互,但是也是有io消耗的
补充 - 13:redis的key的过期时间和永久有效怎么设置?
EXPIRE 和 PERSIST 命令。
补充 - 14:redis集群最大节点个数?Hash槽是什么概念?
16384个。其中,主节点数量基本不可能超过1000个
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value
时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,
这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大
致均等的将哈希槽映射到不同的节点。
好处:
- 使用哈希槽的好处就在于可以方便的添加或移除节点。
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了;
Redis没有使用一致性Hash算法,而是用了哈希槽的概念,而没有用一致性哈希算法,不都是哈希么?这样做的原因是为什么呢?
Redis的作者认为它的crc16(key) mod 16384的效果已经不错了,虽然没有一致性hash灵活,但实现很简单,节点增删时处理起来也很方便。一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据分布。而Redis Cluster的槽位空间是自定义分配的,类似于Windows盘分区的概念。这种分区是可以自定义大小,自定义位置的。另外,一致性哈希算法也有一个严重的问题,就是数据倾斜。
补充 - 15:Redis的管道机制是啥?
pipeline出现的背景:
redis客户端执行一条命令分4个过程:
客户端发送命令-〉命令排队-〉命令执行-〉返回结果到客户端
这个过程称为Round trip time(简称RTT, 往返时间),在计算机网络中它是一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。普通的请求模型不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题。
Redis提供了一个称为管道(Pipeline) 的机制将一组Redis命令进行组装,通过一次 RTT 传输给 Redis,再将这些 Redis 命令的执行结果按顺序传递给客户端。即使用pipeline执行了n次命令,整个过程就只需要一次 RTT。
底层避免了用户态切换到内核态。
使用举例:
SpringDataRedis提供了executePipelined方法对管道进行支持。 下面是一个Redis队列的操作,放到了管道中进行操作。
@RunWith(SpringRunner.class)
@SpringBootTest
@Slf4j
public class RedisPipeliningTests {
@Autowired
private RedisTemplate<String, String> redisTemplate;
private static final String RLIST = "test_redis_list";
@Test
public void test() {
Instant beginTime2 = Instant.now();
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < (10 * 10000); i++) {
connection.lPush(RLIST.getBytes(), (i + "").getBytes());
}
for (int i = 0; i < (10 * 10000); i++) {
connection.rPop(RLIST.getBytes());
}
return null;
}
});
log.info(" ***************** pipeling time duration : {}", Duration.between(beginTime2, Instant.now()).getSeconds());
}
}注意executePipelined中的doInRedis方法返回总为null。
使用管道技术的注意事项
当你要进行频繁的Redis请求的时候,为了达到最佳性能,降低RTT,你应该使用管道技术。
但如果通过管道发送了太多请求,也会造成Redis的CPU使用率过高。当管道中累计了大量请求以后,CUP使用率迅速升到了100%,这是非常危险的操作。
对于监听队列的场景,一个简单的做法是当发现队列返回的内容为空的时候,就让线程休眠几秒钟,等队列中累积了一定量数据以后再通过管道去取,这样就既能享受管道带来的高性能,又避免了CPU使用率过高的风险。
补充 - 16:redis如何做大量数据插入?
有时,Redis实例需要装载大量用户在短时间内产生的数据,数以百万计的keys需要被快速的创建。即大量数据插入(mass insertion)。
使用正常模式的Redis客户端执行大量数据插入是不明智的:因为一个个的插入会有大量的时间浪费在每一个命令往返时间上。
使用管道(pipelining)还比较靠谱,但是在大量插入数据的同时又需要执行其他新命令时,这时读取数据的同时需要确保尽可能快的写入数据。
Redis 2.6 开始 redis - cli 支持一种新的被称之为 pipe mode 的新模式用于执行大量数据插入工作。
使用pipe mode模式的执行命令如下:
cat data.txt | redis-cli --pipe 1、未使用pipeline执行N条命令

2、使用了pipeline执行N条命令

使用Pipeline执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显。
补充 - 17、redis从海量的key里面查询出某一固定前缀的key
语法scan cursor [MATCH pattern] [COUNT count]
- 基于游标的迭代器,需要基于上一次游标延续之前的迭代过程
- 以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历
- 不保证每次执行都会返回某个给定数量的元素,支持模糊查询
- 一次返回的数量不可控,只能是大概率符合count参数
127.0.0.1:6380> scan 0 match k1* count 10
1) "655360"
2) 1) "k1864385"
2) "k1392840"
3) "k1388130"
4) "k1357007"
5) "k1743332"
6) "k1593973"
7) "k1399047"
127.0.0.1:6380> scan 655360 match k1* count 10
1) "327680"
2) 1) "k1610178"
2) "k1693505"
3) "k1032175"
4) "k1721788"
5) "k1678140"
6) "k1359412"
127.0.0.1:6380> scan 327680 match k1* count 10
1) "2031616"
2) 1) "k1798037"
2) "k1805785"
3) "k1837836"
4) "k1138914"
5) "k1689917"
6) "k1033258"例如:SCAN 0 MATCH aaa* COUNT 5 表示从游标0开始查询aaa开头的key,每次返回5条,但是这个5条不一定,只是给Redis打了个招呼,具体返回数量看Redis心情。
补充 - 18、redis如何实现异步队列?
我们知道redis支持很多种结构的数据,一般使用Redis的list结构类型作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
如果追问能不能不用sleep呢?
list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果追问能不能生产一次消费多次呢?
使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
如果追问pub/sub有什么缺点?
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如RabbitMQ等。
原因是消息的发布是无状态的,无法保证可达,若订阅者在发送者发布消息期间下线,之后我们再上线将无法接受到刚才发送的消息,解决办法就是使用专业的消息队列。
补充 - 19、redis如何实现延时队列?
延迟队列的使用场景
1、 当分布式锁加锁失败时,将消息放入到延迟队列中处理
2、订餐通知:下单成功后60s之后给用户发送短信通知
3、在订单系统中,一个用户某个时刻下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单需要关闭
Redis实现延迟队列的基本原理
对于在延时任务检测器内部的话,有查询延迟任务和执行延时任务两个职能,任务检测器会先去延时任务队列进行队列中信息读取,判断当前队列中哪些任务已经时间到期并将已经到期的任务输出执行(设置一个定时任务)。
在Redis的数据结构中有哪些能进行时间设置标志的命令?
可以使用 zset(sortedset)这个命令,用设置好的时间戳作为score进行排序,使用 zadd score1 value1 ....命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。也可以通过 zrangebyscore key min max withscores limit 0 1 查询最早的一条任务,来进行消费。
生产者将数据放入到list队列中(调用delay函数),最关键的是利用redis的zset数据结构
jedis.zadd(queueKey,System.currentTimeMillis()+10000,s);
zadd的第二个参数是score值,这里是用当前的时间戳加上想要延迟的秒数来作为score值,第三个参数是value值
消费者多线程轮询 zset 获取到期的任务进行处理
Set values=jedis.zrangeByScore(queueKey,0,System.currentTimeMillis(),0,1);
zrangeByScore(String key, double min, double max, int offset, int count)这个函数可以看出是获取0秒到当前时间戳的数据的一条数据进行处理,这里offset是0,count 是1,表示按照分数大小从小到大进行消费。
Redis用来进行实现延时队列是具有这些优势的:
- Redis zset支持高性能的 score 排序。
- Redis是在内存上进行操作的,速度非常快。
- Redis可以搭建集群,当消息很多时候,我们可以用集群来提高消息处理的速度,提高可用性。
- Redis具有持久化机制,当出现故障的时候,可以通过AOF和RDB方式来对数据进行恢复,保证了数据的可靠性
补充 - 20、Redis官方为什么不提供Windows版本?
因为redis 是单线程高性能的。所以redis需要单线程轮询操作系统机制的轮询是不太一样的。
简而言之 linxu轮询用epoll,window 用selector。但是性能上来说 epoll是高于selector 的。
所以redis推荐使用linux版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号