ES核心概念、基本操作及SpringBoot集成
ES全称ElasticSearch,是一种分布式全文检索引擎,用于全文搜索、分析。近乎实时的存储及检索效率,可以在上百台服务器上运行处理PB级数据的扩展性都让ES成为炙手可热的搜索引擎。除此外,ES通过简单的RESTful API屏蔽了Lucence的复杂语法,在使用上ES也变得简单易上手。
一、ES核心概念
1.1 ES和普通关系型数据库的映射关系

ES集群中可以包含多个索引(数据库),每个索引可以包含多个类型(表),每个文档(行)中又包含多个词(字段)。
当然上面的映射也只是为了易于理解,实际上两者并无关联。
1.2 ES的逻辑设计——倒排索引
详见: 为啥ElasticSearch搜索那么快?倒排索引又是啥?
1.3 ES集群
一个ES集群就是由一个或多个节点组织在一起,它们共同持整个的数据,并一起提供索引和搜索功能。一个集群有一个唯一的名字标识,这个名字默认是“elasticsearch”。这个名字是重要的,每个节点只能通过指定这个集群名字来加入这个集群。
1.4 ES的物理设计——分片
如果倒排索引是ES的逻辑设计,那么分片就是它的物理设计。ElasticSearch在后台把每个索引划分成多个分片,每片分片可以在集群中的不同服务器之间迁移。如果你创建索引,那么索引会至少有5个分片(primary shard ,又称为主分片)构成的,每一个主分片会有一个副本(replica shard,又称为复制分片),实际上一个分片就是一个Lucene索引。
1.4.1 怎么理解分片,或者说为啥要分片?
一个索引可以存储超出单个节点硬件限制的大量数据。比如一个索引需要1TB的空间,但是每个节点的物理存储最大才500M,那怎么存?显然这个索引放在哪个节点都是太大了,为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份叫做分片,这个索引的分片分散在不同的节点上,这样就能实现一个索引可以存储超出单个节点硬件限制的大量数据的目标,提供检索时则整个集群一起提供。
1.4.2 分片的好处是啥?
有两点:
(1)水平分割/扩展容量
(2)可进行分布式的、并行的操作,进而提高性能/吞吐量
1.4.3 怎么理解分片复制?
Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个原因:
1) 在分片/节点失败的情况下,提供了高可用性。因为此原因,复制分片一般不与原/主(original/primary)分片置于同一节点上。
2)扩展搜索量/吞吐量,因为搜素可以在所有的复制上并行运行。
1.4.4 节点和分片 如何工作?
一个集群至少有一个节点,而一个节点就是一个ElasticSearch进程。
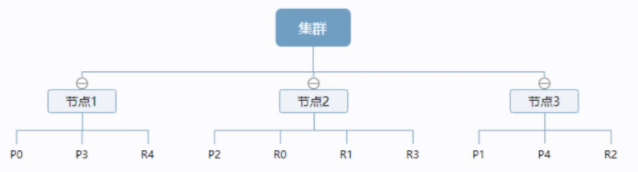
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失,保证了ES的可用性。
1.5 ES是如何实现 master 选举的?
首先,一个ES集群是由许多节点(Node)构成的,Node可以有不同的类型,通过以下配置,可以产生四种不同类型的Node:
conf/elasticsearch.yml:
node.master: true/false
node.data: true/false四种不同类型的Node是一个node.master和node.data的true/false的两两组合。当然还有其他类型的Node,比如IngestNode(用于数据预处理等),不在本文讨论范围内。
当node.master为true时,其表示这个node是一个master的候选节点,可以参与选举,因此也叫master-eligible。ES正常运行时只能有一个master(即leader),多于1个时会发生脑裂。
当node.data为true时,这个节点作为一个数据节点,会存储分配在该node上的shard的数据并负责这些shard的写入、查询等。
任何一个集群内的node都可以执行任何请求,其会负责将请求转发给对应的node进行处理,所以当node.master和node.data都为false时,这个节点可以作为一个类似proxy的节点,接受请求并进行转发、结果聚合等。

上图是一个ES集群的示意图,其中NodeA是当前集群的Master,NodeB和NodeC是Master的候选节点,其中NodeA和NodeB同时也是数据节点(DataNode),此外,NodeD是一个单纯的数据节点,Node_E是一个proxy节点。每个Node会跟其他所有Node建立连接。
节点发现
节点发现依赖以下配置:
conf/elasticsearch.yml:
discovery.zen.ping.unicast.hosts: [1.1.1.1, 1.1.1.2, 1.1.1.3]这个配置可以看作是,在本节点到每个hosts中的节点建立一条边,当整个集群所有的node形成一个联通图时,所有节点都可以知道集群中有哪些节点,不会形成孤岛。
Master选举
集群中可能会有多个master-eligible node,此时就要进行master选举,保证只有一个当选master。如果有多个node当选为master,则集群会出现脑裂,脑裂会破坏数据的一致性,导致集群行为不可控,产生各种非预期的影响。
1 master选举谁发起,什么时候发起?
master选举当然是由master-eligible(候选)节点发起,当一个master-eligible节点发现满足以下条件时发起选举:
- 该master-eligible节点的当前状态不是master。
- 该master-eligible节点通过ZenDiscovery模块的ping操作询问其已知的集群其他节点,没有任何节点连接到master。
- 包括本节点在内,当前已有超过minimum_master_nodes个节点没有连接到master。
总结一句话,即当一个节点发现包括自己在内的多数派的master-eligible节点认为集群没有master时,就可以发起master选举。
2 当需要选举master时,选举谁?
首先是选举谁的问题,如下面源码所示,选举的是排序后的第一个MasterCandidate(即master-eligible node)。
public MasterCandidate electMaster(Collection<MasterCandidate> candidates) {
assert hasEnoughCandidates(candidates);
List<MasterCandidate> sortedCandidates = new ArrayList<>(candidates);
sortedCandidates.sort(MasterCandidate::compare);
return sortedCandidates.get(0);
}那么是按照什么排序的?
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// we explicitly swap c1 and c2 here. the code expects "better" is lower in a sorted
// list, so if c2 has a higher cluster state version, it needs to come first.
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}如上面源码所示,先根据节点的clusterStateVersion比较,clusterStateVersion越大,优先级越高。clusterStateVersion相同时,进入compareNodes,其内部按照节点的Id比较(Id为节点第一次启动时随机生成)。
总结一下:
- 当clusterStateVersion越大,优先级越高。这是为了保证新Master拥有最新的clusterState(即集群的meta),避免已经commit的meta变更丢失。因为Master当选后,就会以这个版本的clusterState为基础进行更新。(一个例外是集群全部重启,所有节点都没有meta,需要先选出一个master,然后master再通过持久化的数据进行meta恢复,再进行meta同步)。
- 当clusterStateVersion相同时,节点的Id越小,优先级越高。即总是倾向于选择Id小的Node,这个Id是节点第一次启动时生成的一个随机字符串。之所以这么设计,应该是为了让选举结果尽可能稳定,不要出现都想当master而选不出来的情况。
3 什么时候选举成功?
当一个master-eligible node(我们假设为Node_A)发起一次选举时,它会按照上述排序策略选出一个它认为的master。
- 假设Node_A选Node_B当Master:
Node_A会向Node_B发送join请求,那么此时:
(1) 如果Node_B已经成为Master,Node_B就会把Node_A加入到集群中,然后发布最新的cluster_state, 最新的cluster_state就会包含Node_A的信息。相当于一次正常情况的新节点加入。对于Node_A,等新的cluster_state发布到Node_A的时候,Node_A也就完成join了。
(2) 如果Node_B在竞选Master,那么Node_B会把这次join当作一张选票。对于这种情况,Node_A会等待一段时间,看Node_B是否能成为真正的Master,直到超时或者有别的Master选成功。
(3) 如果Node_B认为自己不是Master(现在不是,将来也选不上),那么Node_B会拒绝这次join。对于这种情况,Node_A会开启下一轮选举。
- 假设Node_A选自己当Master:
此时NodeA会等别的node来join,即等待别的node的选票,当收集到超过半数的选票时,认为自己成为master,然后变更cluster_state中的master node为自己,并向集群发布这一消息。
按照上述流程,我们描述一个简单的场景来帮助大家理解:
假如集群中有3个master-eligible node,分别为Node_A、 Node_B、 Node_C, 选举优先级也分别为Node_A、Node_B、Node_C。三个node都认为当前没有master,于是都各自发起选举,选举结果都为Node_A(因为选举时按照优先级排序,如上文所述)。于是Node_A开始等join(选票),Node_B、Node_C都向Node_A发送join,当Node_A接收到一次join时,加上它自己的一票,就获得了两票了(超过半数),于是Node_A成为Master。此时cluster_state(集群状态)中包含两个节点,当Node_A再收到另一个节点的join时,cluster_state包含全部三个节点。
4 选举怎么保证不脑裂?
过半机制就可以避免脑裂问题的产生。
ElasticSearch通过discovery.zen.minimum_master_nodes参数配置可以解决脑裂问题。
ElasticSearch解决脑裂问题跟Zookeeper原理一样,都是过半机制。只要集群中超过半数节点投票就可以选出master。
基本原则还是多数派的策略,如果必须得到多数派的认可才能成为Master,那么显然不可能有两个Master都得到多数派的认可。
上述流程中,master候选人需要等待多数派节点进行join后才能真正成为master,就是为了保证这个master得到了多数派的认可。但是我这里想说的是,上述流程在绝大部份场景下没问题,听上去也非常合理,但是却是有bug的。
因为上述流程并没有限制在选举过程中,一个Node只能投一票,那么什么场景下会投两票呢?比如NodeB投NodeA一票,但是NodeA迟迟不成为Master,NodeB等不及了发起了下一轮选主,这时候发现集群里多了个Node0,Node0优先级比NodeA还高,那NodeB肯定就改投Node0了。假设Node0和NodeA都处在等选票的环节,那显然这时候NodeB其实发挥了两票的作用,而且投给了不同的人。
那么这种问题应该怎么解决呢,比如raft算法中就引入了选举周期(term)的概念,保证了每个选举周期中每个成员只能投一票,如果需要再投就会进入下一个选举周期,term+1。假如最后出现两个节点都认为自己是master,那么肯定有一个term要大于另一个的term,而且因为两个term都收集到了多数派的选票,所以多数节点的term是较大的那个,保证了term小的master不可能commit任何状态变更(commit需要多数派节点先持久化日志成功,由于有term检测,不可能达到多数派持久化条件)。这就保证了集群的状态变更总是一致的。
而ES目前(6.2版本)并没有解决这个问题,构造类似场景的测试case可以看到会选出两个master,两个node都认为自己是master,向全集群发布状态变更,这个发布也是两阶段的,先保证多数派节点“接受”这次变更,然后再要求全部节点commit这次变更。很不幸,目前两个master可能都完成第一个阶段,进入commit阶段,导致节点间状态出现不一致,而在raft中这是不可能的。那么为什么都能完成第一个阶段呢,因为第一个阶段ES只是将新的cluster_state做简单的检查后放入内存队列,如果当前cluster_state的master为空,不会对新的clusterstate中的master做检查,即在接受了NodeA成为master的cluster_state后(还未commit),还可以继续接受NodeB成为master的cluster_state。这就使NodeA和NodeB都能达到commit条件,发起commit命令,从而将集群状态引向不一致。当然,这种脑裂很快会自动恢复,因为不一致发生后某个master再次发布cluster_state时就会发现无法达到多数派条件,或者是发现它的follower并不构成多数派而自动降级为candidate等。
这里要表达的是,ES的ZenDiscovery模块与成熟的一致性方案相比,在某些特殊场景下存在缺陷,下一篇文章讲ES的meta变更流程时也会分析其他的ES无法满足一致性的场景。
1.6 Elestricsearch 写入流程

整体上看,Client 向 ES 发送写请求,es 接收数据,写入磁盘文件,返回响应给 Client 写入成功,这样就完成了。
然后拉近看一下,看看内部都做了什么工作:

-
客户端选择一个 node 发送请求过去,这个 node 就是
coordinating node(协调节点)。 -
coordinating node对 document 进行路由,将请求转发给对应的 node(有 primary shard)。 -
实际的 node 上的
primary shard处理请求,然后将数据同步到replica node。 -
coordinating node如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
1.7 Elestricsearch 读取流程
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
-
客户端发送请求到任意一个 node,成为
coordinate node。 -
coordinate node对doc id进行哈希路由,将请求转发到对应的 node,此时会使用round-robin随机轮询算法,在primary shard以及其所有 replica 中随机选择一个,让读请求负载均衡。 -
接收请求的 node 返回 document 给
coordinate node。 -
coordinate node返回 document 给客户端。
1.8 Elestricsearch 搜索数据过程
ES不仅能根据doc id查询,它最强大的是做全文检索,就是比如根据某个关键词搜索数据:
-
客户端发送请求到一个
coordinate node。 -
协调节点将搜索请求转发到所有的 shard 对应的
primary shard或replica shard,都可以。 -
query phase:每个 shard 将自己的搜索结果(其实就是一些
doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 -
fetch phase:接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
二、ES写的底层原理
2.1 真实写(新增)数据底层原理

- 先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
- 如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据
refresh到一个新的segment file中。但是此时数据不是直接进入segment file磁盘文件,而是先进入os cache。这个过程就是refresh。 - 每隔 1 秒钟,es 将 buffer 中的数据写入一个新的
segment file,每秒钟会产生一个新的磁盘文件segment file - 这个
segment file中就存储最近 1 秒内 buffer 中写入的数据。但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作。 - 如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
- 只要数据被输入
os cache中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了。 - 重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将
buffer数据写入一个又一个新的segment file中去,每次refresh完 buffer 清空,translog 保留。 - 随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发
commit操作。 - commit 操作发生第一步,就是将 buffer 中现有数据
refresh到os cache中去,清空 buffer。 - 然后,将一个
commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。 -
最后清空 现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。
-
这个 commit 操作叫做
flush。默认 30 分钟自动执行一次flush,但如果 translog 过大,也会触发flush。 -
flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache 中的数据 fsync 强刷到磁盘上去。
总结一下,数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。
每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
数据写入 segment file 之后,同时就建立好了倒排索引。
操作系统里面,磁盘文件其实都有一个东西,叫做 os cache,即操作系统缓存。就是说数据写入磁盘文件之前,会先进入 os cache,先进入操作系统级别的一个内存缓存中去。只要 buffer中的数据被 refresh 操作刷入 os cache中,这个数据就可以被搜索到了。
这也是为什么叫 es 是准实时的原因。
因为写入的数据 1 秒之后才能被看到。可以通过 es 的 restful api 或者 java api,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入 os cache中,让数据立马就可以被搜索到。
translog 日志文件的作用是什么?
执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件 translog 中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。
translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去。所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
es 丢数据的问题?
其实 es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的数据丢失。
2.2 删除/更新数据底层原理
- 如果是删除操作,commit 的时候会生成一个
.del文件,里面将某个 doc 标识为deleted状态,那么搜索的时候根据.del文件就知道这个 doc 是否被删除了。 - 如果是更新操作,就是将原来的 doc 标识为
deleted状态,然后新写入一条数据。 - buffer 每 refresh 一次,就会产生一个
segment file,所以默认情况下是 1 秒钟一个segment file,这样下来segment file会越来越多 - 此时会定期执行 merge。每次 merge 的时候,会将多个
segment file合并成一个 - 同时这里会将标识为
deleted的 doc 给物理删除掉,然后将新的segment file写入磁盘 - 这里会写一个
commit point,标识所有新的segment file,然后打开segment file供搜索使用,同时删除旧的segment file。
三、ES操作准备
这里演示采用windows版的ES,结合Kibana、KI分词及Head插件进行操作。Kibana可以理解成是ES的命令控制台、Head可以理解成Navicat可视化工具、IK则是分词插件。这些安装配置等环境准备工作不详细说明。若不想自己安装了也可以使用我的腾讯云服务器上部署的ES服务,IP:49.234.28.149 。另外附上ES各版本相关工具合集下载地址:下载中心 - Elastic 中文社区 。
3.1 Head插件界面

3.2 Kibana界面

3.3 IK分词器
ik 分词器有两种分词模式:ik_max_word 和 ik_smart 模式。
- ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、
华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。


四、ES基本操作
ES数据的curd操作是遵循RESTful风格的:

4.1 添加数据

可以通过head查看:

可以看到已经正常新增数据到对应的索引下。
4.2 获取数据

4.3 更新数据

4.4 按条件查询

五、SpringBoot与ES集成
实例代码下载地址: GitHub - ImOk520/myspringcloud
5.1 引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch}</version>
</dependency>5.2 配置ES客户端
@Configuration
public class EsConfig {
@Bean
public RestHighLevelClient initRHLC(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200)
)
);
return client;
}
}5.3 代码实例
@Slf4j
@RequestMapping("/es")
@RestController
public class EsController {
@Autowired
// @Qualifier("restHighLevelClient")
private RestHighLevelClient client;
@ApiOperation("创建索引")
@PostMapping("/createIndex")
public void createIndex() throws IOException {
// 1.创建索引请求
CreateIndexRequest request = new CreateIndexRequest("index-2");
// 2.客户端执行请求
CreateIndexResponse response = client
.indices()
.create(request, RequestOptions.DEFAULT);
Console.log(response);
}
@ApiOperation("获取索引")
@PostMapping("/getIndex")
public boolean getIndex() throws IOException {
// 1.创建索引请求
GetIndexRequest request = new GetIndexRequest("index-2");
// 2.客户端执行请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
GetIndexResponse getIndexResponse = client.indices().get(request, RequestOptions.DEFAULT);
System.out.println("[getIndexResponse:]" + getIndexResponse);
return exists;
}
@ApiOperation("删除索引")
@PostMapping("/delIndex")
public AcknowledgedResponse delIndex() throws IOException {
// 1.创建索引请求
DeleteIndexRequest request = new DeleteIndexRequest("index-2");
// 2.客户端执行请求
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
return delete;
}
@ApiOperation("添加文档")
@PostMapping("/addDoc")
public IndexResponse addDoc() throws IOException {
// 1.创建文档信息
B b = new B("鲁智深", 18);
// 2.创建请求
IndexRequest request = new IndexRequest("index-2");
request.id("1");
request.timeout("1s");
request.source(JSONUtil.toJsonStr(b), XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
return indexResponse;
}
@ApiOperation("获取文档")
@PostMapping("/getDoc")
public String getDoc() throws IOException {
// 1.创建请求
GetRequest request = new GetRequest("index-2", "1");
// 2.客户端执行请求
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
return documentFields.getSourceAsString();
}
@ApiOperation("更新文档")
@PostMapping("/updateDoc")
public RestStatus updateDoc() throws IOException {
B b = new B("鲁智深", 19);
UpdateRequest request = new UpdateRequest("index-2", "1");
request.doc(JSONUtil.toJsonStr(b), XContentType.JSON);
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
return updateResponse.status();
}
@ApiOperation("删除文档")
@PostMapping("/delDoc")
public RestStatus delDoc() throws IOException {
DeleteRequest request = new DeleteRequest("index-2", "1");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
return deleteResponse.status();
}
@ApiOperation("批量添加文档")
@PostMapping("/batchAddDoc")
public String batchAddDoc() throws IOException {
List<B> bList = new ArrayList<B>();
bList.add(new B("林冲", 20));
bList.add(new B("武松", 21));
bList.add(new B("扈三娘", 18));
bList.add(new B("张青", 22));
bList.add(new B("孙二娘", 18));
bList.add(new B("王英", 30));
bList.add(new B("花荣", 20));
BulkRequest bulkRequest = new BulkRequest();
for (int i = 0; i < bList.size(); i++) {
bulkRequest.add(
new IndexRequest("index-2").id("" + (i + 1)).source(JSONUtil.toJsonStr(bList.get(i)), XContentType.JSON)
);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return bulkResponse.buildFailureMessage();
}
@ApiOperation("按条件查询文档")
@PostMapping("/searchDoc")
public String searchDoc() throws IOException {
SearchRequest searchRequest = new SearchRequest("index-2");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("", 20);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout();
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
log.info(JSONUtil.toJsonStr(searchResponse.getHits()));
for (SearchHit hit : searchResponse.getHits()) {
System.out.println(hit.getSourceAsMap());
System.out.println("============================");
System.out.println(hit.getSourceAsString());
}
return JSONUtil.toJsonStr(searchResponse.getHits());
}
@ApiOperation("将爬虫数据存入ES")
@PostMapping("/saveHtmlDoc")
public boolean saveHtmlDoc(String keyword, String indexName) throws IOException {
List<Good> goods = HtmlParseUtil.parseJD(keyword);
// 商品批量入ES
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout(TimeValue.MAX_VALUE);
for (int i = 0; i < goods.size(); i++) {
int i1 = RandomUtil.randomInt(1, 100000000);
bulkRequest.add(
new IndexRequest(indexName).id("" + i1).source(JSONUtil.toJsonStr(goods.get(i)), XContentType.JSON)
);
}
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return response.hasFailures();
}
@ApiOperation("搜索ES中的爬虫数据")
@GetMapping("/searchHtmlDoc")
public List<Map<String, Object>> searchHtmlDoc(String keyword, int pageIndex, int pageSize, String indexName) throws IOException {
SearchRequest request = new SearchRequest(indexName);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.from(pageIndex);
sourceBuilder.size(pageSize);
// 精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(TimeValue.MAX_VALUE);
// 高亮处理
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("name");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
request.source(sourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = search.getHits().getHits();
ArrayList<Map<String, Object>> list = new ArrayList<Map<String, Object>>();
for (SearchHit hit : hits) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField name = highlightFields.get("name");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
if (name != null) {
Text[] fragments = name.fragments();
String result_name = "";
for (Text text : fragments) {
result_name += text;
}
sourceAsMap.put("name", result_name);
}
list.add(sourceAsMap);
}
return list;
}
}上面集成了一下jsoup网页爬虫工具:
@Slf4j
@Component
public class HtmlParseUtil {
public static List<Good> parseJD(String keyword) throws IOException {
String url = "https://search.jd.com/Search?keyword=" + keyword;
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
Elements elements = element.getElementsByTag("li");
ArrayList<Good> goods = new ArrayList<Good>();
for (Element ele : elements) {
String img = ele.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = ele.getElementsByClass("p-price").eq(0).text();
String name = ele.getElementsByClass("p-name").eq(0).text();
System.out.println(img);
System.out.println(price);
System.out.println(name);
Good good = new Good();
good.setImg(img);
good.setName(name);
good.setPrice(price);
goods.add(good);
}
return goods;
}
}
可以看到爬取的网页数据正常保存到ES中:

再检索查询下:

可以看到正常获取。
六、ES调优
6.1、设计阶段调优
1、根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
2、使用别名进行索引管理;
3、每天凌晨定时对索引做 force_merge 操作,以释放空间;
4、采取冷热分离,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink 操作,缩减存储;
5、采取 curator 进行索引的生命周期管理;
6、仅针对需要分词的字段,合理的设置分词器;
7、Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等
6.2、写入调优
1、写入前副本数设置为 0;
2、写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
3、写入过程中:采取 bulk 批量写入;
4、写入后恢复副本数和刷新间隔;
5、尽量使用自动生成的 id。
6.3、查询调优
1、禁用 wildcard;
2、禁用批量 terms(成百上千的场景);
3、充分利用倒排索引机制,能 keyword 类型尽量 keyword;
4、数据量大时候,可以先基于时间敲定索引再检索;
5、设置合理的路由机制。
6.4、其他调优
部署调优,业务调优等。
补充一、说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段
如实结合自己的实践场景回答即可。
比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日
递增 20+,索引:10 分片,每日递增 1 亿+数据,
每个通道每天索引大小控制:150GB 之内。
补充二、elasticsearch 索引数据多了怎么办?
面试官:想了解大数据量的运维能力。
解答:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,
这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户
检索或者其他业务受到影响。
1 动态索引层面
基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索
引的模板格式为:blog_index_时间戳的形式,每天递增数据。
这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线 2 的
32 次幂-1,索引存储达到了 TB+甚至更大。
一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
2 存储层面
冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩操作,
节省存储空间和检索效率。
3 部署层面
一旦之前没有规划,这里就属于应急策略。
结合 ES 自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注
意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增的。
补充三、Elasticsearch对大数据量(上亿量级)聚合如何实现?
Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
hyperloglog是用来近似统计不重复数据次数(cardinality count)的一种算法。主要应用于在一定误差允许范围内,进行去重计数。比如,近似统计网站日活用户数(非计算精确指标,只是为了监控流量趋势,提供背压标准)。cardinality 度量是一个近似算法。 它是基于 HyperLogLog++ (HLL)算法的。 HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。
去重计数可以通过其他方案来实现,比如hashmap,b树,bitmap,但上述方法都有一个缺点,内存消耗会随数据规模线性增长,以bitmap为例,如果要统计1亿个数据的基数值,大约需要内存: 100000000/8/1024/1024 ≈ 12M
而redis中实现的HyperLogLog,只需要12K内存,在标准误差0.81%的前提下,能够统计2^64 个数据。
补充四、在并发情况下,Elasticsearch如果保证读写一致?
- 可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
- 另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
- 对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号