代码重构,高效编码,写出好代码是有套路的!
重构的方法往往是零散的,大家在记忆时也是零散的,不系统。代码怎么写更好,你肯定能说出几点来,但还不够系统。
这里梳理记录一些重构方法与案例,意义在于系统的梳理后可以在平时写代码时做参照,写出更好的代码。
你想想每次重构的时候都能在这篇文章里找到对应的套路那该多爽。知道的套路多了,自然能写出更好的代码,毕竟“套路得人心”嘛。
所以本文刻意追求广而全,也将不断补充更新相关案例,可以关注或收藏,不时翻出来温故下。
一、开发界的墨菲定律
下面的或许我们都经历过:
- 你写的bug,迟早会被后面接收的程序员发现
- 如果你对你的代码没信心觉得有可能出错,往往就真的出错了
- 实际开发周期总是比你预计的长
- 用户需求永远没有表面看起来那么简单
任何事情虽然发生大的概率很低,但哪怕只有0.0000000000000000000001%的概率,它也终有一天会发生。
出来混迟早是要还的,技术上的债尽量少欠一点。要做到就需要平时写代码时知道一些通用且科学的方法套路,积累到一定程度,代码质量也将越来越高且优雅。
二、坏代码有哪些?对应的Refactoring?
有哪些常见的坏代码?
- 神秘命名
- 代码重复
- 过长方法
- 过长参数列表
- 全局数据
- 可变数据
- 过大的类
- 注释
- 冗余
.....

三、可读性
实际上开发过程中80%的时间是在读代码,可能是读自己的也可能是读别人的;只有20%是在写代码, 代码的可读性直接影响效率和准确性。
可读性差:
![]()
优化:
![]()
四、关于命名
4.1、选择专业的词
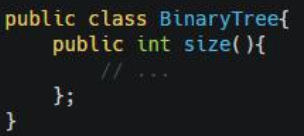
这里的size()若用hight()或者numNodes()替换会更好。
4.2、用具体的名字代替抽象的名字
若有一个方法用于检测服务示范可以监听某个给定的TCP/IP端口。
不好的:
![]()
优化:
![]()
4.3、见名知意
给名字附加更多的信息,就可以做到见名知意。
一个名字就是一个小小的注释,可以给名字附加上有意义的前后缀,例如:
(1)定义一个16进制字符串
(2)给时间加上单位

4.4、名字尽量不缩写
关于缩写,遵循团队新成员是否能理解这个名字的含义。
例如把类命名为BEManager而不是BackEndManager,新来的团队成员就可能不知道含义了,这种需要避免。
但是那种约定俗成的缩写,大部分人都一致知道的除外,比如:
- 专业术语的缩写
- addr、msg、btn、str、pm、am等
4.5、范围类命名
![]()
- 用first和last表示包含的范围
- begin和end表示包含、排除的范围
4.6、布尔值命名
1、确保返回true和false的意义明确
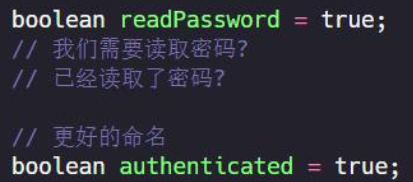
2、可以加上is、has、can、should
![]()
五、关于注释
实际上开发过程中80%的时间是在读代码,可能是自己的也可能是别人的;只有20%是在写代码,
5.1、不该注释的不注释
(1)不要为了注释而注释
下面的注释完全没必要:

(2)不给不好的名字加注释
为啥?因为名字不好那就要先取个好的名字,好的名字本身就是注释,不需要再注释。这又回到了前面命名章节里的提到的见名知意。
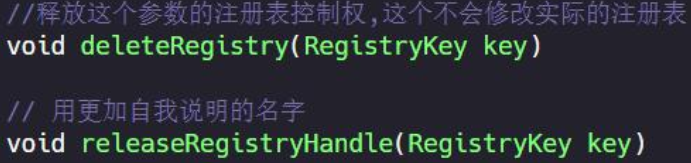
5.2、注释记录的是你的思想

- 加入“导演评论”
- 为代码中存在的缺陷说明清楚
- 给常量加注释
5.3、 站在读者角度写注释
(1)为什么这样做

(2)公布代码陷阱

5.4、言简意赅,注意排版
(1)言简意赅、保持紧凑
(2)语义清晰具体

好的正面例子:
![]()
六、条件判断优化
6.1、变化值在左更易读
不好:
![]()
好:
![]()
6.2、if/else 语句的顺序
- 尽量改写成卫语句
- 先处理正逻辑的情况
- 先处理简单的情况
- 先处理有趣或简单的情况
- 简单的优先使用三目运算
可以调整顺序,让程序更高效。例如:如果用户是会员,并且第一次登陆时,需要发一条通知的短信。代码很可能直接这样写:
if(isUserVip && isFirstLogin){
sendMsg();
}
假设总共有5个请求进来,isUserVip通过的有3个请求,isFirstLogin通过的有1个请求。
那么以上代码,isUserVip执行的次数为5次,isFirstLogin执行的次数也是3次。
如果调整一下isUserVip和isFirstLogin的顺序呢?
if(isFirstLogin && isUserVip ){
sendMsg();
}
那么isFirstLogin执行的次数是5次,isUserVip执行的次数是1次。
假如isUserVip和isFirstLogin的复杂度或者耗时一样,那么调换一下顺序,已经节省了2次运算。
七、循环优化
7.1、提前返回减少嵌套
实际就是优先使用卫语句。
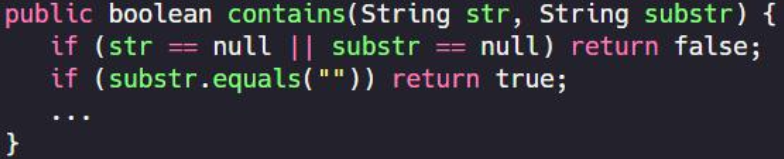
八、删除不必要的变量
8.1、移除低价值变量
![]()
上面第二句的now这个变量价值较低,可以直接移除。
8.2、减少中间结果变量
这里indexToRemove是不需要的。
不好的:

好的:

8.3、减少控制变量
不好的:

好的:

九、重复代码——提炼函数
提炼函数:将重复的代码片段提取出来,IDEA内置了该重构功能。

十、方法太简单——内联函数
内联函数:若一个方法逻辑太简单,则直接把其中的代码移到调用处。

十一、复杂表达式——提炼变量
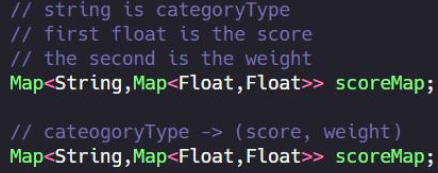
提炼变量:如果表达式复杂,难以阅读,可以通过合理拆分, 引入局部变量,使代码易读。


十二、简单表达式——内联变量
内联变量:和提炼变量正好相反,若表达式很简单,就没必要再提取成局部变量。


十三、接口适应性不强——改变函数声明
修改参数:尽量是传参变成适用性更好的形式。
![]()
这里若只是需要电话号码,但却传了个person对象,违背了迪米特原则,也就是说每次调用这个方法还要引入一个Person类,显然不合适,修改下:
![]()
这样适用性更好。
十四、参数列表过长——引入参数对象
上面的改变函数声明是不让传对象,适用于参数个数少(少于3个)的情况,若参数个数较多,可以封装一个参数类。
![]()
封装后:
![]()
十五、基本类型偏执——以对象取代基本类型

十六、以查询替代临时变量(replace temp with query)
临时变量提到单独的查询方法中,提升可读性和复用性。

refactoring:

十七、过大的类 —— 提炼类
类要注意单一原则,一个类责任太多就要提炼出去。

refactoring:

十八、重复造轮子——api调用取代内联代码
熟悉常用的api,避免重复造轮子。

refactoring:
![]()
十九、创建不必要的对象
下面两种情况下,不需要创建新的对象,即没必要new:
- 如果一个变量,后面的逻辑判断,一定会被赋值;
- 只是一个字符串变量(原因参考 https://blog.csdn.net/weixin_41231928/article/details)
反例:
String s = new String ("你大爷"); // 这是创建了两个对象正例:
String s= "你大爷”;二十、初始化集合时,不指定容量
假设你的map要存储的元素个数是15个左右,最优写法如下:
//initialCapacity = 15/0.75+1=21
Map map = new HashMap(21);
又因为hashMap的容量跟2的幂有关,所以可以取32的容量
Map map = new HashMap(32);二十一、catch后没打印出具体的exception
反例:
try{
// do something
}catch(Exception e){
log.info("有异常!");
}正例:
try{
// do something
}catch(Exception e){
log.info("有异常了:",e); //把exception打印出来
}反例中,并没有把exception出来,到时候排查问题就不好查了啦,到底是SQl写错的异常还是IO异常,还是其他呢?打印出异常好排查问题。
并且, catch住异常后,尽量不要使用e.printStackTrace(),而是使用log打印。
二十二、打印日志的时候,对象没有覆盖Object的toString的方法
publick Response dealWithRequest(Request request){
log.info("请求参数是:".request.toString)
}打印日志的时候,若对象没有覆盖Object的toString的方法,那只会打印出类名:
请求参数是:local.Request@49476842因此在打印对象前先确认这个对象是否重写了toString()方法。
二十三、重复查询
前面已经查到的数据,在后面的方法也用到的话,可以透传,减少方法调用/查表。
反例:
public Response dealRequest(Request request){
UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);
if(Objects.isNull(request)){
return ;
}
insertUserVip(request.getUserId);
}
private int insertUserVip(String userId){
//又查了一次
UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);
//插入用户vip流水
insertUserVipFlow(userInfo);
....
}正例:
public Response dealRequest(Request request){
UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);
if(Objects.isNull(request)){
return ;
}
insertUserVip(userInfo);
}
private int insertUserVip(UserInfo userInfo){
//插入用户vip流水
insertUserVipFlow(userInfo);
....
}二十四、使用魔法值
魔法值,应该要用enum枚举或常量代替。
反例:
if("0".equals(userInfo.getVipFlag)){
//非会员,提示去开通会员
tipOpenVip(userInfo);
}else if("1".equals(userInfo.getVipFlag)){
//会员,加勋章返回
addMedal(userInfo);
}正例:
if(UserVipEnum.NOT_VIP.getCode.equals(userInfo.getVipFlag)){
//非会员,提示去开通会员
tipOpenVip(userInfo);
}else if(UserVipEnum.VIP.getCode.equals(userInfo.getVipFlag)){
//会员,加勋章返回
addMedal(userInfo);
}
public enum UserVipEnum {
NOT_VIP("0","非会员"),
VIP("1","会员"), ;
private String code;
private String desc;
UserVipEnum(String code, String desc) {
this.code = code;
this.desc = desc;
}
}二十五、值不变的变量不定义成静态变量
当成员变量值不会改变时,优先定义为静态常量。
因为如果定义为static,即类静态常量,在每个实例对象中,它只有一份副本。如果是成员变量,每个实例对象中,都各有一份副本。
反例:
public class Task {
private final long timeout = 10L;
...
}正例:
public class Task {
private static final long TIMEOUT = 10L;
...
}二十六、不考虑异步处理
通知类(如发邮件,有短信)的代码,建议异步处理。
添加通知类等不是非主要,可降级的接口时,应该静下心来考虑是否会影响主要流程,思考怎么处理最好。
二十七、工具类的方法不声明成静态方法
有些方法,与实例成员变量无关,或者与实例变量有关,但是实例变量值是不变的,就可以声明为静态方法。这一点,工具类用得很多。
反例:
public class BigDecimalUtils {
public BigDecimal ifNullSetZERO(BigDecimal in) {
return in != null ? in : BigDecimal.ZERO;
}
public BigDecimal sum(BigDecimal ...in){
BigDecimal result = BigDecimal.ZERO;
for (int i = 0; i < in.length; i++){
result = result.add(ifNullSetZERO(in[i]));
}
return result;
}
}正例:
public class BigDecimalUtils {
public static BigDecimal ifNullSetZERO(BigDecimal in) {
return in != null ? in : BigDecimal.ZERO;
}
public static BigDecimal sum(BigDecimal ...in){
BigDecimal result = BigDecimal.ZERO;
for (int i = 0; i < in.length; i++){
result = result.add(ifNullSetZERO(in[i]));
}
return result;
}
}工具类的方法使用static修饰,每次使用就无须创建对象。
二十八、用一个Exception捕捉所有可能的异常
反例:
public void test(){
try{
//…抛出 IOException 的代码调用
//…抛出 SQLException 的代码调用
}catch(Exception e){
//用基类 Exception 捕捉的所有可能的异常,如果多个层次都这样捕捉,会丢失原始异常的有效信息哦
log.info(“Exception in test,exception:{}”, e);
}
}正例:
public void test(){
try{
//…抛出 IOException 的代码调用
//…抛出 SQLException 的代码调用
}catch(IOException e){
//仅仅捕捉 IOException
log.info(“IOException in test,exception:{}”, e);
}catch(SQLException e){
//仅仅捕捉 SQLException
log.info(“SQLException in test,exception:{}”, e);
}
}二十九、随意创建对象占用堆内存
如果变量的初值一定会被覆盖,就没有必要给变量赋初值。
只是声明的话只会在栈内开辟内存,而初始化了后会在开辟堆内存。
反例:
List<UserInfo> userList = new ArrayList<>();
if (isAll) {
userList = userInfoDAO.queryAll();
} else {
userList = userInfoDAO.queryActive();
}正例:
List<UserInfo> userList ;
if (isAll) {
userList = userInfoDAO.queryAll();
} else {
userList = userInfoDAO.queryActive();
}三十、乱用Arrays.asList
30.1、基本类型不能作为 Arrays.asList方法的参数,否则会被当做一个参数。
public class ArrayAsListTest {
public static void main(String[] args) {
int[] array = {1, 2, 3};
List list = Arrays.asList(array);
System.out.println(list.size());
}
}
//运行结果
130.2、Arrays.asList 返回的 List 不支持增删操作。
public class ArrayAsListTest {
public static void main(String[] args) {
String[] array = {"1", "2", "3"};
List list = Arrays.asList(array);
list.add("5");
System.out.println(list.size());
}
}
// 运行结果
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at object.ArrayAsListTest.main(ArrayAsListTest.java:11)Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类ArrayList。内部类的ArrayList没有实现add方法。
30.3、对原始数组的修改会影响到Arrays.asLis的结果
public class ArrayAsListTest {
public static void main(String[] args) {
String[] arr = {"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
System.out.println("原始数组"+Arrays.toString(arr));
System.out.println("list数组" + list);
}
}
//运行结果
原始数组[1, 4, 3]
list数组[1, 4, 3]三十一、调用第三方接口,不考虑异常处理,安全性,超时重试
调用第三方服务,或者分布式远程服务的的话,需要考虑:
-
异常处理(比如调别人的接口,如果异常了,怎么处理,是重试还是当做失败)
-
超时(没法预估对方接口一般多久返回,一般设置个超时断开时间,以保护你的接口)
-
重试次数(接口调失败,需不需要重试,需要站在业务上角度思考这个问题)
三十二、没考虑接口幂等性
接口是需要考虑幂等性的,尤其抢红包、转账这些重要接口。最直观的业务场景,就是用户连着点两次,只能有点一次的效果。
一般幂等技术方案有这几种:
-
查询操作
-
唯一索引
-
token机制,防止重复提交
-
数据库的delete/update操作
-
乐观锁
-
悲观锁
-
Redis、zookeeper 分布式锁(以前抢红包需求,用了Redis分布式锁)
-
状态机幂等
三十三、循环体内 慎用异常
在Java开发中,经常使用try-catch进行错误捕获,但是try-catch语句对系统性能而言是非常糟糕的。虽然一次try-catch中,无法察觉到它对性能带来的损失,但是一旦try-catch语句被应用于循环或是遍历体内,就会给系统性能带来极大的伤害。
以下是一段将try-catch应用于循环体内的示例代码:
@Test
public void test11() {
long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
try {
a++;
}catch (Exception e){
e.printStackTrace();
}
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
} useTime:10下面是一段将try-catch移到循环体外的代码,那么性能就提升了将近一半。如下:
@Test
public void test(){
long start = System.currentTimeMillis();
int a = 0;
try {
for (int i=0;i<1000000000;i++){
a++;
}
}catch (Exception e){
e.printStackTrace();
}
long useTime = System.currentTimeMillis()-start;
System.out.println(useTime);
}useTime:6三十四、不使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度快。
其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢。
下面是一段使用局部变量进行计算的代码:
@Test
public void test11() {
long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
a++;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}useTime:5将局部变量替换为类的静态变量:
static int aa = 0;
@Test
public void test(){
long start = System.currentTimeMillis();
for (int i=0;i<1000000000;i++){
aa++;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}useTime:94通过上面两次的运行结果,可以看出来局部变量的访问速度远远高于类成员变量。
三十五、乘除法没有考虑使用 位运算 代替
在所有的运算中,位运算是最为高效的。因此,可以尝试使用位运算代替部分算术运算,来提高系统的运行速度。最典型的就是对于整数的乘除运算优化。
下面是一段使用算术运算的代码:
@Test
public void test11() {
long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
a*=2;
a/=2;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}useTime:1451将循环体中的乘除运算改为等价的位运算,代码如下:
@Test
public void test(){
long start = System.currentTimeMillis();
int aa = 0;
for (int i=0;i<1000000000;i++){
aa<<=1;
aa>>=1;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}useTime:10上两段代码执行了完全相同的功能,在每次循环中,都将整数乘以2,并除以2。但是运行结果耗时相差非常大,所以位运算的效率还是显而易见的。
三十六、复制数组未使用arrayCopy()
如果在应用程序中需要进行数组复制,应该使用这个JDK中提供arrayCopy(),而不是自己实现。
因为System.arraycopy()函数是native函数,通常native函数的性能要优于普通函数。仅出于性能考虑,在程序开发时,应尽可能调用native函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号