spring cloud 专辑(全面梳理、实际代码、常见问题总结)
- 目录
三、Spring Cloud和Dubbo的区别及各自的优缺点
5.6 Eureka自我保护模式 和 InstanceID 的配置
8.3 使用Hystrix Dashboard(熔断仪表盘)查看监控数据
补充十、为什么有人说 Eureka 比 Zookeeper 更适合作为注册中心呢?
补充十、application.yml和bootstrap.yml的区别
整理这篇文章花了差不多一个月的时间,虽然耗费的时间较长,白天还得搬砖,但通过自己动手把各组件操作一遍,对相关概念、相关组件功能、相关配置含义等都有了更深入的理解,很有收获。
本文所有实例代码下载地址: https://github.com/ImOk520/myspringcloud
一、什么是微服务?什么是微服务架构?
“微服务”一词来源于 Martin Fowler 的《Microservices》一文。微服务是一种架构风格,即将单体应用划分为小型的服务单元,微服务之间使用 HTTP 的 API 进行资源访问与操作。
微服务架构就是将单体的应用程序分成多个应用程序,这多个应用程序就成为微服务,每个微服务运行在自己的进程中,并使用轻量级的机制通信。这些服务围绕业务能力来划分,每个服务只干一件事,并通过自动化部署机制来独立部署。这些服务可以使用不同的编程语言,不同数据库,以保证最低限度的集中式管理。
使用微服务架构能够为我们带来如下好处:
- 1)服务的独立部署:每个服务都是一个独立的项目,可以独立部署,不依赖于其他服务,耦合性低。
- 2)服务的快速启动:拆分之后服务启动的速度必然要比拆分之前快很多,因为依赖的库少了,代码量也少了。
- 3)更加适合敏捷开发:敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行。服务拆分可以快速发布新版本,修改哪个服务只需要发布对应的服务即可,不用整体重新发布。
- 4)职责专一,由专门的团队负责专门的服务:业务发展迅速时,研发人员也会越来越多,每个团队可以负责对应的业务线,服务的拆分有利于团队之间的分工。
- 5)服务可以动态按需扩容:当某个服务的访问量较大时,我们只需要将这个服务扩容即可。
- 6)代码的复用:每个服务都提供 REST API,所有的基础服务都必须抽出来,很多的底层实现都可以以接口方式提供。
微服务其实是一把双刃剑,既然有利必然也会有弊:
- 1)分布式部署,调用的复杂性高:单体应用的时候,所有模块之前的调用都是在本地进行的,在微服务中,每个模块都是独立部署的,通过 HTTP 来进行通信,这当中会产生很多问题,比如网络问题、容错问题、调用关系等。
- 2)独立的数据库,分布式事务的挑战:每个微服务都有自己的数据库,这就是所谓的去中心化的数据管理。这种模式的优点在于不同的服务,可以选择适合自身业务的数据,比如订单服务可以用 MySQL、评论服务可以用 Mongodb、商品搜索服务可以用 Elasticsearch。缺点就是事务的问题了,目前最理想的解决方案就是柔性事务中的最终一致性。
- 3)测试的难度提升:服务和服务之间通过接口来交互,当接口有改变的时候,对所有的调用方都是有影响的,这时自动化测试就显得非常重要了,如果要靠人工一个个接口去测试,工作量就太大了。这里要强调一点,就是 API 文档管理尤为重要。
- 4)运维难度的提升:在采用传统的单体应用时,我们可能只需要关注一个 Tomcat 的集群、一个 MySQL 的集群就可以了,但这在微服务架构下是行不通的。当业务增加时,服务也将越来越多,服务的部署、监控将变得非常复杂,这个时候对于运维的要求就高了。
二、什么是springcloud?
Spring Cloud是一系列框架的集合,是一套综合微服务解决方案。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。通俗的讲:Spring Cloud 就是用于构建微服务开发和治理的框架集合(并不是具体的一个框架)。
三、Spring Cloud和Dubbo的区别及各自的优缺点
Dubbo 的定位始终是一款 RPC 框架,而 Spring Cloud 的目标是微服务架构下的一站式解决方案。
Spring Cloud 抛弃了 Dubbo 的 RPC 通信,采用的是基于 HTTP 的 REST 方式。 RPC 调用使得服务提供方与调用方在代码上产生了强依赖,服务提供方需要不断将包含公共代码的 Jar 包打包出来供消费方使用。一旦打包出现问题,就会导致服务调用出错。REST 相比 RPC 更为灵活,服务提供方和调用方,不存在代码级别的强依赖,这在强调快速演化的微服务环境下显得更加合适。
另外,2012年开始,Dubbo停止更新了5年,给了spring cloud足够长的发展时间。
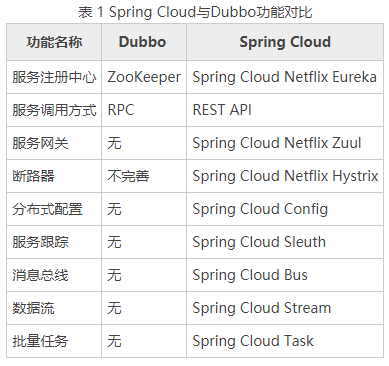
另外, Spring Cloud与Dubbo功能上差别很大, Spring Cloud功能更全面强大,涵盖面更广。而且它也能够与 Spring Framework、Spring Boot、Spring Data、Spring Batch 等其他 Spring 项目完美融合,这些对于微服务而言是至关重要的。微服务背后一个重要的理念就是持续集成、快速交付,而在服务内部使用一个统一的技术框架,显然比像Dubbo那样将分散的技术组合到一起更有效率。
有个形象的比喻:Spring cloud和Dubbo就是品牌机和组装机的区别,你细品。
四、Spring Boot 简介
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是简化新 Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式进行配置,从而使开发人员不再需要定义样板化的配置。
Spring Boot 致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。在使用 Spring Boot 之前,我们需要搭建一个项目框架并配置各种第三方库的依赖,还需要在 XML 中配置很多内容。Spring Boot 完全打破了我们之前的使用习惯,一分钟就可以创建一个 Web 开发的项目;通过 Starter 的方式轻松集成第三方的框架;去掉了 XML 的配置,全部用注解代替。
Spring Boot Starter 是用来简化 jar 包依赖的,集成一个框架只需要引入一个 Starter,然后在属性文件中配置一些值,整个集成的过程就结束了。Spring Boot 在内部做了很多的处理,让开发人员使用起来更加简单了。
使用 Spring Boot 开发的优点:
- 基于 Spring 开发 Web 应用更加容易。
- 采用基于注解方式的配置,避免了编写大量重复的 XML 配置。
- 可以轻松集成 Spring 家族的其他框架,比如 Spring JDBC、Spring Data 等。
- 提供嵌入式服务器,令开发和部署都变得非常方便。
五、Eureka是什么?
Eureka 是 Spring Cloud Netflix 微服务套件的一部分,基于 Netflix Eureka 做了二次封装,主要负责实现微服务架构中的服务治理功能。Eureka 是一个基于 REST 的服务,并且提供了基于 Java 的客户端组件,能够非常方便地将服务注册到 Spring Cloud Eureka 中进行统一管理。
服务治理是微服务架构中必不可少的一部分,阿里开源的 Dubbo 框架就是针对服务治理的。服务治理必须要有一个注册中心,除了用 Eureka 作为注册中心外,我们还可以使用 Consul、Etcd、Zookeeper 等来作为服务的注册中心。
5.1 搭建Eureka服务注册中心
spring cloud几个组件的集成过程实际很类似,都是先添加依赖、增加相应配置、启动类增加@EnableXXX注解。
实例代码下载地址: GitHub - ImOk520/myspringcloud

首先创建一个 Maven 项目,取名为 my-eureka,在 pom.xml 中配置 Eureka 的依赖信息:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-eureka-server</artifactId>
</dependency>接下来在 src/main/resources 下面创建一个 application.yml 配置文件,增加下面的配置:
server:
port: 9000
spring:
application:
name: my-eureka
eureka:
instance:
hostname: localhost
client:
register-with-eureka: false # 不注册自己
fetch-registry: false # 注册中心的职责就是维护服务实例,它不需要去检索服务,服务检索关闭
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/这里eureka.client.register-with-eureka 一定要配置为 false,不然启动时会把自己当作客户端向自己注册,会报错。
创建一个启动类 MyEurekaApplication ,并添加@EnableEurekaServer注解启动组件:
@EnableEurekaServer
@SpringBootApplication
public class MyEurekaApplication {
public static void main(String[] args) {
SpringApplication.run(MyEurekaApplication.class, args);
}
}接下来直接运行 MyEurekaApplication 就可以启动我们的注册中心服务了。我们在 application.yml配置的端口是 9000,则可以直接通过 http://localhost:9000/ 去浏览器中访问,然后便会看到 Eureka 提供的 Web 控制台。

5.2 编写服务提供者

1)创建项目注册到 Eureka
注册中心已经创建并且启动好了,接下来我们实现将一个服务提供者provider-A 注册到 Eureka 中,并提供一个接口给其他服务调用。首先还是创建一个 Maven 项目,然后在 pom.xml 中增加相关依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>配置文件中配置如下:
server:
port: 8001
spring:
application:
name: provider
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: org.gjt.mm.mysql.Driver
url: jdbc:mysql://localhost:3306/db01?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/ # eureka注册中心服务地址创建一个启动类 App,代码如下所示:
@EnableEurekaClient
@SpringBootApplication
public class ProviderA {
public static void main(String[] args) {
SpringApplication.run(ProviderA.class, args);
}
}
@EnableDiscoveryClient,表示当前服务是一个 Eureka 的客户端并激活。
接下来在 src/main/resources 下面创建一个 application.yml属性文件,增加下面的配置:
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/ # eureka注册中心服务地址eureka.client.serviceUrl.defaultZone 的地址就是我们之前启动的 Eureka 注册中心服务的地址,在启动的时候需要将自身的信息注册到 Eureka 中去。执行 App 启动服务,我们可以看到控制台中有输出注册信息的日志:

回到之前打开的 Eureka 的 Web 控制台,刷新页面,就可以看到新注册的服务信息了:

这时服务已经起来了,我们在这里写一个Controller层接口来给其他服务调用:
@RestController
@RequestMapping("/dept")
public class DeptController {
@Autowired
private DeptService deptService;
@PostMapping("/add")
public boolean add(@RequestBody Dept dept){
return deptService.addDept(dept);
}
@GetMapping("/getById/{deptno}")
public Dept getById(@PathVariable("deptno") Long deptno){
return deptService.queryById(deptno);
}
@GetMapping("/getAll")
public List<Dept> getAll(){
return deptService.queryAll();
}
}5.3 编写服务消费者
ok,我们再新建一个消费者服务:

服务调用可以分为两种: RestTemplate直接调用服务和通过Eureka注册中心调用服务。
1)直接调用接口
RestTemplate 是 Spring 提供的用于访问 Rest 服务的客户端,RestTemplate 提供了多种便捷访问远程 Http 服务的方法,能够大大提高客户端的编写效率,RestTemplate 来调用接口代码如下:
@Slf4j
@RequestMapping("/rest-template")
@RestController
public class ConsumerController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/getForObjectList")
public List<Dept> getForObjectList() {
String url = "http://localhost:8001/dept/getAll";
List<Dept> forObject = restTemplate.getForObject(url, List.class);
log.info("list:{}", forObject);
return forObject;
}
}
这种调用是不用通过注册中心的,而是服务间的直接调用,因此这里写的地址是:"http://localhost:8001/dept/getAll",即是通过IP+Port的方式。这样调用实际是有弊端的,即不能实现负载均衡,你想假如provider服务有多个实例这种方式也只能调用其中一个,而不能通过负载均衡算法实现动态选择。
2)通过 Eureka 来消费接口
上面提到的方法是直接通过服务接口的地址来调用的,和我们之前的做法一样,完全没有用到 Eureka 带给我们的便利。
我们想要通过服务名称来调用那就需要将上面的RestTemplate调用的地址改成服务提供者的服务名,这里用provider服务名替换了localhost:8001:
@GetMapping("/getForObjectList")
public List<Dept> getForObjectList() {
String url = "http://provider/dept/getAll";
List<Dept> forObject = restTemplate.getForObject(url, List.class);
log.info("list:{}", forObject);
return forObject;
}但是这里需要 RestTemplate 的配置,添加一个 @LoadBalanced 注解,这个注解会自动构造 LoadBalancerClient 接口的实现类并注册到 Spring 容器中,从注册中心获取服务列表实现负载均衡:

结果和 RestTemplate 直接调用接口一样。
5.4 Eureka注册中心开启密码认证
Eureka 自带了一个 Web 的管理页面,方便我们查询注册到上面的实例信息,但是有一个问题:如果在实际使用中,注册中心地址有公网 IP 的话,必然能直接访问到,这样是不安全的。所以我们需要对 Eureka 进行改造,加上权限认证来保证安全性。
通过集成 Spring-Security 来进行安全认证。在 pom.xml 中添加 Spring-Security 的依赖包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>然后在 application.yml中加上认证的配置信息:
spring:
security: # eureka管理后台安全认证
user:
name: ImOK #用户名
password: 123456 #密码 增加 Security 配置类:
@Configuration
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
// 关闭csrf
http.csrf().disable();
// 支持httpBasic
http.authorizeRequests().anyRequest().authenticated().and().httpBasic();
}
}重新启动注册中心,访问时浏览器会提示你输入用户名和密码,输入正确后才能继续访问 Eureka 提供的管理页面。

在 Eureka 开启认证后,客户端注册的配置也要加上认证的用户名和密码信息:
eureka.client.serviceUrl.defaultZone=http://ImOK:123456@localhost:8761/eureka/5.5 Eureka集群——实现高可用服务注册中心
前面我们搭建的注册中心只适合本地开发使用,在生产环境中必须搭建一个集群来保证高可用。Eureka 的集群搭建方法很简单:每一台 Eureka 只需要在配置中指定另外多个 Eureka 的地址就可以实现一个集群的搭建了。
搭建步骤
首先因为是集群,我们先把hosts文件改一下,这样在本机去模拟一下多服务器的集群(当然也是为了在配置文件中显示出差异,并且也是为了在Eureka管理后台的DS Replicas展示),hosts文件修改如下:

再新建三个eureka服务:my-eureka、 my-eureka-another、my-eureka-another-two

三个eureka注册中心其他都可以保持一致,需要修改的就是配置文件,以其中一个my-eureka服务为例,配置如下:
server:
port: 9000
spring:
application:
name: my-eureka
security: # eureka管理后台安全认证
user:
name: ImOK #用户名
password: 123456 #密码
eureka:
instance:
hostname: configserver-1.com
client:
register-with-eureka: false # 不注册自己
fetch-registry: false # 注册中心的职责就是维护服务实例,它不需要去检索服务,服务检索关闭
service-url:
defaultZone: http://configserver-2.com:9006/eureka/,http://configserver-3.com:9008/eureka/
之前在客户端中我们通过配置 eureka.client.serviceUrl.defaultZone 来指定对应的注册中心,当我们的注册中心有多个节点后,就需要修改 eureka.client.serviceUrl.defaultZone 的配置为多个节点的地址,多个地址用英文逗号隔开即可,并且都是配置的另外两个注册中心的地址。这里这三个eureka注册中心我们对应的端口分别是:9000、9006、9008
因为要演示集群效果,这里再启动一个服务注册到这三个注册中心服务组成的集群中,我们改变consumer服务的配置如下:
server:
port: 9090
spring:
application:
name: consumer
security: # eureka管理后台安全认证
user:
name: ImOK #用户名
password: 123456 #密码
eureka:
client:
service-url:
defaultZone: http://ImOK:123456@configserver-1.com:9000/eureka/,http://configserver-2.com:9006/eureka/,http://configserver-3.com:9008/eureka/其实就是改变eureka地址,由原来的的单点地址,变成现在三个地址都写上,逗号分隔。
下面启动三个eureka注册中心服务和consumer服务,分别打开三个注册认证中心的管理后台地址,如下:



可以看出每个注册中心服务都注册进了另外两个注册中心中,并且consumer服务注册进了每个注册中心服务中。
5.6 Eureka自我保护模式 和 InstanceID 的配置
保护模式主要在一组客户端和 Eureka Server 之间存在网络分区场景时使用。一旦进入保护模式,Eureka Server 将会尝试保护其服务的注册表中的信息,不再删除服务注册表中的数据。当网络故障恢复后,该 Eureka Server 节点会自动退出保护模式。
如果在 Eureka 的 Web 控制台看到图 1 所示的内容,就证明 Eureka Server 进入保护模式了。
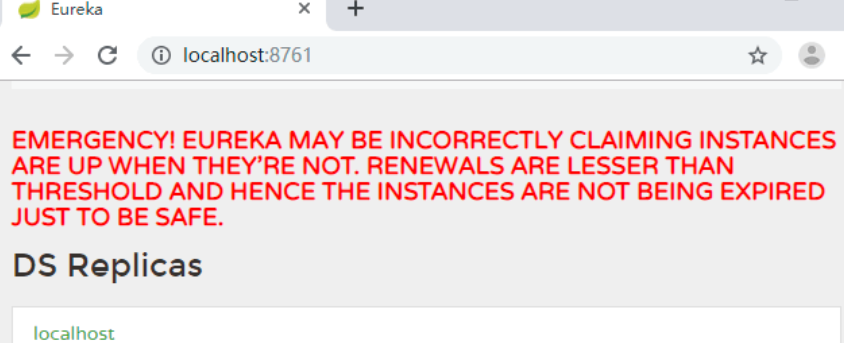
可以通过下面的配置将自我保护模式关闭,这个配置是在 eureka-server 中:
eureka.server.enableSelfPreservation=false自定义 Eureka 的 InstanceID
客户端在注册时,服务的 Instance ID 的默认值的格式如下:
${spring.cloud.client.hostname}:${spring.application.name}:${spring.application. instance_id:${server.port}}翻译过来就是“主机名:服务名称:服务端口”。在 Eureka 的 Web 控制台查看服务注册信息时,就是这样的格式:

但是很多时候我们想把 IP 显示在上述格式中,这样看起来就更方便。可以改成下面的样子,用“服务名称:服务所在 IP:服务端口”的格式来定义:
eureka.instance.instance-id=${spring.application.name}:${spring.cloud.client.ip-address}:${server.port} 
定义之后我们看到的就是UP (1) - provider:192.168.1.14:8001,一看就知道是哪个服务,在哪台机器上,端口是多少。
默认情况下,鼠标移动到UP (1) - provider:192.168.1.14:8001这个地址上时,浏览器左下方时域名的形式展示:

还需要加一个配置才能让跳转的链接变成 IP ,如图所示:
eureka.instance.preferIpAddress=true
5.7 Eureka开发时快速移除失效服务
在实际开发过程中,我们可能会不停地重启服务,由于 Eureka 有自己的保护机制,故节点下线后,服务信息还会一直存在于 Eureka 中。我们可以通过增加一些配置让移除的速度更快一点,当然只在开发环境下使用,生产环境下不推荐使用。
首先在我们的 eureka-server 中增加两个配置,分别是关闭自我保护和清理间隔:
eureka.server.enable-self-preservation=false
# 默认 60000 毫秒
eureka.server.eviction-interval-timer-in-ms=5000然后在具体的客户端服务中配置下面的内容:
eureka.client.healthcheck.enabled=true
# 默认 30 秒
eureka.instance.lease-renewal-interval-in-seconds=5
# 默认 90 秒
eureka.instance.lease-expiration-duration-in-seconds=5eureka.client.healthcheck.enabled 用于开启健康检查,需要在 pom.xml 中引入 actuator 的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>其中:
- eureka.instance.lease-renewal-interval-in-seconds 表示 Eureka Client 发送心跳给 server 端的频率。
- eureka.instance.lease-expiration-duration-in-seconds 表示 Eureka Server 至上一次收到 client 的心跳之后,等待下一次心跳的超时时间,在这个时间内若没收到下一次心跳,则移除该 Instance。
5.8 Eureka原理解析
上面还是Eureka的表象阶段,它的原理是怎样的?存储结构是怎样的?
(1)数据存储结构
既然是服务注册中心,必然要存储服务的信息,我们知道ZK是将服务信息保存在树形节点上。而下面是Eureka的数据存储结构:

Eureka的数据存储分了两层:
数据存储层和缓存层。Eureka Client在拉取服务信息时,先从缓存层获取(相当于Redis),如果获取不到,先把数据存储层的数据加载到缓存中(相当于Mysql),再从缓存中获取。区别是:数据存储层的数据结构是服务信息,而缓存中保存的是经过处理加工过的、可以直接传输到Eureka Client的数据结构。
Eureka这样的数据结构设计是把内部的数据存储结构与对外的数据结构隔离开了,就像是我们平时在进行接口设计一样,对外输出的数据结构和数据库中的数据结构往往都是不一样的。
(2)数据存储层
这里为什么说是存储层而不是持久层?因为rigistry本质上是一个双层的ConcurrentHashMap,存储在内存中的。
- 第一层的key是spring.application.name,value是第二层ConcurrentHashMap;
- 第二层ConcurrentHashMap的key是服务的InstanceId,value是Lease对象;Lease对象包含了服务详情和服务治理相关的属性。
(3)二级缓存层
Eureka实现了二级缓存来保存即将要对外传输的服务信息,数据结构完全相同。
- 一级缓存:ConcurrentHashMap<Key,Value> readOnlyCacheMap,本质上是HashMap,无过期时间,保存服务信息的对外输出数据结构。
- 二级缓存:Loading<Key,Value> readWriteCacheMap,本质上是guava的缓存,包含失效机制,保存服务信息的对外输出数据结构。
既然是缓存,那必然要有更新机制,来保证数据的一致性。下面是缓存的更新机制:
更新机制包含删除和加载两个部分,上图黑色箭头表示删除缓存的动作,绿色表示加载或触发加载的动作。
【删除二级缓存】:
1、Eureka Client发送register、renew和cancel请求并更新registry注册表之后,删除二级缓存;
2、Eureka Server自身的Evict Task剔除服务后,删除二级缓存;
3、二级缓存本身设置了guava的失效机制,隔一段时间后自己自动失效;
【加载二级缓存】:
1、Eureka Client发送getRegistry请求后,如果二级缓存中没有,就触发guava的load,即从registry中获取原始服务信息后进行处理加工,再加载到二级缓存中。
2、Eureka Server更新一级缓存的时候,如果二级缓存没有数据,也会触发guava的load。
【更新一级缓存】:
1、Eureka Server内置了一个TimerTask,定时将二级缓存中的数据同步到一级缓存(这个动作包括了删除和加载)。
服务注册机制
服务提供者、服务消费者、以及服务注册中心自己,启动后都会向注册中心注册服务。
注册中心服务接收到register请求后:
1、保存服务信息,将服务信息保存到registry中;
2、更新队列,将此事件添加到更新队列中,供Eureka Client增量同步服务信息使用。
3、清空二级缓存,即readWriteCacheMap,用于保证数据的一致性。
4、更新阈值,供剔除服务使用。
5、同步服务信息,将此事件同步至其他的Eureka Server节点。
服务续约机制
服务注册后,要定时(默认30S,可自己配置)向注册中心发送续约请求,告诉注册中心“我还活着”。
注册中心收到续约请求后:
1、更新服务对象的最近续约时间,即Lease对象的lastUpdateTimestamp;
2、同步服务信息,将此事件同步至其他的Eureka Server节点。
服务注销机制
服务正常停止之前会向注册中心发送注销请求,告诉注册中心“我要下线了”。
注册中心服务接收到cancel请求后:
1、删除服务信息,将服务信息从registry中删除;
2、更新队列,将此事件添加到更新队列中,供Eureka Client增量同步服务信息使用。
3、清空二级缓存,即readWriteCacheMap,用于保证数据的一致性。
4、更新阈值,供剔除服务使用。
5、同步服务信息,将此事件同步至其他的Eureka Server节点。
服务获取机制
Eureka Client获取服务有两种方式,全量同步和增量同步。获取流程是根据Eureka Server的多层数据结构进行的。
无论是全量同步还是增量同步,都是先从缓存中获取,如果缓存中没有,则先加载到缓存中,再从缓存中获取。(registry只保存数据结构,缓存中保存ready的服务信息。)
1、先从一级缓存中获取
a> 先判断是否开启了一级缓存
b> 如果开启了则从一级缓存中获取,如果存在则返回,如果没有,则从二级缓存中获取
d> 如果未开启,则跳过一级缓存,从二级缓存中获取
2、再从二级缓存中获取
a> 如果二级缓存中存在,则直接返回;
b> 如果二级缓存中不存在,则先将数据加载到二级缓存中,再从二级缓存中获取。注意加载时需要判断是增量同步还是全量同步,增量同步从recentlyChangedQueue中load,全量同步从registry中load。
服务同步机制
服务同步机制是用来同步Eureka Server节点之间服务信息的。它包括Eureka Server启动时的同步,和运行过程中的同步。
启动时同步
Eureka Server启动后,遍历eurekaClient.getApplications获取服务信息,并将服务信息注册到自己的registry中。
注意这里是两层循环,第一层循环是为了保证已经拉取到服务信息,第二层循环是遍历拉取到的服务信息。
运行过程中同步
当Eureka Server节点有register、renew、cancel请求进来时,会将这个请求封装成TaskHolder放到acceptorQueue队列中,然后经过一系列的处理,放到batchWorkQueue中。
TaskExecutor.BatchWorkerRunnable是个线程池,不断的从batchWorkQueue队列中poll出TaskHolder,然后向其他Eureka Server节点发送同步请求。
六、Ribbon(负载均衡器)
目前主流的负载方案分为以下两种:
- 集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的(比如 F5),也有软件的(比如 Nginx)。
- 客户端自己做负载均衡,根据自己的请求情况做负载,Ribbon 就属于客户端自己做负载。
客户端与服务端级别的负载均衡啥意思?
- 服务器端负载均衡:例如Nginx,通过Nginx进行负载均衡过程如下:先发送请求给nginx服务器,然后通过负载均衡算法,在多个业务服务器之间选择一个进行访问;即在服务器端再进行负载均衡算法分配。
- 客户端负载均衡:客户端会有一个服务器地址列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问,即在客户端就进行负载均衡算法分配。
详细的Ribbon使用及其原理见我的另一个文章: https://blog.csdn.net/weixin_41231928/article/details/107849876
七、Feign
Feign 是一个声明式的 REST 客户端,它能让 REST 调用更加简单。Feign 供了 HTTP 请求的模板,通过编写简单的接口和插入注解,就可以定义好 HTTP 请求的参数、格式、地址等信息。而 Feign 则会完全代理 HTTP 请求,我们只需要像调用方法一样调用它就可以完成服务请求及相关处理。
Feign原理之前有篇文章谈到过: https://blog.csdn.net/weixin_41231928/article/details/107850940
7.1 在Spring Cloud中集成Feign
为了演示Feign调用,我们在myspringcloud-api服务中集成Feign编写Feign接口,在consumer服务中调用。
在 Spring Cloud 中集成 Feign 的步骤相当简单,首先还是加入 Feign 的依赖,myspringcloud-api服务的pom中添加:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.1.3.RELEASE</version>
</dependency>编写Feign接口,注意加上@FeignClient注解并指明路径,这个一般是提供服务的服务名称,这里是provider,因为Feign包裹了Ribbon,所以Feign也是具有负载均衡效果的,这里就是通过provider来查找服务的,只要是名称叫provider都在负载均衡算法的选择范围内。
@Component
@FeignClient(value = "provider")
public interface DeptClient {
@PostMapping("/dept/add")
boolean add(@RequestBody Dept dept);
@GetMapping("/dept/getById/{deptno}")
Dept getById(@PathVariable("deptno") Long deptno);
@GetMapping("/dept/getAll")
List<Dept> getAll();
}另外,在写Feign接口的时候,要和服务提供者的Controller里面的方法保持一致(包括方法名、路径等),这里是和provider-A的Controller保持一致的,不一致可能导致服务调用时404或者其他错误,可以和上面的对比一下:
@RestController
@RequestMapping("/dept")
public class DeptController {
@Autowired
private DeptService deptService;
@PostMapping("/add")
public boolean add(@RequestBody Dept dept){
return deptService.addDept(dept);
}
@GetMapping("/getById/{deptno}")
public Dept getById(@PathVariable("deptno") Long deptno){
return deptService.queryById(deptno);
}
@GetMapping("/getAll")
public List<Dept> getAll(){
return deptService.queryAll();
}
}好了,现在开始进行调用了,在consumer服务中需要指定FeignClient的路径,在启动类上加 @EnableFeignClients 注解,如果你的 Feign 接口定义跟你的启动类不在同一个包名下,还需要制定扫描的包名@EnableFeignClients(basePackages = "com.feng.client")
@EnableEurekaClient
@SpringBootApplication
@EnableFeignClients(basePackages = "com.feng.client")
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}
再写一个调用接口:
@Slf4j
@RequestMapping("/feign")
@RestController
public class ConsumerFeignController {
@Autowired
private DeptClient deptClient;
@GetMapping("/getAll")
public List<Dept> getAllDept() {
return deptClient.getAll();
}
}调用效果:

当然我这里只启动了provider-A,你还可以把另外的myspringcloud-provider-B 和 myspringcloud-provider-C也起起来,验证下负载均衡效果,因为前面Ribbon时已经演示过负载,这里就不再演示。
7.2 Feign的自定义配置及使用
有时候我们遇到 Bug,比如接口调用失败、参数没收到等问题,或者想看看调用性能,就需要配置 Feign 的日志了,以此让 Feign 把请求信息输出来。
首先定义一个配置类:
@Configuration
public class FeignConfiguration {
/**
* 日志级别
*
* @return
*/
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}通过源码可以看到日志等级有 4 种,分别是:
- NONE:不输出日志。
- BASIC:只输出请求方法的 URL 和响应的状态码以及接口执行的时间。
- HEADERS:将 BASIC 信息和请求头信息输出。
- FULL:输出完整的请求信息。
配置类建好后,在 Feign Client 中的 @FeignClient 注解中指定使用的配置类:
@FeignClient(value = "eureka-client-user-service", configuration = FeignConfiguration. class)
public interface UserRemoteClient {
// ...
}在配置文件中执行 Client 的日志级别才能正常输出日志,格式是“logging.level.client 类地址=级别”。
logging.level.net.biancheng.feign_demo.remote.UserRemoteClient=DEBUG7.3 Basic 认证配置
通常我们调用的接口都是有权限控制的,很多时候可能认证的值是通过参数去传递的,还有就是通过请求头去传递认证信息,比如 Basic 认证方式。在 Feign 中我们可以直接配置 Basic 认证,代码如下所示:
@Configuration
public class FeignConfiguration {
@Bean
public BasicAuthRequestInterceptor basicAuthRequestInterceptor() {
return new BasicAuthRequestInterceptor("user", "password");
}
}或者你可以自定义属于自己的认证方式,其实就是自定义一个请求拦截器。在请求之前做认证操作,然后往请求头中设置认证之后的信息。通过实现 RequestInterceptor 接口来自定义认证方式,代码如下所示。
public class FeignBasicAuthRequestInterceptor implements RequestInterceptor {
public FeignBasicAuthRequestInterceptor() {
}
@Override
public void apply(RequestTemplate template) {
// 业务逻辑
}
}然后将配置改成自定义的,这样当 Feign 去请求接口的时候,每次请求之前都会进入 FeignBasicAuthRequestInterceptor 的 apply 方法中,在里面就可以做属于你的逻辑了:
@Configuration
public class FeignConfiguration {
@Bean
public FeignBasicAuthRequestInterceptor basicAuthRequestInterceptor() {
return new FeignBasicAuthRequestInterceptor();
}
}7.4 超时时间配置
通过 Options 可以配置连接超时时间和读取超时时间(代码如下所示),Options 的第一个参数是连接超时时间(ms),默认值是 10×1000;第二个是取超时时间(ms),默认值是 60×1000。
@Configuration
public class FeignConfiguration {
@Bean
public Request.Options options() {
return new Request.Options(5000, 10000);
}
}7.5 GZIP 压缩配置
开启压缩可以有效节约网络资源,提升接口性能,我们可以配置 GZIP 来压缩数据:
feign.compression.request.enabled=true
feign.compression.response.enabled=true还可以配置压缩的类型、最小压缩值的标准:
feign.compression.request.mime-types=text/xml,application/xml,application/json
feign.compression.request.min-request-size=2048只有当 Feign 的 Http Client 不是 OkHttp3 的时候,压缩才会生效,配置源码在 org.spring-framework.cloud.openfeign.encoding.FeignAcceptGzipEncodingAutoConfiguration,源码:
@Configuration
@EnableConfigurationProperties(FeignClientEncodingProperties.class)
@ConditionalOnClass(Feign.class)
@ConditionalOnBean(Client.class)
@ConditionalOnProperty(value = "feign.compression.response.enabled", matchIfMissing = false)
@ConditionalOnMissingBean(type = "okhttp3.OkHttpClient")
@AutoConfigureAfter(FeignAutoConfiguration.class)
public class FeignAcceptGzipEncodingAutoConfiguration {
@Bean
public FeignAcceptGzipEncodingInterceptor feignAcceptGzipEncodingInterceptor(
FeignClientEncodingProperties properties) {
return new FeignAcceptGzipEncodingInterceptor(properties);
}
}核心代码就是 @ConditionalOnMissingBean(type="okhttp3.OkHttpClient"),表示 Spring BeanFactory 中不包含指定的 bean 时条件匹配,也就是没有启用 okhttp3 时才会进行压缩配置。
7.6 使用配置自定义 Feign 的配置
除了使用代码的方式来对 Feign 进行配置,我们还可以通过配置文件的方式来指定 Feign 的配置。
# 链接超时时间
feign.client.config.feignName.connectTimeout=5000
# 读取超时时间
feign.client.config.feignName.readTimeout=5000
# 日志等级
feign.client.config.feignName.loggerLevel=full
# 重试
feign.client.config.feignName.retryer=com.example.SimpleRetryer
# 拦截器
feign.client.config.feignName.requestInterceptors[0]=com.example.FooRequestInterceptor
feign.client.config.feignName.requestInterceptors[1]=com.example.BarRequestInterceptor
# 编码器
feign.client.config.feignName.encoder=com.example.SimpleEncoder
# 解码器
feign.client.config.feignName.decoder=com.example.SimpleDecoder
# 契约
feign.client.config.feignName.contract=com.example.SimpleContract八、Hystrix(熔断器)
Hystrix 是 Netflix 针对微服务分布式系统采用的熔断保护中间件,相当于电路中的保险丝。
在分布式环境中,许多服务依赖项中的一些必然会失败。Hystrix 是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互。Hystrix 通过隔离服务之间的访问点、停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
在微服务架构下,很多服务都相互依赖,如果不能对依赖的服务进行隔离,那么服务本身也有可能发生故障,Hystrix 通过 HystrixCommand 对调用进行隔离,这样可以阻止故障的连锁效应,能够让接口调用快速失败并迅速恢复正常,或者回退并优雅降级。很多时候服务降级和服务熔断是容易混淆的,但是两者实际是不一样的:
详见本文最后的:补充十一:降级和熔断的区别?
8.1 Hystrix实现容错处理
在consumer服务的pom文件中增加 Hystrix 的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>在consumer启动类上添加 @EnableHystrix 或者 @EnableCircuitBreaker。注意,@EnableHystrix 中包含了 @EnableCircuitBreaker。
@EnableEurekaClient
@SpringBootApplication
@EnableFeignClients(basePackages = "com.feng.client")
@EnableHystrix
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}然后编写一个调用接口的方法,在上面增加一个 @HystrixCommand 注解,用于指定依赖服务调用延迟或失败时调用的方法:
@Slf4j
@RequestMapping("/hystrix")
@RestController
@DefaultProperties(defaultFallback = "defaultBack")
public class HystrixDemoController {
@HystrixCommand(fallbackMethod = "friendlyBack_1")
@GetMapping("/demo1")
public String demo1() {
throw new RuntimeException();
}
private String friendlyBack_1() {
return "返回友好界面——1";
}
@HystrixCommand(fallbackMethod = "friendlyBack_2")
@GetMapping("/demo2")
public String demo2() {
System.out.println("进入demo2....");
throw new RuntimeException();
}
@HystrixCommand(defaultFallback = "friendlyBack_3")
private String friendlyBack_2() {
System.out.println("进入friendlyBack_2....");
throw new RuntimeException();
}
@HystrixCommand
private String friendlyBack_3() {
System.out.println("进入friendlyBack_3....");
throw new RuntimeException();
}
private String defaultBack() {
System.out.println("进入defaultBack....");
return "默认友好界面";
}
@HystrixCommand(commandProperties =
{
// 熔断器在整个统计时间内是否开启的阀值
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
// 至少有3个请求才进行熔断错误比率计算
/**
* 设置在一个滚动窗口中,打开断路器的最少请求数。
比如:如果值是20,在一个窗口内(比如10秒),收到19个请求,即使这19个请求都失败了,断路器也不会打开。
*/
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "3"),
//当出错率超过50%后熔断器启动
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),
// 熔断器工作时间,超过这个时间,先放一个请求进去,成功的话就关闭熔断,失败就再等一段时间
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "5000"),
// 统计滚动的时间窗口
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "10000")
})
@GetMapping("/demo3")
public String demo3(Integer id) {
System.out.println("id:" + id);
if (id % 2 == 0) {
throw new RuntimeException();
}
return "test_" + id;
}
}当访问http://localhost:9090/hystrix1/demo1抛出异常,服务降级返回friendlyBack_1。
当访问http://localhost:9090/hystrix1/demo2抛出异常,服务不断降级返回defaultBack。


8.2 Hystrix的实时监控功能
在微服务架构中,Hystrix 除了实现容错外,还提供了实时监控功能。在服务调用时,Hystrix 会实时累积关于 HystrixCommand 的执行信息,比如每秒的请求数、成功数等。
Hystrix 监控需要两个必备条件:
1)必须有 Actuator 的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>2)必须有 Hystrix 的依赖,Spring Cloud 中必须在启动类中添加 @EnableHystrix 开启 Hystrix
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>将 actuator 中的端点暴露出来,访问端点地址(http://localhost:9090/actuator/hystrix.stream):

从图中可以看到一直在输出“ping:”,出现这种情况是因为还没有数据,等到 HystrixCommand 执行了之后就可以看到具体数据了。调用一下接口 http://localhost:9090/hystrix/demo1,访问之后就可以看到 http://localhost:9090/actuator/hystrix.stream 这个页面中输出的数据了:

8.3 使用Hystrix Dashboard(熔断仪表盘)查看监控数据
我们已经知道 Hystrix 提供了监控的功能,可以通过 hystrix.stream 端点来获取监控数据,但是这些数据是以字符串的形式展现的,实际使用中不方便查看。我们可以借助 Hystrix Dashboard 对监控进行图形化展示。
在consumer服务的 pom.xml 中添加 dashboard 的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>创建启动类,在启动类上添加 @EnableHystrixDashboard 注解:
@EnableEurekaClient
@SpringBootApplication
@EnableFeignClients(basePackages = "com.feng.client")
@EnableHystrix
@EnableHystrixDashboard
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}
添加一个 HystrixConfig 配置类:
@Configuration
public class HystrixConfig {
@Bean
public HystrixCommandAspect hystrixAspect() {
return new HystrixCommandAspect();
}
/**
* 向监控中心Dashboard发送stream消息
*/
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/actuator/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
}然后启动服务,访问 http://localhost:9090/hystrix 就可以看到 dashboard 的主页:

在主页中有 3 个地方需要我们填写,第一行是监控的 stream 地址,也就是将之前文字监控信息的地址输入到第一个文本框中。第二行的 Delay 是时间,表示用多少毫秒同步一次监控信息,Title 是标题,这个可以随便填写。输入完成后就可以点击 Monitor Stream 按钮以图形化的方式查看监控的数据了:

监控图中用圆点来表示服务的健康状态,健康度从100%-0%分别会用绿色、黄色、橙色、红色来表示。 另外,这个圆点也会随着流量的增多而变大。 监控图中会用曲线(圆点旁边)来表示服务的流量情况,通过这个曲线可以观察单个接口的流量变化/趋势。
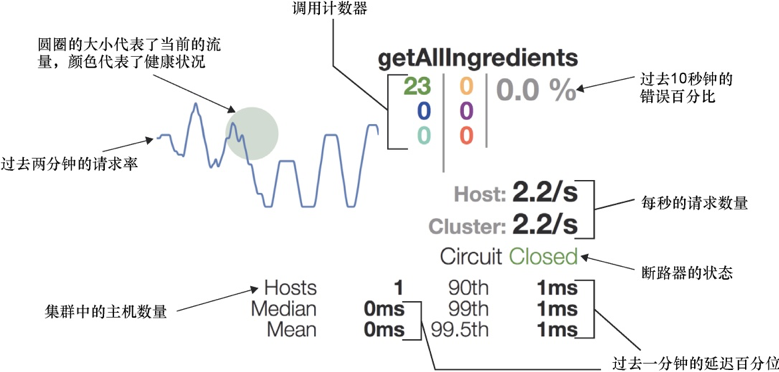
折线图代表了指定方法过去两分钟的流量,简要显示了改方法的繁忙情况。
折线图的背景是一个大小和颜色会出现波动的圆圈,圆圈的大小表示当前的流量,圆圈越大,流量越大。圆圈的颜色表示它的建库状况:绿色表示建库的断路器,黄色表示偶尔发生故障的断路器,红色表示故障断路器。
在监视器的右上角,以3列的形式显示各种计数器。在最左边的一列中,从上到下,第一个数字(绿色)表示当前成功调用的数量;第二个数字(蓝色)表示短路请求的数量;最后一个数字(蓝绿色)表示错误请求的数量。
中间一列显示超时请求的数量(黄色)、线程池拒绝的数量(紫色)和失败请求的数量(红色)。
第三列显示过去10s内错误的百分率。
计数器下面有两个数字,代表每秒主机和集群的请求数量。这两个请求率下面是断路器的状态。Median和Mean显示了延迟的中位数和平均值。90th、99th、99.5表示百分位的延迟。
Turbine 是聚合服务器发送事件流数据的一个工具。Hystrix 只能监控单个节点,然后通过 dashboard 进行展示。实际生产中都为集群,这个时候我们可以通过 Turbine 来监控集群下 Hystrix 的 metrics 情况,通过 Eureka 来发现 Hystrix 服务。

与断路器的监视器类似,每个线程池监视器在左上角都包含一个圆圈,圆圈大小和颜色代表了线程池的活跃状态以及健康状况。与断路器的监视器不同的是,线程池的监视器没有显示过去几分钟线程池活跃的折线图。
右上角显示线程池的名称,其下方是线程池中线程每秒处理请求的数量。
线程池监视器的左下角显示如下信息
- 活跃线程:当前活跃线程的数量
- 排队线程:当前有多少线程在排队。默认情况下,队列功能是禁用的,所以这个值始终为0.
- 线程池的大小:线程池中有多少线程
右下角显示如下信息
- 最大活跃线程:在当前的采样周期中,活跃线程的最大数量
- 执行次数:线程池中的线程被调用执行Hystrix命令的次数
- 线程队列大小:线程池队列的大小。线程队列功能默认是禁用的,所以这个值没有什么意义
九、Zuul网关
提供路由、监控、弹性、安全等方面的服务框架。
Zuul 的核心是过滤器,通过这些过滤器我们可以扩展出很多功能,比如:
1)动态路由
动态地将客户端的请求路由到后端不同的服务,做一些逻辑处理,比如聚合多个服务的数据返回。
2)请求监控
可以对整个系统的请求进行监控,记录详细的请求响应日志,可以实时统计出当前系统的访问量以及监控状态。
3)认证鉴权
对每一个访问的请求做认证,拒绝非法请求,保护好后端的服务。
4)压力测试
压力测试是一项很重要的工作,像一些电商公司需要模拟更多真实的用户并发量来保证重大活动时系统的稳定。通过 Zuul 可以动态地将请求转发到后端服务的集群中,还可以识别测试流量和真实流量,从而做一些特殊处理。
5)灰度发布
灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
9.1 Zuul过滤器
Zuul 中的过滤器总共有 4 种类型,且每种类型都有对应的使用场景。
1)pre:可以在请求被路由之前调用。适用于身份认证的场景,认证通过后再继续执行下面的流程。
2)route:在路由请求时被调用。适用于灰度发布场景,在将要路由的时候可以做一些自定义的逻辑。
3)post:在 route 和 error 过滤器之后被调用。这种过滤器将请求路由到达具体的服务之后执行。适用于需要添加响应头,记录响应日志等应用场景。
4)error:处理请求时发生错误时被调用。在执行过程中发送错误时会进入 error 过滤器,可以用来统一记录错误信息。
9.2 Zuul集成
新建my-zuul服务,并引入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>启动类增加@EnableZuulProxy注解:
@EnableEurekaClient
@SpringBootApplication
@EnableZuulProxy
public class ZuulApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulApplication.class, args);
}
}配置文件如下:
server:
port: 9006
spring:
application:
name: my_zuul
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/
zuul:
routes:
service-a:
path: /service-consumer/**
serviceId: consumer
service-b:
path: /service-provider/**
serviceId: provider
其中,zuul.routes可配置要可代理的服务路径和服务名,path随便写,用于通过zuul访问时的地址,这样可以隐藏真实服务名,serviceId就是真实服务名。
服务启动后,通过网关访问:

另外,为了演示zuul的请求过滤与验证功能,新增一个filter配置类:
@Configuration
public class FilterConfig {
@Bean
Filter getFilterBean(){
return new Filter();
}
}在新增一个Filter类继承ZuulFilter并重写其run()方法:
@Slf4j
@Component
public class Filter extends ZuulFilter {
/**
* 过滤器类型 pre表示在请求之前进行逻辑操作
*/
public String filterType() {
return "pre";
}
/**
* 过滤器执行顺序 当一个请求在同一个阶段存在多个过滤器的时候 过滤器的执行顺序
*/
public int filterOrder() {
return 0;
}
/**
* 是否开启过滤
*/
public boolean shouldFilter() {
return true;
}
/**
* 要实现的过滤规则在这里完成,比如我们可以做token验证,token=6 时就能进入,不被过滤
*/
public Object run() throws ZuulException {
RequestContext currentContext = RequestContext.getCurrentContext();
HttpServletRequest request = currentContext.getRequest();
String token = request.getParameter("token");
StringBuffer requestURL = request.getRequestURL();
log.info("【请求路径】:{}", requestURL + "?" + request.getQueryString());
if (StringUtils.isEmpty(token) || !"6".equals(token)) {
currentContext.setSendZuulResponse(false);
currentContext.setResponseBody("No access rights!");
currentContext.setResponseStatusCode(401);
}
return null;
}
}规律规则就是要有token且token=6时才能通过,否则不能访问:


十、Gateway
Gateway 作为 Spring Cloud 生态系中的网关,其目标是替代 Netflix Zuul。它不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全、监控/埋点和限流等。
开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。API 网关作为所有请求的入口,请求量大,我们可以通过对并发访问的请求进行限速来保护系统的可用性。
十一、Spring cloud Config
对于一些简单的项目来说,我们一般都是直接把相关配置放在单独的配置文件中,以 properties 或者 yml 的格式出现,更省事儿的方式是直接放到 application.properties 或 application.yml 中。但是这样的方式有个明显的问题,那就是,当修改了配置之后,必须重启服务,否则配置无法生效。
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务相对粒度较小,会有很多服务。每个服务都需要相应的配置信息,一套集中式的、动态配置管理的设施是必不可少的。Springcloud提供了ConfigServer来解决这个问题。Spring cloud Config为微服务架构中的服务提供集中化的外部配置支持。
Spring cloud Config也分为服务端和客户端。服务端也称为分布式配置中心,它是一个独立的微服务应用,用来连接配置服务器并为客户端提供获取配置信息,加密解密信息等访问接口。
目前有一些用的比较多的开源的配置中心,比如携程的 Apollo、蚂蚁金服的 disconf 等,对比 Spring Cloud Config,这些配置中心功能更加强大。有兴趣的可以拿来试一试。
11.1 准备工作
Spring cloud Config就是要拉去远程仓库中的配置嘛,所以提前在GitHub上建个spring-cloud-config-center仓库,里面放入两个配置文件:application.yml 和 config-demo.yml,配置文件具体内容如下:

上面红圈的地址很重要,这个https地址后面要放在项目的配置文件里,用于连接这个远程仓库:


上面的“---”用于分割不同环境的属性配置。
11.2 config服务端搭建
新建一个my-config-server项目,添加依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>启动类添加@EnableConfigServer注解:
@EnableEurekaClient
@EnableConfigServer
@SpringBootApplication
public class ConfigApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigApplication.class, args);
}
}配置文件有两个:application.yml、bootstrap.yml,具体内容分别如下:
application.yml:
server:
port: 6666
eureka:
client:
service-url:
defaultZone: http://ImOK:123456@localhost:9000/eureka/bootstrap.yml:
spring:
cloud:
config:
server:
git:
uri: https://github.com/ImOk520/spring-cloud-config-center.git
default-label: main这里为啥要搞两个配置文件?把配置都写在一个application.yml文件中不就好了,再弄个bootstrap.yml干啥?这里就需要搞清楚application.yml和bootstrap.yml的区别了,详情见本文最后的:补充十 :application.yml和bootstrap.yml的区别
实际上你可以试一下,若把所有配置都写在一个application.yml文件中,请求是会报错的。
下面就是来看看my-config-server能不读取远程git仓库的地址,Spring Cloud Config 有它的一套访问规则,我们通过这套规则就可以在浏览器上直接访问。
/{application}/{profile}[/{label}]
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties上面profile指的就是环境标志:dev、test、prod等;label就是当前读取的配置是是仓库的哪个分支。
这样我们直接请求如下:

http://localhost:6666/application-dev.yml 就是获取application.yml中dev对应的配置,采用的是第二种访问方式,你可以试试其他3中访问方式。
11.3 config客户端搭建
上一节已经完成了config服务端的搭建,这里继续搭建config客户端。
通过客户端调用服务端,然后服务端再去连接远程仓库。
新建一个my-config-client服务,添加依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>在配置文件中添加配置:
spring:
cloud:
config:
name: config-demo
profile: dev
label: main
uri: http://localhost:6666这里uri的值就是config服务端的服务地址。name、profile、label和uri组成了完整的唯一地址,锁定唯一一块符合条件的配置。
为了演示客户端能够获远程取配置属性的值,我们添加一个Controller类:
@Slf4j
@RequestMapping("/config-client")
@RestController
public class ConfigClientTestController {
@Value("${spring.application.name}")
private String applicationName;
@Value("${eureka.client.service-url.defaultZone}")
private String eurekaServer;
@Value("${server.port}")
private String port;
@GetMapping("/getRemoteConfigs")
public String getRemoteConfigs() {
log.info("applicationName: {}", applicationName);
log.info("eurekaServer: {}", eurekaServer);
log.info("port: {}", port);
return applicationName+ " " + eurekaServer + "" + port;
}
}启动客户端,启动日志已经展示了服务接口: ![]()
这个端口在本地配置文件中是没有的,这个端口来自远程仓库,说明我们客户端已经成功取得了远程仓库中的相应配置信息。不信可以进一步验证,eurekaServer和port都是远程仓库的配置文件中的值,若调用接口时能打印出来值也说明客户端获取远程信息成功。

eurekaServer和port信息都打印出来了。
11.4 配置中心 自动刷新原理
总的来说:
`ConfigServer`(配置中心服务端)从远端`git`拉取配置文件并在本地`git`一份,`ConfigClient`(微服务)从`ConfigServer`端获取自己对应 配置文件;
当远端`git`仓库配置文件发生改变,`ConfigServer`如何通知到`ConfigClient`端,即`ConfigClient`如何感知到配置发生更新?
Spring Cloud Bus用于支撑配置的动态刷新。这项技术是基于消息队列服务来实现的,简单来说,Spring Cloud Bus使用一个消息队列服务形成一个消息总线,每个需要获取配置的客户端都将与消息总线连接,获得各自独立的一个Channel,而配置中心则是负责通过消息总线通知所有客户端获取最新的配置。
`Spring Cloud Bus`会向外提供一个`http接口`,即图中的`/bus/refresh`。将这个接口配置到远程的`git`的`webhook`上,当`git`上的文件内容发生变动时,就会自动调用`/bus-refresh`接口。`Bus`就会通知`config-server`,`config-server`会发布更新消息到消息总线的消息队列中,其他服务订阅到该消息就会信息刷新,从而实现整个微服务进行自动刷新。
具体的实现方式有两种:
实现方式一:某个微服务承担配置刷新的职责

- 提交配置触发`post`调用客户端A的`bus/refresh`接口
- 客户端A接收到请求从`Server端`更新配置并且发送给`Spring Cloud Bus`总线
- `Spring Cloud bus`接到消息并通知给其它连接在总线上的客户端,所有总线上的客户端均能收到消息
- 其它客户端接收到通知,请求`Server端`获取最新配置
- 全部客户端均获取到最新的配置
存在问题:
1、打破了微服务的职责单一性。微服务本身是业务模块,它本不应该承担配置刷新的职责。2、破坏了微服务各节点的对等性。3、有一定的局限性。WebHook的配置随着承担刷新配置的微服务节点发生改变。
方式二:配置中心Server端承担起配置刷新的职责,原理图如下:

- 提交配置触发`post`请求给`server端`的`bus/refresh`接口
- `server端`接收到请求并发送给`Spring Cloud Bus`总线
- `Spring Cloud bus`接到消息并通知给其它连接到总线的客户端
- 其它客户端接收到通知,请求`Server端`获取最新配置
- 全部客户端均获取到最新的配置
11.5 实现步骤
基本步骤:1、添加依赖 2、修改配置文件 3、添加注解
备注:这里给出方式二配置方法,方式一的区别在:因为是某个微服务承担配置刷新的职责,所以Server端不需要配置 Rabbitmq和添加bus-amqp的依赖。
Server端
1、添加依赖
<!-- config-server依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<!-- springcloud-bus依赖实现配置自动更新,rabbitmq -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>2、修改配置文件Bootstrap.yml文件
server:
port: 9090
spring:
application:
name: config-server
cloud: #config服务端,从git拉取数据
config:
server:
git:
uri: https://github.com/****/config-repo # 配置git仓库的地址
username: # git仓库的账号
password: # git仓库的密码
search-paths: /*/*/*,/* #仓库下配置文件搜索路径
rabbitmq: #本地环境不需要配置mq,但是需要启动mq,Springboot会自动连接本地mq
host: localhost
port: 5672
username: guest
password: guest
eureka: #注册服务
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
#defaultZone: http://localhost:8761/eureka/,http://localhost:8762/eureka/ #eureka高可用
management: #SpringCloud 1.5版本暴露接口,暴露/bus-refresh接口
security:
enabled: false
# endpoints: #SpringCloud 2.0.0版本以后暴露接口方式
# web:
# exposure:
# include: "*"
security: #是否开启基本的鉴权,默认为true
basic:
enabled: false3、启动类增加注解 @EnableConfigServer

Config Client端配置:
1、添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>2、修改配置文件Bootstrap.yml文件
server:
port: 9092
spring:
application:
name: config-client #对应微服务配置文件名称
cloud:
config:
uri: http://localhost:9090/ #config server 端地址
profile: dev #项目配置文件选择
label: master #git仓库的分支
discovery:
enabled: true
service-id: config-server #config-server服务名称
rabbitmq: #本地环境不需要配置mq
host: localhost
port: 5672
username: guest
password: guest
security: #
basic:
enabled: false3、添加注解: @RefreshScope添加在需要刷新的配置文件上
注明:自动刷新只能刷新 @RefreshScope 注解下的配置,一些特殊配置,如数据库等,需要同样先设置数据库链接ConfigServer类,然后通过加 @RefreshScope 注解方式

到这里Config-Server端和Client端已经配置完毕,先后启动Server端和Client端,post请求方式进行测试:http://localhost:9090/bus/refresh
git的webhook:
启动Server端和Client端,要实现配置自动刷新需要调用/bus-refresh接口通知config-Server
方式一:手动调用(post请求):http://localhost:9090/bus/refresh(Server端地址)
方式二:配置git的webhook ,当git端配置发生改变,自动调用/bus-refresh接口
十二、JWT(Json Web Token)
JWT 的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源。由于此信息是经过数字签名的,因此可以被验证和信任。
比如用在用户登录上时,基本思路就是用户提供用户名和密码给认证服务器,服务器验证用户提交信息的合法性;如果验证成功,会产生并返回一个 Token,用户可以使用这个 Token 访问服务器上受保护的资源。
JWT 由三部分构成,第一部分称为头部(Header),第二部分称为消息体(Payload),第三部分是签名(Signature)。一个 JWT 生成的 Token 格式为:
token = encodeBase64(header) + '.' + encodeBase64(payload) + '.' + encodeBase64(signature)(1)头部的信息通常由两部分内容组成,令牌的类型和使用的签名算法:
{
"alg": "HS256",
"typ": "JWT"
}(2)消息体中可以携带一些你需要的信息,比如用户 ID。因为你得知道这个 Token 是哪个用户的:
{
"id": "1234567890",
"name": "John Doe",
"admin": true
}(3)签名是用来判断消息在传递的路上是否被篡改,从而保证数据的安全性,格式如下:
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)signature 签名需要使用编码后的header和payload以及我们提供的一个密钥,然后使用header中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过。
注意:密钥就是用来进行JWT的签发和JWT的验证,所以,它就是你服务端的私钥,在任何场景都不应该泄露出去。
12.1 JWT认证流程

认证流程如下:
- 用户使用账号和密码发出post请求;
- 服务器使用私钥创建一个jwt;
- 服务器返回这个jwt给浏览器;
- 浏览器将该jwt串在请求头中像服务器发送请求;
- 服务器验证该jwt;
- 返回响应的资源给浏览器。
12.2 JWT认证和session认证的区别
【session认证】
http协议是一种无状态的协议,而这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,那么下一次请求时,用户还要再一次进行用户认证才行,因为根据http协议,我们并不能知道是哪个用户发送的请求,所以为了让我们的应用能识别是哪个用户发出的,我们只能在服务器存储一份用户登陆的信息,这份登陆信息会在响应时传递给浏览器,告诉其保存为cookie,以便下次请求时发送给我们的应用,这样我们的应用个就能识别请求来自哪个用户了,这就是传统的基于sessino认证。
【JWT认证】
基于token的鉴权机制类似于http协议也是无状态的,它不需要在服务端去保留用户的认证信息或会话信息。这也就意味着JWT认证机制的应用不需要去考虑用户在哪一台服务器登录了,这就为应用的扩展提供了便利。
12.3 JWT使用场景
- 授权
这是JWT使用最多的场景,一旦用户登录,每个后续的请求将包括JWT,从而允许用户访问该令牌允许的路由、服务和资源。
- 信息交换:JSON
JWT可以用在各方之间安全地传输信息,因为JWT可以进行签名,所以您可以确定发件人是他们所说的人。另外,由于签名是使用标头和有效负载计算的,因此您还可以验证内容是否未被篡改。
十三、Spring Boot Admin
Actuator是Springboot提供的用来对应用系统进行自省和监控的功能模块,借助于Actuator开发者可以很方便地对应用系统某些监控指标进行查看、统计等。、
下表包含了Actuator提供的主要监控项:

/autoconfig
用来查看自动配置的使用情况,包括:哪些被应用、哪些未被应用以及它们未被应用的原因、哪些被排除。
【/configprops】显示一个所有@ConfigurationProperties的整理列表。
【/beans】显示Spring容器中管理的所有Bean的信息。
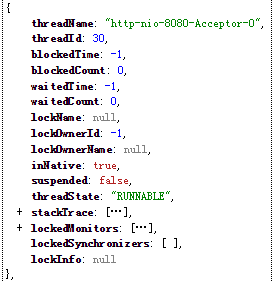
【/dump】用来查看应用所启动的所有线程,每个线程的监控内容如下图所示:
/env用来查看整个应用的配置信息,使用/env/[name]可以查看具体的配置项:

/health查看整个应用的健康状态,包括磁盘空间使用情况、数据库和缓存等一些健康指标。

此外,Springboot还允许用户自定义健康指标,只需要定义一个类实现HealthIndicator接口,并将其纳入到Spring容器的管理之中。
@Component
public class MyHealthIndicator implements HealthIndicator{
@Override
public Health health() {
return Health.down().withDetail("error", "spring boot error").build();
}
}/info可以显示配置文件中所有以info.开头或与Git相关的一些配置项的配置信息。
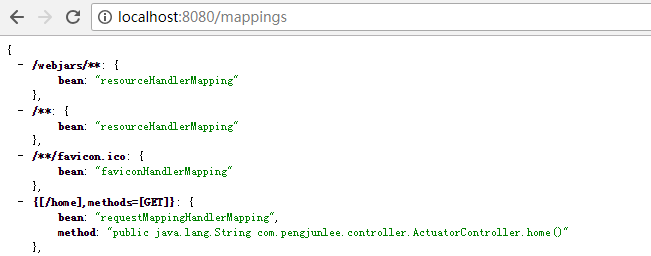
/mappings用来查看整个应用的URL地址映射信息
/metrics用来查看一些监控的基本指标,也可以使用/metrics/[name]查看具体的指标。

此外,Springboot还为提供了CounterService和GaugeService两个Bean来供开发者使用,可以分别用来做计数和记录double值。
@RestController
public class ActuatorController {
@Autowired
private CounterService counterService;
@Autowired
private GaugeService gaugeService;
@GetMapping("/home")
public String home() {
//请求一次浏览数加1
counterService.increment("home browse count");
//请求时将app.version设置为1.0
gaugeService.submit("app.version", 1.0);
return "Actuator home";
}
}/shutdown是一个POST请求,用来关闭应用,由于操作比较敏感,默认情况下该请求是被禁止的,若要开启需在配置文件中添加以下配置:
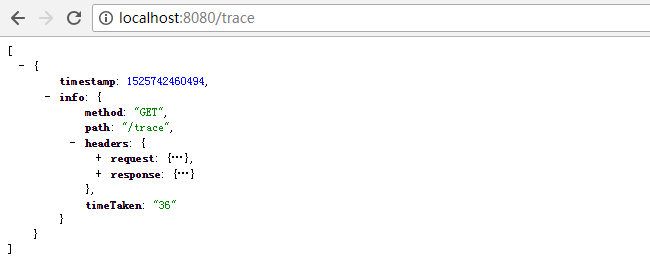
endpoints.shutdown.enabled: true/trace用来监控所有请求的追踪信息,包括:请求时间、请求头、响应头、响应耗时等信息。
能够将 Actuator 中的信息进行界面化的展示,也可以监控所有 Spring Boot 应用的健康状况,提供实时警报功能。
主要的功能点有:
- 显示应用程序的监控状态
- 应用程序上下线监控
- 查看 JVM,线程信息
- 可视化的查看日志以及下载日志文件
- 动态切换日志级别
- Http 请求信息跟踪
- 其他功能点……
创建一个 Spring Boot 项目,用于展示各个服务中的监控信息,加上 Spring Boot Admin 的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>2.0.2</version>
</dependency>创建一个启动类:
@EnableAdminServer
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
启动程序,访问 Web 地址 http://localhost:9090 就可以看到主页面了。
十四、Spring Cache缓存数据
一般的缓存逻辑都是首先判断缓存中是否有数据,有就获取数据返回,没有就从数据库中查数据,然后缓存进去,再返回。
首先这种方式在逻辑上是肯定没有问题的,大部分人也都是这么用的,不过当这种代码充满整个项目的时候,看起来就非常别扭了,感觉有点多余,不过通过 Spring Cache 就能解决这个问题。我们不需要关心缓存的逻辑,只需要关注从数据库中查询数据,将缓存的逻辑交给框架来实现。
Spring Cache 利用注解方式来实现数据的缓存,还具备相当的灵活性,能够使用 SpEL(Spring Expression Language)来定义缓存的 key,还能定义多种条件判断。
常用的注解有 @Cacheable、@CachePut、@CacheEvict。
- @Cacheable:用于查询的时候缓存数据。
- @CachePut:用于对数据修改的时候修改缓存中的数据。
- @CacheEvict:用于对数据删除的时候清除缓存中的数据。
@Cacheable(value="get", key="#id")
public Person get(String id) {
return findById(id);
}@Cacheable 中的 value 我们可以定义成与方法名称一样。标识这个方法的缓存 key,会在 Redis 中存储一个 Zset,Zset 的 key 就是我们定义的 value 的值,Zset 中会存储具体的每个缓存的 key,也就是当调用 get("1001") 的时候,Zset 中就会存储 1001,同时 Redis 中会有一个单独的 String 类型的数据,Key 是 1001。
十五、微服务之间的最佳调用方式
在微服务架构中,需要调用很多服务才能完成一项功能。服务之间如何互相调用就变成微服务架构中的一个关键问题。
服务调用有两种方式:
- 一种是事件驱动(Event-driven)方式,也就是发消息方式
- 另一种是RPC方式
消息方式是松耦合方式,比紧耦合的RPC方式要优越,但RPC方式如果用在适合的场景也有它的一席之地。
事件驱动(Event-driven)方式
举一个购物的例子。用户选好商品之后进行“Checkout”,生成“Order”,然后需要“payment”,再从“Inventory”取货,最后由“Shipment”发货,它们每一个都是微服务。这个例子用RPC方式和事件通知方式都可以完成。
当用RPC方式时,由“Order”服务调用其他几个服务来完成整个功能。用事件通知方式时,“Checkout”服务完成之后发送“Order Placed”消息,“Payment”服务收到消息,接收用户付款,发送“Payment received”消息。“Inventory”服务收到消息,从仓库里取货,并发送“Goods fetched”消息。“Shipment”服务得到消息,发送货物,并发送“Goods shipped”消息。
对这个例子来讲,使用事件驱动是一个不错的选择,因为每个服务发消息之后它不需要任何反馈,这个消息由下一个模块接收来完成下一步动作,时间上的要求也比上一个要宽松。用事件驱动的好处是降低了耦合度,坏处是你现在不能在程序里找到整个购物过程的步骤。
RPC方式
RPC的方式就是远程函数调用,像RESTFul,gRPC, DUBBO 都是这种方式。它一般是同步的,可以马上得到结果。在实际中,大多数应用都要求立刻得到结果,这时同步方式更有优势,代码也更简单。
补充一:Rest与RPC区别?
什么是REST?
REST是一种架构风格,指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。REST规范把所有内容都视为资源,网络上一切皆资源。REST并没有创造新的技术,组件或服务,只是使用Web的现有特征和能力。 可以完全通过HTTP协议实现,使用 HTTP 协议处理数据通信。
REST架构对资源的操作包括获取、创建、修改和删除正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。
什么是RPC?
远程(过程)方法调用,就是像调用本地方法一样调用远程方法。
大型互联网公司系统都由成千上万大大小小的服务组成,各服务部署在不同的机器上,由不同的团队负责。这时就会遇到两个问题:1)要搭建一个新服务,免不了需要依赖他人的服务,而现在他人的服务都在远端,怎么调用?2)其它团队要使用我们的新服务,我们的服务该怎么发布以便他人调用?
1 如何调用他人的远程服务?
由于各个服务部署在不同机器,服务间的调用涉及到网络通信过程,如果服务消费方每调用一个服务都要写一坨网络通信相关的代码,不仅使用复杂而且极易出错。
如果有一种方式能让我们像调用本地服务一样调用远程服务,而让调用者对网络通信这些细节透明,那么将大大提高生产力。这种方式其实就是RPC(Remote Procedure Call Protocol),在各大互联网公司中被广泛使用,如阿里巴巴的hsf、dubbo(开源)、Facebook的thrift(开源)、Google grpc(开源)、Twitter的finagle等。

1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
RPC的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
总结来说RPC的调用过程就是:
- client 会调用本地动态代理 proxy
- 这个代理会将调用通过协议转序列化字节流
- 通过 netty 网络框架,将字节流发送到服务端
- 服务端在受到这个字节流后,会根据协议,反序列化为原始的调用,利用反射原理调用服务方提供的方法
- 如果请求有返回值,又需要把结果根据协议序列化后,再通过 netty 返回给调用方
1.1 怎么做到透明化远程服务调用?
使用代理!对java来说,代理有两种方式:1) jdk 动态代理;2)字节码生成。尽管字节码生成方式实现的代理更为强大和高效,但代码不易维护,大部分公司实现RPC框架时还是选择动态代理方式。那么动态代理方式怎么做到让用户像以本地调用方式调用远程服务呢?我们需要实现RPCProxyClient代理类,代理类的invoke方法中封装了与远端服务通信的细节,消费方首先从RPCProxyClient获得服务提供方的接口,当执行helloWorldService.sayHello("test")方法时就会调用invoke方法。
1.2 怎么对消息进行编码和解码?
1.2.1 确定消息数据结构
通信的第一步就是要确定客户端和服务端相互通信的消息结构。客户端的请求消息结构一般需要包括以下内容:
1)接口名称
在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了;
2)方法名
一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;
3)参数类型&参数值
参数类型有很多,比如有bool、int、long、double、string、map、list,甚至如struct(class);
以及相应的参数值;
4)超时时间
5)requestID,标识唯一请求id,在下面一节会详细描述requestID的用处。
同理服务端返回的消息结构一般包括以下内容。
1)返回值
2)状态code
3)requestID
1.2.2 序列化
一旦确定了消息的数据结构后,下一步就是要考虑序列化与反序列化了。
什么是序列化?序列化就是将数据结构或对象转换成二进制串的过程,也就是编码的过程。
什么是反序列化?将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
为什么需要序列化?转换为二进制串后才好进行网络传输嘛
现如今序列化的方案越来越多,每种序列化方案都有优点和缺点,它们在设计之初有自己独特的应用场景,那到底选择哪种呢?从RPC的角度上看,主要看三点:1)通用性,比如是否能支持Map等复杂的数据结构;2)性能,包括时间复杂度和空间复杂度,由于RPC框架将会被公司几乎所有服务使用,如果序列化上能节约一点时间,对整个公司的收益都将非常可观,同理如果序列化上能节约一点内存,网络带宽也能省下不少;3)可扩展性,对互联网公司而言,业务变化飞快,如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
目前互联网公司广泛使用Protobuf、Thrift、Avro等成熟的序列化解决方案来搭建RPC框架,这些都是久经考验的解决方案。
1.3 通信
消息数据结构被序列化为二进制流后,下一步就要进行网络通信。目前网络通信有两种IO模型:1)BIO;2)NIO。一般RPC框架需要支持这两种IO模型,关于两种模型的原理可以参考:一个故事讲清楚NIO。
如何实现RPC的IO通信框架呢?1)使用java nio方式自研,这种方式较为复杂,而且很有可能出现隐藏bug;2)基于mina,mina在早几年比较火热,不过这些年版本更新缓慢;3)基于netty,现在很多RPC框架都直接基于netty这一IO通信框架,比如阿里巴巴的HSF。
1.4 消息里为什么要有requestID?
如果使用netty channel.writeAndFlush()方法来发送消息二进制串,这个方法调用后对于整个远程调用(从发出请求到接收到结果)来说是一个异步的,即对于当前线程来说,将请求发送出来后,线程就可以往后执行了,至于服务端的结果,是服务端处理完成后,再以消息的形式发送给客户端的。于是这里出现以下两个问题:
1)怎么让当前线程“暂停”,等结果回来后,再向后执行?
2)如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是随机的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
如下图所示,线程A和线程B同时向client socket发送请求requestA和requestB,socket先后将requestB和requestA发送至server,而server可能将responseA先返回,尽管requestA请求到达时间更晚。我们需要一种机制保证responseA丢给ThreadA,responseB丢给ThreadB。

怎么解决呢?
1)client线程每次通过socket调用一次远程接口前,生成一个唯一的ID,即requestID(requestID必需保证在一个Socket连接里面是唯一的),一般常常使用AtomicLong从0开始累计数字生成唯一ID;
2)将处理结果的回调对象callback,存放到全局ConcurrentHashMap里面put(requestID, callback);
3)当线程调用channel.writeAndFlush()发送消息后,紧接着执行callback的get()方法试图获取远程返回的结果。在get()内部,则使用synchronized获取回调对象callback的锁,再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
4)服务端接收到请求并处理后,将response结果(此结果中包含了前面的requestID)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到requestID,再从前面的ConcurrentHashMap里面get(requestID),从而找到callback对象,再用synchronized获取callback上的锁,将方法调用结果设置到callback对象里,再调用callback.notifyAll()唤醒前面处于等待状态的线程。
所以,RPC框架要做到的最基本的三件事:
1、服务端如何确定客户端要调用的函数;
在远程调用中,客户端和服务端分别维护一个【ID->函数】的对应表, ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,附上这个ID,服务端通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
2、如何进行序列化和反序列化;
客户端和服务端交互时将参数或结果转化为字节流在网络中传输,那么数据转化为字节流的或者将字节流转换成能读取的固定格式时就需要进行序列化和反序列化,序列化和反序列化的速度也会影响远程调用的效率。
3、如何进行网络传输(选择何种网络协议);
多数RPC框架选择TCP作为传输协议,也有部分选择HTTP。如gRPC使用HTTP2。不同的协议各有利弊。TCP更加高效,而HTTP在实际应用中更加的灵活。
RPC与HTTP、REST的区别:
RPC远程服务调用(Remote Procedure Call),加上Protocol后可以称为远程过程调用协议,可以用不同的语言实现,可以借用HTTP协议或者其他协议来实现,一般都是通过基于TCP/IP的自定义协议实现。比如Feign。
HTTP协议和TCP/IP协议有什么关系呢?HTTP是应用层协议,TCP/IP是传输层协议。HTTP协议请求中会包含很多内容,传输效率要低,一般RPC实现都不采用HTTP协议;RPC采用自定义的TCP协议,可以精简报文格式,一般都是采用二进制形式,客户端和服务端采用统一的序列化和反序列化方式保持数据统一,效率更高,所以一般企业内部通信都是采用自定义TCP的RPC协议,传输效率高。
REST是一种架构风格,是基于HTTP协议的,可以理解称一种API的规范,比如查询都是GET请求,新增都是POST,修改是PUT,删除是DELETE
6种微服务RPC框架:
一类是跟某种特定语言平台绑定的,另一类是与语言无关即跨语言平台的。
跟语言平台绑定的开源 RPC 框架主要有下面几种。
- Dubbo:国内最早开源的 RPC 框架,由阿里巴巴公司开发并于 2011 年末对外开源,仅支持 Java 语言。
- Motan:微博内部使用的 RPC 框架,于 2016 年对外开源,仅支持 Java 语言。
- Tars:腾讯内部使用的 RPC 框架,于 2017 年对外开源,仅支持 C++ 语言。
- Spring Cloud:国外 Pivotal 公司 2014 年对外开源的 RPC 框架,仅支持 Java 语言
而跨语言平台的开源 RPC 框架主要有以下几种。
- gRPC:Google 于 2015 年对外开源的跨语言 RPC 框架,支持多种语言。
- Thrift:最初是由 Facebook 开发的内部系统跨语言的 RPC 框架,2007 年贡献给了 Apache 基金,成为 Apache 开源项目之一,支持多种语言。
其中,Spring Cloud 利用 Spring Boot 特性整合了开源行业中优秀的组件,整体对外提供了一套在微服务架构中服务治理的解决方案。
只支持 Java 语言平台,它的架构图可以用下面这张图来描述。
由此可见,Spring Cloud 微服务架构是由多个组件一起组成的,各个组件的交互流程如下。
请求统一通过 API 网关 Zuul 来访问内部服务,先经过 Token 进行安全认证。
通过安全认证后,网关 Zuul 从注册中心 Eureka 获取可用服务节点列表。
从可用服务节点中选取一个可用节点,然后把请求分发到这个节点。
整个请求过程中,Hystrix 组件负责处理服务超时熔断,Turbine 组件负责监控服务间的调用和熔断相关指标,Sleuth 组件负责调用链监控,ELK 负责日志分析。

REST与RPC应用场景
REST和RPC都常用于微服务架构中。
- 1、HTTP相对更规范,更标准,更通用,无论哪种语言都支持http协议。如果你是对外开放API,例如开放平台,外部的编程语言多种多样,你无法拒绝对每种语言的支持,现在开源中间件,基本最先支持的几个协议都包含RESTful。
- 2、 RPC 框架作为架构微服务化的基础组件,它能大大降低架构微服务化的成本,提高调用方与服务提供方的研发效率,屏蔽跨进程调用函数(服务)的各类复杂细节。让调用方感觉就像调用本地函数一样调用远端函数、让服务提供方感觉就像实现一个本地函数一样来实现服务。
REST调用及测试都很方便,RPC就显得有点繁琐,但是RPC的效率是毋庸置疑的,所以建议在多系统之间的内部调用采用RPC。对外提供的服务,Rest更加合适。
企业内部的微服务数据传输都是采用自定义的rpc实现的,传输效率更高;http一般是面向用户的,规范统一,用户使用起来方便,直接通过浏览器地址访问接口即可。
2 如何发布自己的服务?
如何让别人使用我们的服务呢?
有同学说很简单嘛,告诉使用者服务的IP以及端口就可以了啊。确实是这样,这里问题的关键在于是自动告知还是人肉告知。
人肉告知的方式:如果你发现你的服务一台机器不够,要再添加一台,这个时候就要告诉调用者我现在有两个ip了,你们要轮询调用来实现负载均衡;调用者咬咬牙改了,结果某天一台机器挂了,调用者发现服务有一半不可用,他又只能手动修改代码来删除挂掉那台机器的ip。现实生产环境当然不会使用人肉方式。
有没有一种方法能实现自动告知,即机器的增添、剔除对调用方透明,调用者不再需要写死服务提供方地址?当然可以,现如今Redis、Zookeeper、Consul、Etcd等被广泛用于实现服务自动注册与发现功能!
补充二:Zookeeper 选举机制?
选择机制中的概念:
1、Serverid:服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
2、Zxid:数据ID
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
3、Epoch:逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
4、Server状态:选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
选举流程简述:
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,默认是采用投票数大于半数则胜出的逻辑,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
Server状态:选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
选举流程详述:
一、首先开始选举阶段,每个Server读取自身的zxid。
二、发送投票信息
a、首先,每个Server第一轮都会投票给自己。
b、投票信息包含 :所选举leader的Serverid,Zxid,Epoch。Epoch会随着选举轮数的增加而递增。
三、接收投票信息
1、如果服务器B接收到服务器A的数据(服务器A处于选举状态(LOOKING 状态)
1)首先,判断逻辑时钟值:
a)如果发送过来的逻辑时钟Epoch大于目前的逻辑时钟。首先,更新本逻辑时钟Epoch,同时清空本轮逻辑时钟收集到的来自其他server的选举数据。然后,判断是否需要更新当前自己的选举leader Serverid。判断规则rules judging:保存的zxid最大值和leader Serverid来进行判断的。先看数据zxid,数据zxid大者胜出;其次再判断leader Serverid,leader Serverid大者胜出;然后再将自身最新的选举结果(也就是上面提到的三种数据(leader Serverid,Zxid,Epoch)广播给其他server)
b)如果发送过来的逻辑时钟Epoch小于目前的逻辑时钟。说明对方server在一个相对较早的Epoch中,这里只需要将本机的三种数据(leader Serverid,Zxid,Epoch)发送过去就行。
c)如果发送过来的逻辑时钟Epoch等于目前的逻辑时钟。再根据上述判断规则rules judging来选举leader ,然后再将自身最新的选举结果(也就是上面提到的三种数据(leader Serverid,Zxid,Epoch)广播给其他server)。
2)其次,判断服务器是不是已经收集到了所有服务器的选举状态:若是,根据选举结果设置自己的角色(FOLLOWING还是LEADER),退出选举过程就是了。
最后,若没有收到没有收集到所有服务器的选举状态:也可以判断一下根据以上过程之后最新的选举leader是不是得到了超过半数以上服务器的支持,如果是,那么尝试在200ms内接收一下数据,如果没有新的数据到来,说明大家都已经默认了这个结果,同样也设置角色退出选举过程。
2、 如果所接收服务器A处在其它状态(FOLLOWING或者LEADING)。
a)逻辑时钟Epoch等于目前的逻辑时钟,将该数据保存到recvset。此时Server已经处于LEADING状态,说明此时这个server已经投票选出结果。若此时这个接收服务器宣称自己是leader, 那么将判断是不是有半数以上的服务器选举它,如果是则设置选举状态退出选举过程。
b) 否则这是一条与当前逻辑时钟不符合的消息,那么说明在另一个选举过程中已经有了选举结果,于是将该选举结果加入到outofelection集合中,再根据outofelection来判断是否可以结束选举,如果可以也是保存逻辑时钟,设置选举状态,退出选举过程。
补充三:Ribbon和Feign的区别
1.启动类使用的注解不同,Ribbon 用的是@RibbonClient,Feign 用的是@EnableFeignClients。
2.服务的指定位置不同,Ribbon 是在@RibbonClient 注解上声明,Feign 则是在定义抽象方法的接口中使用@FeignClient 声明。
3.Ribbon客户端的负载均衡器 ,Feign服务端的负载均衡
Feign
feign封装了ribbon,Feign 是在 Ribbon 的基础上进行了一次改进,是一个使用起来更加方便的 HTTP 客户端。采用接口的方式, 只需要创建一个接口,然后在上面添加注解即可 ,将需要调用的其他服务的方法定义成抽象方法即可, 不需要自己构建 http 请求。然后就像是调用自身工程的方法调用,而感觉不到是调用远程方法,使得编写 客户端变得非常容易。
Ribbon
Ribbon 是一个基于 HTTP 和 TCP 客户端 的负载均衡的工具。它可以 在客户端 配置 RibbonServerList(服务端列表),使用 HttpClient 或 RestTemplate 模拟 http 请求,步骤相当繁琐。
补充四:zuul和gateway的区别
Gateway 的工作原理跟 Zuul 的差不多,最大的区别就是 Gateway 的 Filter 只有 pre 和 post 两种。Gateway 依赖 Spring Boot 和 Spring WebFlux,基于 Netty 运行。它不能在传统的 servlet 容器中工作,也不能构建成 war 包。
补充五:过滤器和拦截器的区别
1、过滤器 (Filter)
过滤器有哪些作用?
可以验证客户是否来自可信的网络,可以对客户提交的数据进行重新编码, 可以从系统里获得配置的信息,可以过滤掉客户的某些不应该出现的词汇,可以验证用户是否登录,可以验证客户的浏览器是否支持当前的应用,可以记录系统的日志等等。
过滤器的配置比较简单,直接实现Filter 接口即可,也可以通过@WebFilter注解实现对特定URL拦截,看到Filter 接口中定义了三个方法。
init():该方法在容器启动初始化过滤器时被调用,它在Filter的整个生命周期只会被调用一次。「注意」:这个方法必须执行成功,否则过滤器会不起作用。
doFilter():容器中的每一次请求都会调用该方法,FilterChain用来调用下一个过滤器Filter。
destroy(): 当容器销毁 过滤器实例时调用该方法,一般在方法中销毁或关闭资源,在过滤器Filter的整个生命周期也只会被调用一次
过滤器的生命周期:
tomcat服务器启动时创建 --> 初始化(init) --> 执行(doFilter)[每次请求/响应都执行] --> 销毁(destroy)(服务器正常关闭时销毁)
@Component
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Filter 前置");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("Filter 处理中");
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
System.out.println("Filter 后置");
}
}2、拦截器 (Interceptor)
拦截器它是链式调用,一个应用中可以同时存在多个拦截器Interceptor, 一个请求也可以触发多个拦截器 ,而每个拦截器的调用会依据它的声明顺序依次执行。首先编写一个简单的拦截器处理类,请求的拦截是通过HandlerInterceptor 来实现,看到HandlerInterceptor 接口中也定义了三个方法。
preHandle():这个方法将在请求处理之前进行调用。「注意」:如果该方法的返回值为false,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。
postHandle():只有在preHandle()方法返回值为true时才会执行。会在Controller 中的方法调用之后,DispatcherServlet 返回渲染视图之前被调用。 「有意思的是」:postHandle()方法被调用的顺序跟preHandle()是相反的,先声明的拦截器preHandle()方法先执行,而postHandle()方法反而会后执行。
afterCompletion():只有在preHandle()方法返回值为true时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。
@Component
public class MyInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("Interceptor 前置");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("Interceptor 处理中");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("Interceptor 后置");
}
}
将自定义好的拦截器处理类注册到Spring容器,并通过addPathPatterns、excludePathPatterns等属性设置需要拦截或需要排除的 URL。
@Configuration
public class MyMvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**");
registry.addInterceptor(new MyInterceptor1()).addPathPatterns("/**");
}
}Filter 和 Interceptor 的不同:
过滤器 和 拦截器 均体现了AOP的编程思想,都可以实现诸如日志记录、登录鉴权等功能,但二者的不同点也是比较多的,接下来一一说明。
1、实现原理不同
过滤器 是基于函数回调的,拦截器 则是基于Java的反射机制(动态代理)实现的。
2、使用范围不同
过滤器 实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter 的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。
而拦截器(Interceptor) 它是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。不仅能应用在web程序中,也可以用于Application、Swing等程序中。
3、触发时机不同
过滤器 和 拦截器的触发时机也不同。

过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
4、拦截的请求范围不同
在上边我们已经同时配置了过滤器和拦截器,再建一个Controller接收请求测试一下。
@Controller
@RequestMapping()
public class Test {
@RequestMapping("/test1")
@ResponseBody
public String test1(String a) {
System.out.println("我是controller");
return null;
}
}
项目启动过程中发现,过滤器的init()方法,随着容器的启动进行了初始化。

此时浏览器发送请求,F12 看到居然有两个请求,一个是我们自定义的 Controller 请求,另一个是访问静态图标资源的请求。

看到控制台的打印日志如下:
执行顺序 :
Filter 处理中->Interceptor 前置->我是controller->Interceptor 处理中->Interceptor 处理后
5、注入Bean情况不同
在实际的业务场景中,应用到过滤器或拦截器,为处理业务逻辑难免会引入一些service服务。
下边我们分别在过滤器和拦截器中都注入service,看看有什么不同?
@Component
public class TestServiceImpl implements TestService {
@Override
public void a() {
System.out.println("我是方法A");
}
}
过滤器中注入service,发起请求测试一下 ,日志正常打印出“我是方法A”。
@Autowired
private TestService testService;
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("Filter 处理中");
testService.a();
filterChain.doFilter(servletRequest, servletResponse);
}
Filter 处理中
我是方法A
Interceptor 前置
我是controller
Interceptor 处理中
Interceptor 后置在拦截器中注入service,发起请求测试一下 会报错!debug跟一下发现注入的service是Null。

这是因为加载顺序导致的问题,拦截器加载的时间点在springcontext之前,而Bean又是由spring进行管理。
解决方案也很简单,我们在注册拦截器之前,先将Interceptor 手动进行注入。「注意」:在registry.addInterceptor()注册的是getMyInterceptor() 实例。
@Configuration
public class MyMvcConfig implements WebMvcConfigurer {
@Bean
public MyInterceptor getMyInterceptor(){
System.out.println("注入了MyInterceptor");
return new MyInterceptor();
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(getMyInterceptor()).addPathPatterns("/**");
}
}
6、控制执行顺序不同
实际开发过程中,会出现多个过滤器或拦截器同时存在的情况,不过,有时我们希望某个过滤器或拦截器能优先执行,就涉及到它们的执行顺序。
过滤器用@Order注解控制执行顺序,通过@Order控制过滤器的级别,值越小级别越高越先执行。
@Order(Ordered.HIGHEST_PRECEDENCE)
@Component
public class MyFilter2 implements Filter {
拦截器默认的执行顺序,就是它的注册顺序,也可以通过Order手动设置控制,值越小越先执行。
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor2()).addPathPatterns("/**").order(2);
registry.addInterceptor(new MyInterceptor1()).addPathPatterns("/**").order(1);
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**").order(3);
}
Interceptor1 前置
Interceptor2 前置
Interceptor 前置
我是controller
Interceptor 处理中
Interceptor2 处理中
Interceptor1 处理中
Interceptor 后置
Interceptor2 处理后
Interceptor1 处理后
看到输出结果发现,先声明的拦截器 preHandle() 方法先执行,而postHandle()方法反而会后执行。postHandle() 方法被调用的顺序跟 preHandle() 居然是相反的!如果实际开发中严格要求执行顺序,那就需要特别注意这一点。
「那为什么会这样呢?」 得到答案就只能看源码了,我们要知道controller 中所有的请求都要经过核心组件DispatcherServlet路由,都会执行它的 doDispatch() 方法,而拦截器postHandle()、preHandle()方法便是在其中调用的。
补充六:什么是灰度发布,有哪些好处?
灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。
在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。灰度期:灰度发布开始到结束期间的这一段时间,称为灰度期。
好处:
- 提前获得目标用户的使用反馈;
- 根据反馈结果,做到查漏补缺;
- 发现重大问题,可回滚“旧版本”;
- 补充完善产品不足;
- 快速验证产品的 idea。
补充七:服务降级是什么?Spring Cloud如何实现?
当访问量剧增,服务出现问题时,需要做一些处理,比如服务降级。服务降级就是将某些服务停掉或者不进行业务处理,释放资源来维持主要服务的功能。
某电商网站在搞活动时,活动期间压力太大,如果再进行下去,整个系统有可能挂掉,这个时候可以释放掉一些资源,将一些不那么重要的服务采取降级措施,比如登录、注册。登录服务停掉之后就不会有更多的用户抢购,同时释放了一些资源,登录、注册服务就算停掉了也不影响商品抢购。
服务降级有很多种方式,最好的方式就是利用 Docker 来实现。当需要对某个服务进行降级时,直接将这个服务所有的容器停掉,需要恢复的时候重新启动就可以了。
还有就是在 API 网关层进行处理,当某个服务被降级了,前端过来的请求就直接拒绝掉,不往内部服务转发,将流量挡回去。
在 Zuul 中对服务进行动态降级,结合配置中心来做。
补充八:什么是CAP理论?
C:强一致性(consistency),A:可用性,P:分区容错性
CAP说的是一个分布式系统不可能同时满足这三个特性,一般P特性是要满足的,根据NoSql数据库分成了AP、CP原则。
Eureka就符合AP原则,Zk则符合CP。
zk在选举期间整个集群是不可用的,来保证系统的一致性;而Eureka各节点是平等的,几个节点挂掉不会影响系统的可用性,剩余的节点继续服务。
补充九:Nacos与eureka注册中心对比
Nacos与eureka注册中心对比:

服务配置中心对比:

使用Nacos代替Eureka和apollo,主要理由为:
相比与Eureka:
(1)Nacos具备服务优雅上下线和流量管理(API+后台管理页面),而Eureka的后台页面仅供展示,需要使用api操作上下线且不具备流量管理功能。
(2)从部署来看,Nacos整合了注册中心、配置中心功能,把原来两套集群整合成一套,简化了部署维护
(3)从长远来看,Eureka开源工作已停止,后续不再有更新和维护,而Nacos在以后的版本会支持SpringCLoud+Kubernetes的组合,填补 2 者的鸿沟,在两套体系下可以采用同一套服务发现和配置管理的解决方案,这将大大的简化使用和维护的成本。同时来说,Nacos 计划实现 Service Mesh,是未来微服务的趋势
(4)从伸缩性和扩展性来看Nacos支持跨注册中心同步,而Eureka不支持,且在伸缩扩容方面,Nacos比Eureka更优(nacos支持大数量级的集群)。
(5)Nacos具有分组隔离功能,一套Nacos集群可以支撑多项目、多环境。
相比于apollo
(1) Nacos部署简化,Nacos整合了注册中心、配置中心功能,且部署相比apollo简单,方便管理和监控。
(2) apollo容器化较困难,Nacos有官网的镜像可以直接部署,总体来说,Nacos比apollo更符合KISS原则
(3)性能方面,Nacos读写tps比apollo稍强一些
结论:使用Nacos代替Eureka和apollo
补充十、为什么有人说 Eureka 比 Zookeeper 更适合作为注册中心呢?
主要是因为 Eureka 是基于 AP 原则构建的,而 ZooKeeper 是基于 CP 原则构建的。
在分布式系统领域有个著名的 CAP 定理,即 C 为数据一致性;A 为服务可用性;P 为服务对网络分区故障的容错性。这三个特性在任何分布式系统中都不能同时满足,最多同时满足两个。
Zookeeper 有一个 Leader,而且在这个 Leader 无法使用的时候通过 Paxos(ZAB)算法选举出一个新的 Leader。这个 Leader 的任务就是保证写数据的时候只向这个 Leader 写入,Leader 会同步信息到其他节点。通过这个操作就可以保证数据的一致性。
总而言之,想要保证 AP 就要用 Eureka,想要保证 CP 就要用 Zookeeper。
Dubbo 中大部分都是基于 Zookeeper 作为注册中心的。Spring Cloud 中当然首选 Eureka。
补充十、application.yml和bootstrap.yml的区别
bootstrap.yml 用来程序引导时执行,应用于更加早期配置信息读取。可以理解成系统级别的一些参数配置,这些参数一般是不会变动的。一旦bootStrap.yml 被加载,则内容不会被覆盖。
application.yml 可以用来定义应用级别的, 应用程序特有配置信息,可以用来配置后续各个模块中需使用的公共参数等。
启动上下文时,Spring Cloud 会创建一个 Bootstrap Context,作为 Spring 应用的 Application Context 的父上下文。初始化的时候,Bootstrap Context 负责从外部源加载配置属性并解析配置。这两个上下文共享一个从外部获取的 Environment。Bootstrap 属性有高优先级,默认情况下,它们不会被本地配置覆盖。也就是说如果加载的 application.yml 的内容标签与 bootstrap 的标签一致,application 也不会覆盖 bootstrap,而 application.yml 里面的内容可以动态替换。
bootstrap.yml典型的应用场景:
- 当使用 Spring Cloud Config Server 配置中心时,这时需要在 bootstrap.yml 配置文件中指定 spring.application.name 和 spring.cloud.config.server.git.uri,添加连接到配置中心的配置属性来加载外部配置中心的配置信息
- 一些固定的不能被覆盖的属性
- 一些加密/解密的场景
补充十一、服务降级和服务熔断的区别
- 熔断的目的是当A服务模块中的某块程序出现故障后为了不影响其他客户端的请求而做出的及时回应。降级的目的是为了解决整体项目的压力,而牺牲掉某一服务模块而采取的措施。
- 触发原因不一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始。)
补充十二、springboot配置优先级
(1)多源
Spring Boot 不单单从 application.properties 获取配置,所以我们可以在程序中多种设置配置属性。按照以下列表的优先级排列:
- 1.命令行参数
- 2.java:comp/env 里的 JNDI 属性
- 3.JVM 系统属性
- 4.操作系统环境变量
- 5.RandomValuePropertySource 属性类生成的 random.* 属性
- 6.应用以外的 application.properties(或 yml)文件
- 7.打包在应用内的 application.properties(或 yml)文件
- 8.在应用 @Configuration 配置类中,用 @PropertySource 注解声明的属性文件
- 9.SpringApplication.setDefaultProperties 声明的默认属性
可见,命令行参数优先级最高。这个可以根据这个优先级,可以在测试或生产环境中快速地修改配置参数值,而不需要重新打包和部署应用。
还有第 6 点,根据这个在多 moudle 的项目中,比如常见的项目分 api 、service、dao 等 moudles,往往会加一个 deploy moudle 去打包该业务各个子 moudle,应用以外的配置优先。
(2)不同目录
SpringBoot应用程序在启动时会遵循下面的顺序进行加载配置文件:
- 类路径下的配置文件
- 类路径内config子目录的配置文件
- 当前项目根目录下的配置文件
- 当前项目根目录下config子目录的配置文件
示例项目配置文件存放结构如下所示:
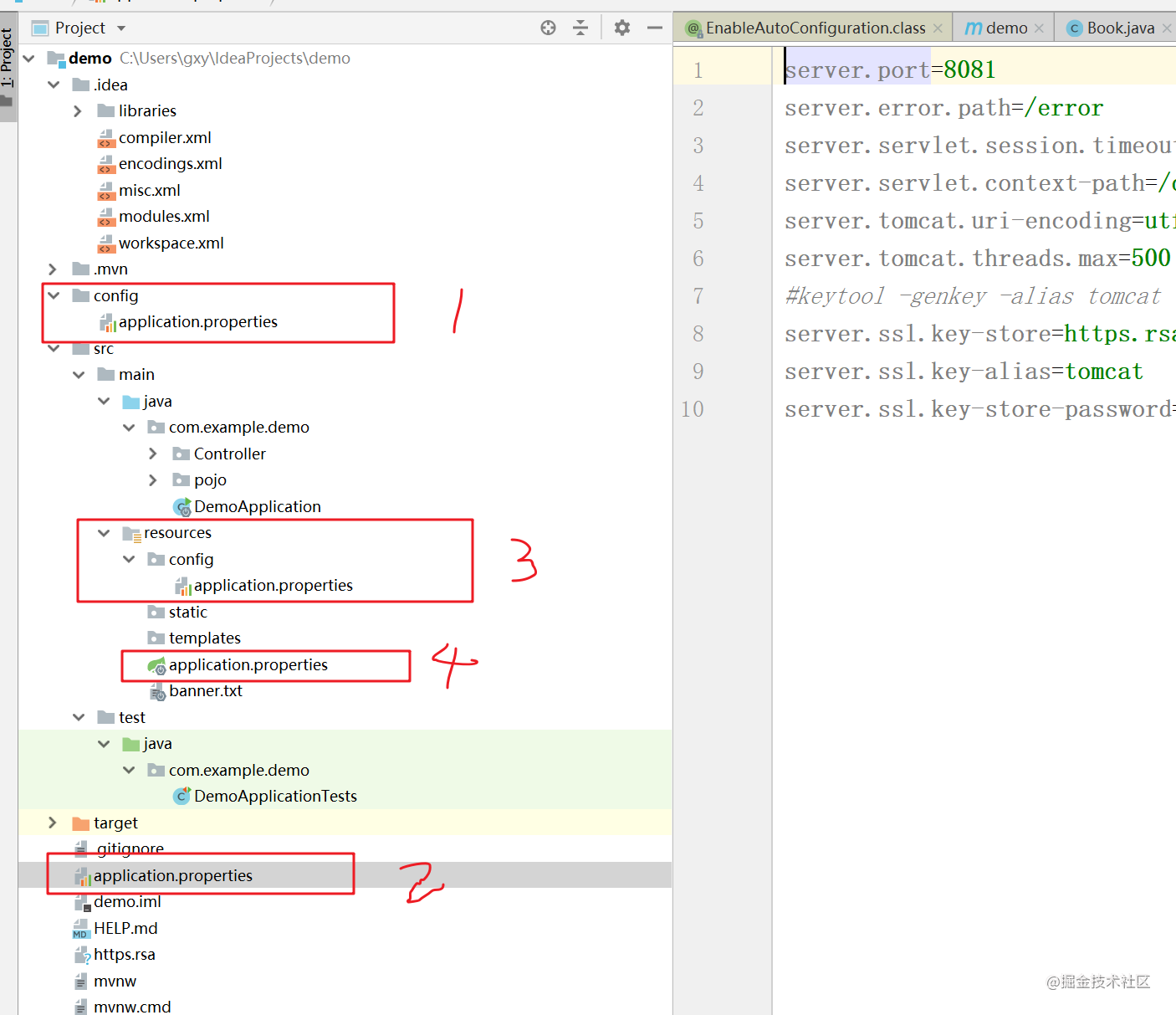
启动时加载配置文件顺序:1 > 2 > 3 > 4
SpringBoot配置文件存在一个特性,优先级较高的配置加载顺序比较靠后,相同名称的配置优先级较高的会覆盖掉优先级较低的内容。覆盖顺序为:4 > 3 > 2 > 1。
加载与优先是相反的。
(3)不同文件形式
项目内可以同时存在application.properties、application.yml两个文件,经过测试发现,properties优先级会高一些,相同名称的配置,会将yml内的配置覆盖掉。
补充十三、并发量、QPS 和TPS区别
QPS: 每秒钟接收的request 数量
并发数: 系统中同时存在的请求数(或者同时访问服务器站点的连接数)
TPS :每秒处理的查询量
并发量 = QPS * 平均响应时间
典型案例:一个OA签到系统,某公司假设有600个人进行上班打卡,8:00为签到时间,
从7:50至8:00这10分钟之内,600个人访问此系统,假设每人访问签到一次为1分钟。
请问:此OA系统的QPS是多少?并发数为多少?
首先确定平均响应时间,平均响应时间 = 1*60 = 60秒
QPS = 600/(10*60)=1 人/秒
并发量 = QPS * 平均响应时间 = 1*60 = 60人
补充十四、怎么理解 并发数?
并发数是指同时访问服务器站点的连接数。
在实际工作中,经常发现很多人对并发数有误解。
比如说我们系统有10w活跃用户,所以系统必须要支持10w并发;比如压测报告里写某个接口支持 50 并发,客户就会反问难道系统只支持50用户同时访问?性能是不是太差了!
问出上面问题的人,大多数都存在一个理解上的误区,认为性能测试中的并发数=并发用户数。
并发其实有两种:用户端并发和服务端并发。
具体有什么区别呢?给大家举一个例子。
一般来说,抢购和秒杀服务是并发数最高的项目类型,比如某网站8点开始抢购某商品,抢购系统部署在北京的某个机房里。所有的用户都是通过浏览器或者APP来进行商品的抢购。在开始抢购之前,已经有10w个用户预约了该商品,所以我们可以预测到,8点的时候会有将近10w人(极端情况下)同时去进行抢购。那么这个时候,意味着10w个客户端同时开始处理用户的抢购操作。
客户端(APP或浏览器)往往是需要先进行一些逻辑处理,才会把抢购请求发送到服务端。但是客户端运行设备和环境是不同的。
有人用的是iPhone XS Max;有人用的是金立双卡双待语音王;有人用的是最新款的MacBook Pro;有人用的是小霸王学习机。不同的客户端环境,运行速度是有很大差别的,所以即便有10w人同时在8点开始点击抢购,等待客户端向服务端发起抢购请求时,同一时刻发出的请求已经不足10w了,可能只剩下9w了。
然而残酷的竞争才刚刚开始,客户端把请求发送出去后,需要通过漫长的网络传输到位于北京机房的服务器上。这个时候更大的差异出现了。参加抢购的用户分布的全国各地,网络制式也各有不同,4G/3G、联通/电信宽带,50M/100M的带宽,比起客户端设备之间几毫秒的差距,不同环境下网络的延迟差距可能有几十毫秒。
在服务端来看,因为客户端设备的差异和网络的延迟,10w个并发请求,并不是同时到达服务端的,而且会在一段时间内陆续到达。假设在100ms内全部到达,并且认为同一毫秒到达服务器的请求属于同一时刻,那么服务端同一时刻处理的并发请求,也就1000个左右。
从上面的例子里大家也都看出来了,用户端并发和服务端并发是有着巨大的差异的,用户端并发>服务端并发。具体多少倍的差异无法计算,因为用户端的环境是无法预估的。但是可以肯定的是,这个差距肯定是巨大的。
从另外一个角度来看,在上述的例子中,假如网络延迟为0,那么用户端有多少并发同时请求,在服务端同时接受到的几乎就是多少并发。在这种情况下,用户端并发=服务端并发
所以日常在做性能测试过程中,为了降低网络延迟,客户端压力机和项目服务器都在同一个局域网中,一般都在同一个机房,这样网络的延迟是<1ms的。几乎可以认为是没有延迟的,在客户端压测工具上设置了50并发,那么在服务端也是50并发。
压测时系统支持50并发,是指服务端支持50并发,并不是只支持50个用户同时去访问。而是远远大于50个用户。
这也从另一个方面说明了一个问题,并发数是一个重要的指标,但是在性能测试中,不需要过分关注并发数的多少,而更应该关注处理的业务量(即TPS),只要系统的TPS足够高,处理业务的时间足够短,哪怕同一时刻来再多的并发请求(只要不超过软硬件限制),服务器也能支撑住。
补充十五、soa和微服务的区别
其实面向服务的架构(SOA)已经可以解决大部分企业的需求了,那么我们为什么要研究微服务呢?先说说它们的区别?
- 微服务架构强调业务系统需要彻底的组件化和服务化,一个组件就是一个产品,可以独立对外提供服务
- 微服务不再强调传统SOA架构里面比较重的ESB企业服务总线
- 微服务强调每个微服务都有自己独立的运行空间,包括数据库资源,互相之间并无影响
- 微服务架构本身来源于互联网的思路,因此组件对外发布的服务强调了采用HTTP Rest API的方式来进行
- 微服务的切分粒度会更小
微服务架构是 SOA 架构思想的一种扩展,更加强调服务个体的独立性、拆分粒度更小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号